
Le « Calendrier de l’Avent » du Machine Learning Jour 9 : LOF dans Excel
Hier, nous avons travaillé avec Isolation Forest, qui est une méthode de détection d’anomalies.
Aujourd’hui, nous examinons un autre algorithme qui a le même objectif. Mais contrairement à Isolation Forest, c’est le cas pas construire des arbres.
C’est ce qu’on appelle LOF, ou Local Outlier Factor.
Les gens résument souvent LOF en une seule phrase : Ce point vit-il dans une région avec une densité plus faible que ses voisines ?
Cette phrase est en fait difficile à comprendre. J’ai lutté avec ça pendant longtemps.
Cependant, il y a une partie qui est immédiatement facile à comprendre :
et nous verrons que cela devient le point clé :
il y a une notion de voisins.
Et dès qu’on parle de voisins,
nous revenons naturellement à modèles basés sur la distance.
Nous allons expliquer cet algorithme en 3 étapes.
Pour garder les choses très simples, nous utiliserons à nouveau cet ensemble de données :
1, 2, 3, 9
Vous souvenez-vous que j’ai les droits d’auteur sur cet ensemble de données ? Nous avons fait Isolation Forest avec, et nous ferons à nouveau LOF avec. Et nous pouvons également comparer les deux résultats.

Tous les fichiers Excel sont disponibles via ce Lien Kofi. Votre soutien compte beaucoup pour moi. Le prix augmentera au cours du mois, afin que les premiers supporters bénéficient du meilleur rapport qualité-prix.

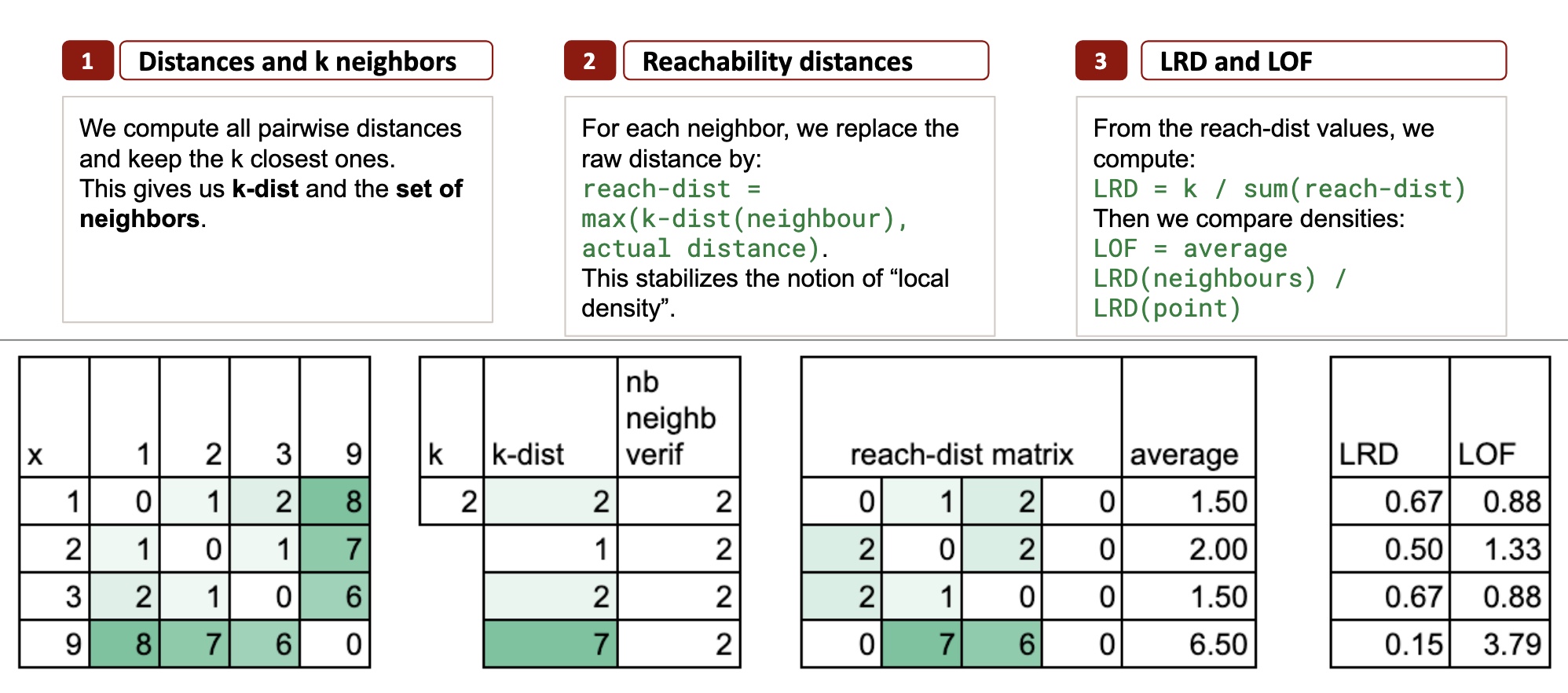
Étape 1 – k Voisins et k-distance
LOF commence par quelque chose d’extrêmement simple :
Regardez les distances entre les points.
Trouvez ensuite les k voisins les plus proches de chaque point.
Prenons k = 2juste pour garder les choses au minimum.
Voisins les plus proches pour chaque point
- Indiquer 1 → voisins : 2 et 3
- Indiquer 2 → voisins : 1 et 3
- Indiquer 3 → voisins : 2 et 1
- Indiquer 9 → voisins : 3 et 2
Nous voyons déjà émerger une structure claire :
- 1, 2 et 3 forment un cluster serré
- 9 vit seul, loin des autres
La k-distance : un rayon local
La k-distance est simplement la plus grande distance parmi les k voisins les plus proches.
Et c’est en fait le point clé.
Car ce seul chiffre vous dit quelque chose de très concret :
le rayon local autour du point.
Si la distance k est petite, le point se trouve dans une zone dense.
Si la distance k est grande, le point se trouve dans une zone clairsemée.
Avec cette seule mesure, vous avez déjà un premier signal d’« isolement ».
Ici, nous utilisons la notion de « k voisins les plus proches », qui nous rappelle bien sûr k-NN (le classificateur ou le régresseur).
Le contexte ici est différent, mais le calcul est exactement le même.
Et si tu penses à k-signifiene les mélangez pas :
le « k » dans k-signifie n’a rien à voir avec le « k » ici.
Le calcul de la distance k
Pour le point 1les deux voisins les plus proches sont 2 et 3 (distances 1 et 2), donc k-distance(1) = 2.
Pour le point 2les voisins sont 1 et 3 (tous deux à distance 1), donc k-distance(2) = 1.
Pour le point 3, les deux plus proches voisins sont 1 et 2 (distances 2 et 1), donc k-distance(3) = 2.
Pour le point 9les voisins sont 3 et 2 (6 et 7), donc k-distance(9) = 7. C’est énorme par rapport à tous les autres.
Dans Excel, nous pouvons créer une matrice de distance par paire pour obtenir la distance k pour chaque point.

Étape 2 – Distances d’accessibilité
Pour cette étape, je vais simplement définir ici les calculs et appliquer les formules dans Excel. Parce que, pour être honnête, je n’ai jamais réussi à trouver une manière véritablement intuitive d’expliquer les résultats.
Alors, qu’est-ce que la « distance d’accessibilité » ?
Pour un point p et un voisin o, on définit cette distance d’accessibilité comme :
atteindre-dist(p, o) = max(k-dist(o), distance(p, o))
Pourquoi prendre le maximum ?
Le but de la distance d’accessibilité est pour stabiliser la comparaison de densité.
Si le voisin o vit dans une région très dense (petite k-dist), alors nous ne voulons pas autoriser une distance irréaliste.
En particulier, pour le point 2 :
- Distance à 1 = 1, mais k-distance(1) = 2 → reach-dist(2, 1) = 2
- Distance à 3 = 1, mais k-distance(3) = 2 → reach-dist(2, 3) = 2
Les deux voisins forcent la distance d’accessibilité vers le haut.
Dans Excel, nous conserverons un format matriciel pour afficher les distances d’accessibilité : un point par rapport à tous les autres.

Distance d’accessibilité moyenne
Pour chaque point, nous pouvons maintenant calculer la valeur moyenne, qui nous dit : en moyenne, quelle distance dois-je parcourir pour atteindre mon quartier ?
Et maintenant, remarquez-vous quelque chose : le point 2 a une distance d’accessibilité moyenne plus grande que 1 et 3.
Ce n’est pas si intuitif pour moi !
Étape 3 – LRD et le score LOF
La dernière étape est une sorte de « normalisation » pour trouver un score d’anomalie.
Tout d’abord, nous définissons la LRD, Local Reachability Density, qui est simplement l’inverse de la distance moyenne d’accessibilité.
Et le score LOF final est calculé comme suit :

Ainsi, LOF compare la densité d’un point à la densité de ses voisins.
Interprétation:
- Si LRD(p) ≈ LRD (voisins), alors LOF ≈ 1
- Si LRD(p) est beaucoup plus petitpuis LOF >> 1. Donc p est dans une région clairsemée
- Si LRD(p) est beaucoup plus grand → LOF < 1. Donc p est dans une poche très dense.
J’ai aussi fait une version avec plus de développements, et des formules plus courtes.

Comprendre ce que signifie « anomalie » dans les modèles non supervisés
Dans apprentissage non superviséil n’y a pas de vérité terrain. Et c’est précisément là que les choses peuvent devenir délicates.
Nous n’avons pas d’étiquettes.
Nous n’avons pas la « bonne réponse ».
Nous n’avons que la structure des données.
Prenez ce petit échantillon :
1, 2, 3, 7, 8, 12
(J’ai aussi les droits d’auteur dessus.)
Si vous le regardez intuitivement, laquelle semble être une anomalie ?
Personnellement, je dirais 12.
Examinons maintenant les résultats. LOF dit que la valeur aberrante est 7.
(Et vous pouvez remarquer qu’avec k-distance, on dirait que c’est 12.)

Maintenant, nous pouvons comparer Forêt d’isolement et LOF côte à côte.
A gauche, avec l’ensemble de données 1, 2, 3, 9les deux méthodes concordent :
9 est clairement la valeur aberrante.
Isolation Forest lui donne la note la plus basse,
et LOF lui donne la valeur LOF la plus élevée.
Si on y regarde de plus près, pour Isolation Forest : 1, 2 et 3 n’ont aucune différence de score. Et LOF donne une note plus élevée de 2. C’est ce que nous avons déjà remarqué.
Avec l’ensemble de données 1, 2, 3, 7, 8, 12l’histoire change.
- Forêt d’isolement pointe vers 12 comme le point le plus isolé.
Cela correspond à l’intuition : 12, c’est loin d’être tout le monde. - LOFmet cependant en évidence 7 plutôt.

Alors qui a raison ?
C’est difficile à dire.
En pratique, il faut d’abord se mettre d’accord avec les équipes métiers sur ce que signifie réellement « anomalie » dans le contexte de nos données.
Parce que dans l’apprentissage non supervisé, il n’y a pas de vérité unique.
Il n’existe que la définition d’« anomalie » que chaque algorithme utilise.
C’est pourquoi il est extrêmement important de comprendre
comment fonctionne l’algorithmeet quel type d’anomalies il est conçu pour détecter.
Ce n’est qu’alors que vous pourrez décider si LOF, ou k-distance, ou Isolation Forest est le bon choix pour votre situation spécifique.
Et c’est tout le message de l’apprentissage non supervisé :
Différents algorithmes examinent les données différemment.
Il n’y a pas de « véritable » cas aberrant.
Seule la définition de ce que signifie une valeur aberrante pour chaque modèle.
C’est pourquoi comprendre le fonctionnement de l’algorithme
est plus important que la partition finale qu’il produit.
LOF n’est pas vraiment un modèle
Il y a encore un point à clarifier à propos du LOF.
LOF n’apprend pas un modèle au sens habituel du terme.
Par exemple
- k-means apprend et stocke les centroïdes (moyennes)
- GMM apprend et stocke les moyennes et les écarts
- arbres de décision, apprendre et stocker les règles
Tous ces éléments produisent une fonction que vous pouvez appliquer à de nouvelles données.
Et LOF ne produit pas une telle fonction. Cela dépend entièrement de la structure du quartier à l’intérieur de l’ensemble de données. Si vous ajoutez ou supprimez un point, le voisinage change, les densités changent et les valeurs LOF doivent être recalculées.
Même si vous conservez l’intégralité de l’ensemble de données, comme le fait k-NN, vous ne pouvez toujours pas appliquer LOF en toute sécurité aux nouvelles entrées. La définition elle-même ne généralise pas.
Conclusion
LOF et Isolation Forest détectent tous deux les anomalies, mais ils examinent les données sous des angles complètement différents.
- k-distance capture la distance qu’un point doit parcourir pour trouver ses voisins.
- LOF compare les densités locales.
- Forêt d’isolement isole les points en utilisant des divisions aléatoires.
Et même sur des ensembles de données très simplesces méthodes peuvent être en désaccord.
Un algorithme peut signaler un point comme étant aberrant, tandis qu’un autre en met en évidence un complètement différent.
Et voici le message clé :
Dans l’apprentissage non supervisé, il n’y a pas de « véritable » valeur aberrante.
Chaque algorithme définit les anomalies selon sa propre logique.
C’est pourquoi comprendre comment une méthode qui fonctionne est plus importante que le nombre qu’elle produit.
Ce n’est qu’alors que vous pourrez choisir le bon algorithme pour la bonne situation et interpréter les résultats en toute confiance.


