

Assistants personnels et agents : un modèle pratique pour un chatbot sécurisé, multi-utilisateurs et auto-hébergé
comment j’ai construit une plate-forme auto-hébergée de bout en bout qui donne à chaque utilisateur un chatbot personnel et agent qui peut rechercher de manière autonome uniquement les fichiers auxquels l’utilisateur lui permet explicitement d’accéder.
En d’autres termes : un contrôle total, 100 % privé, tous les avantages de LLM sans les fuites de confidentialité, les coûts de jetons ou les dépendances externes.
Introduction
Au cours de la semaine dernière, je me suis mis au défi de construire quelque chose qui me trottait en tête depuis un moment :
Comment puis-je dynamiser un LLM avec mes données personnelles sans sacrifier la confidentialité au profit des grandes entreprises technologiques ?
Cela a conduit au défi de cette semaine :
Créez un chatbot agent équipé d’outils pour accéder aux notes personnelles d’un utilisateur en toute sécurité, sans compromettre la confidentialité.
Comme défi supplémentaire, je voulais que le système prenne en charge plusieurs utilisateurs. Pas un assistant partagé mais un agent privé pour chaque utilisateur où l’utilisateur a un contrôle total sur les fichiers que son agent peut lire et sur lesquels il peut raisonner.
Nous allons construire le système en procédant comme suit :
- Architecture
- Comment créer un agent et lui fournir des outils ?
- Flux 1 : Gestion des fichiers utilisateurs : Que se passe-t-il lorsque nous soumettons un fichier ?
- Flux 2 : Comment intégrer des documents et stocker des fichiers ?
- Flux 3 : Que se passe-t-il lorsque nous discutons avec notre assistant agent ?
- Démonstration
1) Architecture
J’ai défini trois « flux » principaux que le système doit permettre :
A) Gestion des fichiers utilisateurs
Les utilisateurs s’authentifient via le frontend, téléchargent ou suppriment des fichiers et attribuent chaque fichier à des groupes spécifiques qui déterminent quels agents d’utilisateurs peuvent y accéder.
B) Intégration et stockage de fichiers
Les fichiers téléchargés sont fragmentés, intégrés et stockés dans la base de données de manière à garantir que seules les utilisations autorisées peuvent récupérer ou rechercher ces intégrations.
C) Discuter
Un utilisateur discute avec son propre agent. L’agent est équipé d’outils, dont un outil de recherche vectorielle sémantiqueet ne peut rechercher que les documents auxquels l’utilisateur est autorisé à accéder.
Pour prendre en charge ces flux, le système est composé de six composants clés :
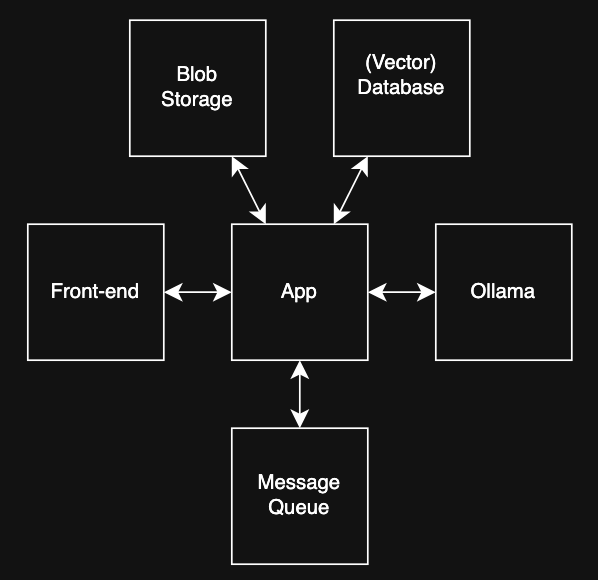
Application
Une application Python qui est le cœur du système. Il expose les points de terminaison de l’API pour le front-end et écoute les messages provenant de MessageQueue
L’extrémité avant
Normalement, j’utiliserais Angular mais pour ce prototype, j’ai opté pour Streamlit. C’était très rapide et facile à construire. Cette facilité d’utilisation avait bien sûr l’inconvénient de ne pas pouvoir faire tout ce que je voulais. Je prévois de remplacer ce composant par mon Angluar préféré, mais à mon avis, Streamlit était très agréable pour le prototypage.
Stockage des objets blob
Ce conteneur exécute Minio ; un système de stockage d’objets distribué open source et hautes performances. Certainement exagéré pour mon prototype mais il était très simple à utiliser et s’intègre bien à Python, donc je n’ai aucun regret.
Base de données (vecteur)
Postgres gère toutes les données relationnelles telles que les métadonnées des documents, les utilisateurs, les groupes d’utilisateurs et les morceaux de texte. De plus, Postgres propose une extension que j’utilise pour enregistrer des données vectorielles telles que les intégrations que nous souhaitons créer. C’est très pratique pour mon cas d’utilisation puisque je peux autoriser la recherche vectorielle sur une table, en joignant cette table à la table des utilisateurs, garantissant ainsi que chaque utilisateur ne peut voir que ses propres données.
Ollama
Ollama héberge deux modèles locaux : un pour intégrations et un pour chat. Les modèles sont assez légers mais peuvent être facilement mis à niveau, en fonction du matériel disponible.
File d’attente des messages
RabbitMQ rend le système réactif. Les utilisateurs n’ont pas besoin d’attendre que les fichiers volumineux soient fragmentés et intégrés. Au lieu de cela, je reviens immédiatement et traite l’intégration en arrière-plan. Cela me donne également une évolutivité horizontale : plusieurs travailleurs peuvent traiter des fichiers simultanément.
2) Construire un agent avec une boîte à outils
LangGraph facilite la définition d’un agent : quelles étapes il peut suivre, comment il doit raisonner et quel outil il est autorisé à utiliser. Cet agent peut alors inspecter de manière autonome les outils disponibles, lire leurs descriptions et décider si l’appel de l’un d’entre eux permettra de répondre à la question de l’utilisateur.
Le flux de travail est décrit sous forme de graphique. Pensez-y comme au modèle de comportement de l’agent. Dans ce prototype, le graphique est volontairement simple :
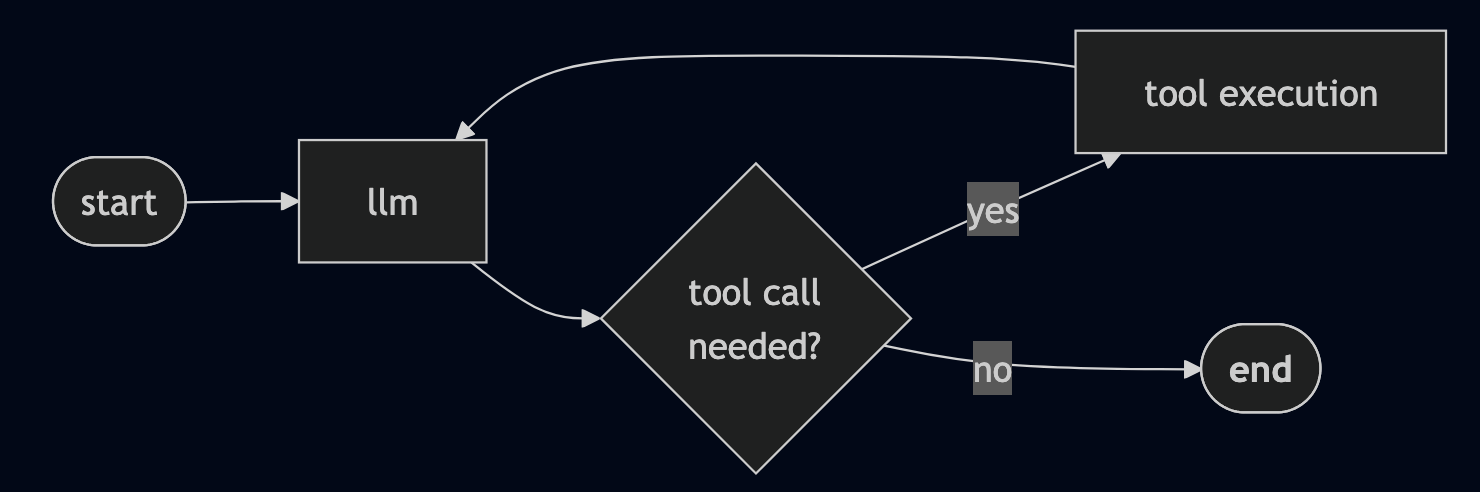
Le LLM vérifie quels outils sont disponibles et décide si un appel d’outil (comme la recherche vectorielle) est nécessaire. et Le graphique parcourt le nœud d’outil et revient au nœud LLM jusqu’à ce qu’aucun outil supplémentaire ne soit nécessaire et que l’agent dispose de suffisamment d’informations pour répondre.
3) Flux 1 : Soumettre un fichier
Cette partie décrit ce qui se passe lorsqu’un utilisateur soumet un ou plusieurs fichiers. Un utilisateur doit d’abord se connecter au front-end et recevoir un jeton utilisé pour authentifier les appels d’API.
Après cela, ils peuvent télécharger des fichiers et attribuer ces fichiers à un ou plusieurs groupes. Tout utilisateur de ces groupes sera autorisé à accéder au fichier via son agent.
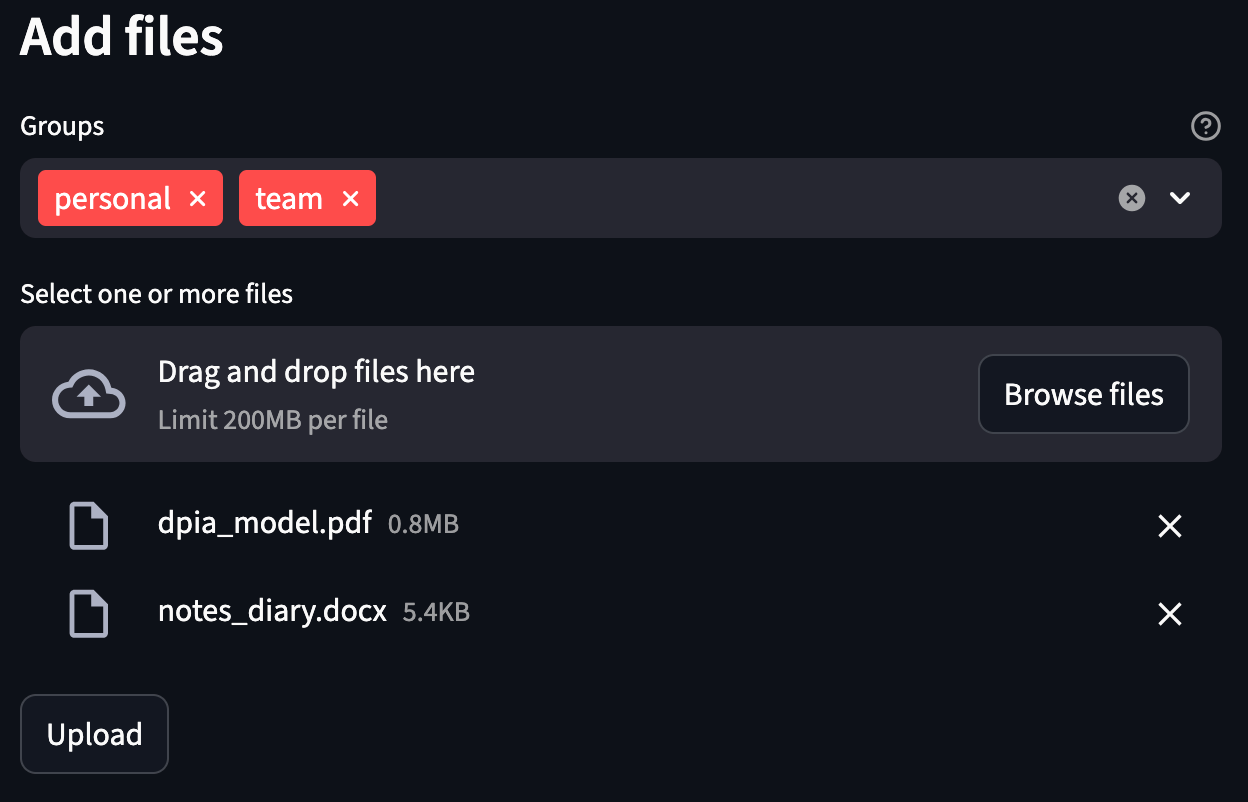
Dans la capture d’écran ci-dessus, l’utilisateur a sélectionné deux fichiers : un document PDF et un document Word, et les affecte à deux groupes. En coulisses, voici comment le système traite un téléchargement comme ceci :
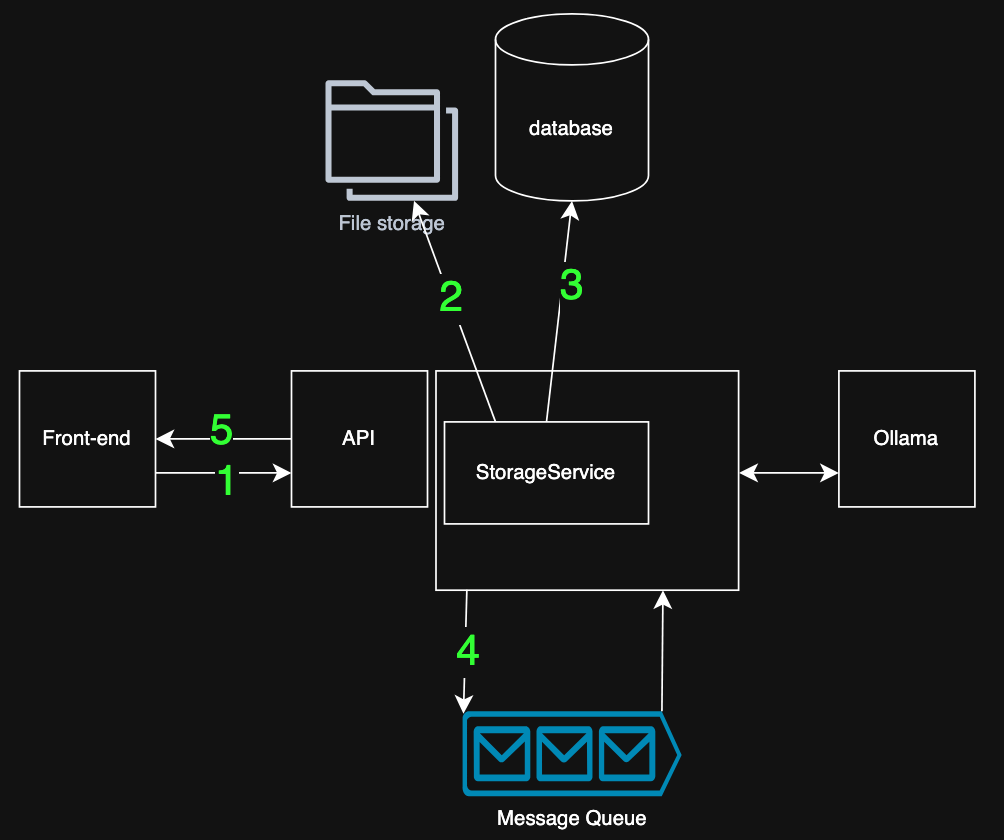
- Le fichier et les groupes sont envoyés à l’API, validant l’utilisateur avec le jeton.
- Le fichier est enregistré dans le stockage blob, renvoyant l’emplacement de stockage
- Les métadonnées et l’emplacement de stockage du fichier sont enregistrés dans la base de données, renvoyant le
file_id - Le
file_idest publié dans une file d’attente de messages - la demande est complétée ; les utilisateurs peuvent continuer à utiliser le front-end. Les processus lourds (blocage, intégration) se produisent plus tard en arrière-plan)
Ce flux garantit que l’expérience de téléchargement reste rapide et réactive, même pour les fichiers volumineux.
4) Flux 2 : Intégration et stockage de fichiers
Une fois qu’un document est soumis, l’étape suivante consiste à le rendre consultable. Pour ce faire, nous devons intégrer nos documents. Cela signifie que nous convertissons le texte du document en vecteurs numériques capables de capturer la signification sémantique.
Dans le flux précédent, nous avons soumis un message à la file d’attente. Ce message contient uniquement un file_id et est donc très petit. Cela signifie que le système reste rapide même lorsqu’un utilisateur télécharge des dizaines ou des centaines de fichiers.
La file d’attente des messages nous offre également deux avantages importants :
- il facilite la charge en traitant les documents un par un au lieu de tous en même temps
- il assure la pérennité de notre système en permettant une mise à l’échelle horizontale ; plusieurs travailleurs peuvent écouter la même file d’attente et traiter les fichiers en parallèle.
Voici ce qui se passe lorsque le travailleur d’intégration reçoit un message :
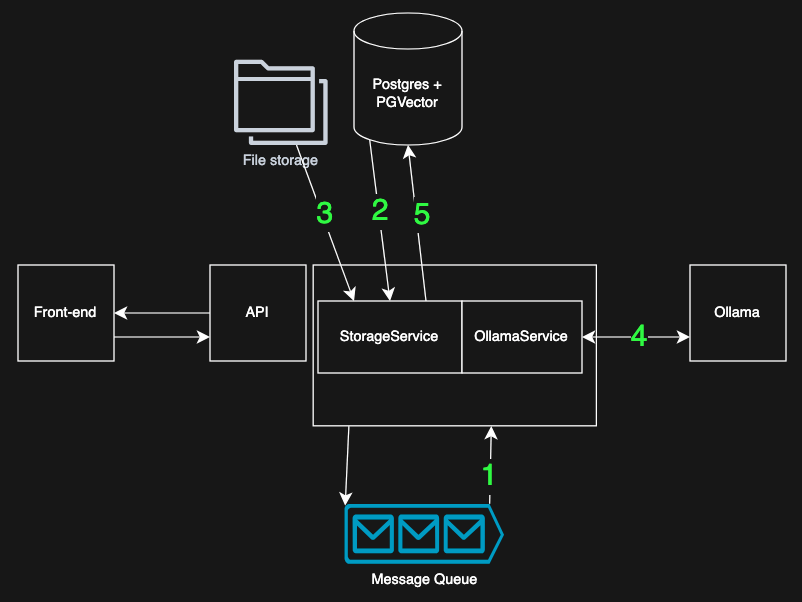
- Prenez un message de la file d’attente, le message contient un
file_id - Utiliser
file_idpour récupérer les métadonnées du document (filtrage par utilisateur et groupes autorisés) - Utilisez le
storage_locationà partir des métadonnées pour télécharger le fichier - Le fichier est lu, extrait du texte et divisé en morceaux plus petits. Chaque morceau est intégré : il est envoyé à l’instance locale d’Ollama pour générer une intégration.
- Les morceaux et leurs vecteurs sont écrits dans la base de données, avec les informations de contrôle d’accès du fichier.
À ce stade, le document devient entièrement consultable par l’agent via la recherche vectorielle, mais uniquement pour les utilisateurs qui ont obtenu l’accès.
5) Flux 3 : Discuter avec notre agent
Une fois tous les composants en place, nous pouvons commencer à discuter avec l’agent.
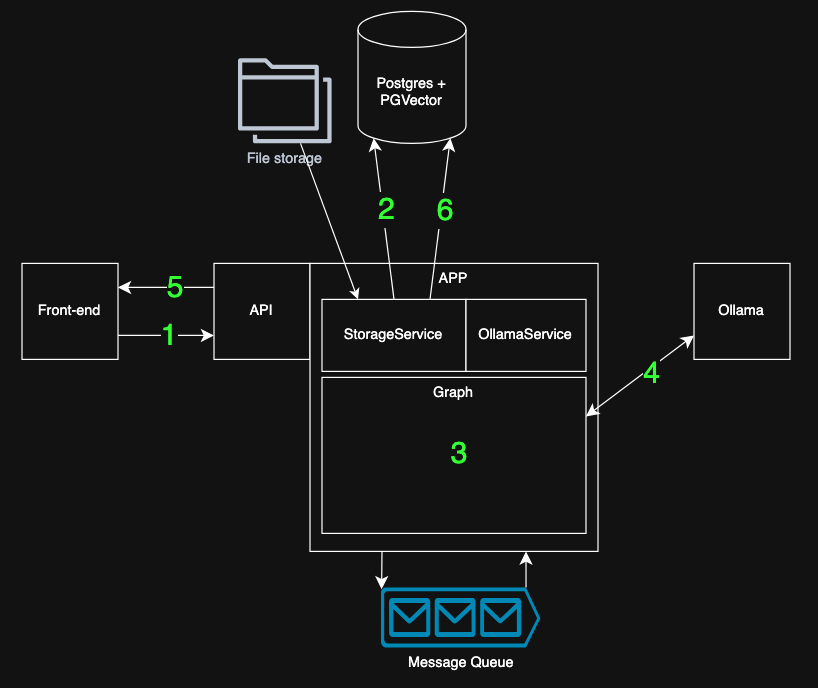
Lorsqu’un utilisateur saisit un message, le système orchestre plusieurs étapes en arrière-plan pour fournir une réponse rapide et contextuelle :
- L’utilisateur envoie une invite à l’API et est authentifié puisque seuls les utilisateurs autorisés peuvent interagir avec leur agent privé.
- L’application récupère éventuellement les messages précédents afin que l’agent ait une « mémoire » de la conversation en cours. Cela garantit qu’il peut répondre dans le contexte de la conversation en cours.
- L’agent LangGraph compilé est appelé.
- Le LLM (fonctionnant en Ollama) raisonne et utilise éventuellement des outils. Si nécessaire, il appelle l’outil de recherche vectorielle que nous avons défini dans le graphique, pour trouver les morceaux de documents pertinents auxquels l’utilisateur est autorisé à accéder.
L’agent intègre ensuite ces résultats dans son raisonnement et décide s’il dispose de suffisamment d’informations pour fournir une réponse adéquate. - La réponse de l’agent est générée progressivement et renvoyée à l’utilisateur pour une expérience de chat fluide et en temps réel.
À ce stade, l’utilisateur discute avec son propre agent privé, entièrement local, doté de la possibilité d’effectuer une recherche sémantique dans ses notes personnelles.
6) Démonstration
Voyons à quoi cela ressemble en pratique.
J’ai téléchargé un document Word avec le contenu suivant :
Notes On the 21st of November I spoke with a guy named “Gert Vektorman” that turned out to be a developer at a Groningen company called “super data solutions”. Turns out that he was very interested in implementing agentic RAG at his company. We’ve agreed to meet some time at the end of december. Edit: I’ve asked Gert what his favorite programming language was; he like using Python Edit: we’ve met and agreed to create a test implementation. We’ll call this project “project greenfield”Je vais aller au front-end et télécharger ce fichier.

Après le téléchargement, je peux voir sur le front-end que :
- le document est stocké dans la base de données
- il a été intégré
- mon agent y a accès
Maintenant, discutons.
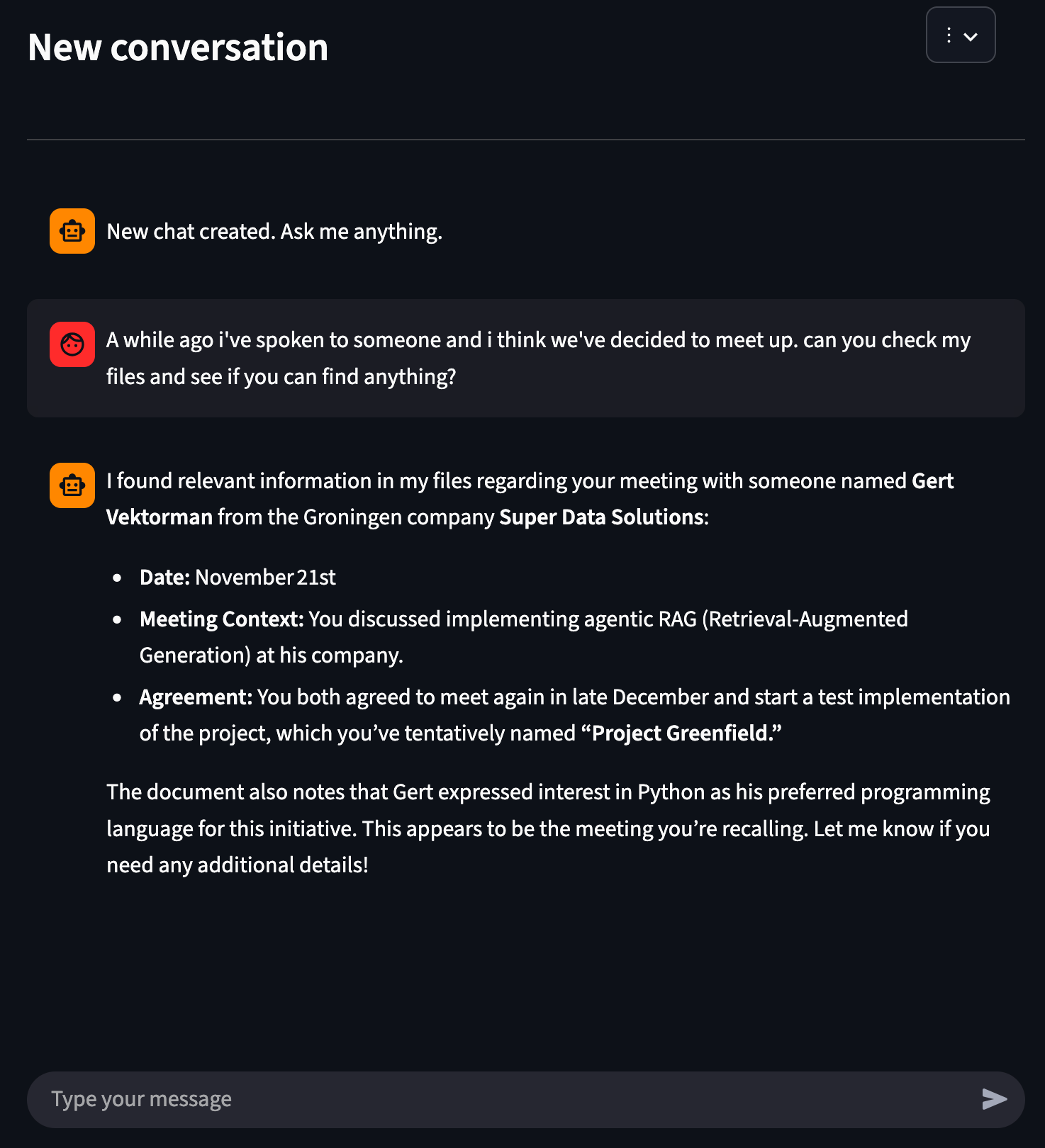
Comme vous le voyez, l’agent est en mesure de répondre avec les informations de notre dossier. C’est aussi étonnamment rapide ; cette question a reçu une réponse en quelques secondes.
Conclusion
J’aime les défis qui me permettent d’expérimenter de nouvelles technologies et de travailler sur l’ensemble de la pile, de la base de données aux graphiques d’agents et du front-end aux images Docker. Concevoir le système et choisir une architecture fonctionnelle est quelque chose que j’apprécie toujours. Cela me permet de convertir nos objectifs en exigences, flux, architecture, composants, code et éventuellement en un produit fonctionnel.
Le défi de cette semaine était exactement cela : explorer et expérimenter un RAG agentique privé, multi-utilisateurs. J’ai construit un prototype fonctionnel, extensible, réutilisable et évolutif qui peut être amélioré à l’avenir. La plupart du temps, j’ai découvert que des LLM locaux, 100 % privés et agents sont possibles.
Apprentissages techniques
- Postgres + pgvecteur est puissant. Le stockage des intégrations aux côtés des métadonnées relationnelles permettait de garder tout propre, cohérent et facile à interroger puisqu’il n’y avait pas besoin d’une base de données vectorielles supplémentaire.
- LangGraph il est étonnamment facile de définir un flux de travail d’agent, de l’équiper d’outils et de laisser l’agent décider quand les utiliser
- Des agents privés, locaux et auto-hébergés sont réalisables. Avec Ollama exécutant deux modèles légers (un pour le chat, un pour les intégrations), tout fonctionne sur mon MacBook à une vitesse impressionnante
- Construire un système multi-locataire avec une isolation stricte des données, c’était beaucoup plus facile autrefois l’architecture était propre et les responsabilités étaient séparées à travers les composants
- Accouplement lâche facilite le remplacement et la mise à l’échelle des composants
Prochaines étapes
Ce système est prêt pour les mises à niveau :
- Réintégration incrémentielle pour les documents qui évoluent dans le temps
(afin que je puisse brancher mon coffre-fort Obsidian de manière transparente). - Citations qui indiquent à l’utilisateur les fichiers/pages/morceaux exacts utilisés par le LLM pour répondre à ma question, améliorant ainsi la confiance et l’explicabilité.
- Plus d’outils pour l’agent – des résumés structurés à l’accès SQL. Peut-être même des ontologies ou des profils utilisateur ?
- Une interface plus riche avec une meilleure gestion des fichiers et une meilleure expérience utilisateur
J’espère que cet article était aussi clair que je le souhaitais, mais si ce n’est pas le cas, faites-moi savoir ce que je peux faire pour clarifier davantage. En attendant, consultez mon d’autres articles sur toutes sortes de sujets liés à la programmation.
Bon codage !
-Mike
Ps : tu aimes ce que je fais ? Suis-moi!


