

Transformer 127 millions de points de données en un rapport sectoriel
cette année, j’ai publié un rapport sur l’industrie intitulé Remédiation à grande échelle analyser comment les équipes de sécurité des applications (AppSec) corrigent les vulnérabilités de leur code. L’ensemble de données : des dizaines de milliers de référentiels, une année complète de données d’analyse et des organisations allant des startups aux entreprises. Au total, plus de 127 millions de points de données couvrant les résultats individuels, les événements d’analyse et les actions correctives répartis sur deux types d’analyse de sécurité (SAST et SCA).
Je suis PMM technique senior chez Semgrep avec une formation en informatique, en science des données et en ingénierie de solutions. J’aime construire des choses. Ce projet m’a permis de combiner tout cela en un seul mouvement : écrire le code SQL, créer des scripts pour gérer l’analyse, analyser et nettoyer les données, trouver l’histoire que racontent les données et expédier l’actif final peaufiné.
Cet article passe en revue cinq leçons que j’ai apprises en cours de route. Si vous avez déjà dû prendre un ensemble de données massif, y trouver le récit et le transformer en quelque chose sur lequel un public technique et non technique peut agir, certaines de ces informations pourraient être utiles.
1. Commencez par les données, pas par l’histoire
La tentation, dans tout projet de données, est de décider d’abord de votre récit, puis de chercher des chiffres pour l’étayer. J’ai fait le contraire.
J’ai passé des semaines en mode exploration pure. Interroger Snowflake, examiner les distributions, exécuter des agrégations sur différentes dimensions. Aucune hypothèse, aucun angle. J’essaie juste de comprendre ce que les données montrent réellement.
C’était inconfortable. Les parties prenantes voulaient savoir ce que dirait le rapport. Je n’avais pas encore de réponse.
Mais cela s’est avéré être la phase la plus importante de tout le projet. Les données racontaient une histoire que je n’aurais pas devinée : l’écart entre les équipes de sécurité les plus performantes et les autres n’était pas une question d’outils. Il s’agissait d’un suivi systématique des mesures correctives. Je n’aurais jamais atterri sur ce cadrage si j’avais commencé par une thèse.
Il faut aussi être prêt à tuer ses chéris. Il y avait plusieurs conclusions que je voulais être vraies et que les données ne confirmaient pas. D’un autre côté, certaines des informations les plus intéressantes sont venues d’endroits que je ne cherchais pas. J’ai utilisé des LLM locaux via Ollama pour classer plus de 10 000 enregistrements de tri textuels en 20 catégories thématiques. Il en est ressorti un modèle clair : les thèmes les plus courants concernaient les fichiers de test, les protections du framework et les services de confiance. Cela raconte une histoire sur la façon dont les équipes utilisent réellement les outils de triage que je n’aurais jamais trouvée en examinant les mesures globales.
Quelques éléments qui ont aidé lors de l’exploration :
- Exécutez d’abord les requêtes de diagnostic. J’ai construit un ensemble de plus de 12 contrôles de qualité des données avant de toucher à l’analyse. L’un d’eux a découvert qu’une métrique clé (parse_rate) ne couvrait qu’une fraction des pensions. Je suis passé à un champ alternatif (NUM_BYTES_SCANNED) avec une couverture de plus de 90 %. Sans ce diagnostic, l’ensemble de l’analyse des résultats par ligne de code aurait été mal calculé.
- Intégrez un point de contrôle/un CV dans votre pipeline. J’ai eu plus de 108 requêtes SQL dans plusieurs sections du rapport. J’ai écrit un script shell qui détectait automatiquement les fichiers .sql, suivait ceux qui avaient déjà produit des CSV de sortie et les ignorait lors des réexécutions. Lorsque les requêtes échouaient à mi-chemin (et ce fut le cas), je pouvais reprendre là où je m’étais arrêté au lieu de tout réexécuter.
- Documentez au fur et à mesure. Chaque résultat intéressant, chaque impasse, chaque hypothèse. Ce journal en cours d’exécution est devenu l’épine dorsale de la section méthodologie du rapport et m’a fait gagner des semaines lorsque j’ai dû revenir sur mes pas.

2. Devenez l’expert du domaine
Vous ne pouvez pas raconter une histoire sur des données que vous ne comprenez pas. Avant de pouvoir écrire une seule section, j’avais besoin de savoir comment fonctionnent les scanners d’analyse statique, comment les flux de remédiation fonctionnent dans la pratique et quelles mesures sont réellement importantes pour les équipes de sécurité.
Plusieurs entreprises du secteur publient des rapports annuels sur des sujets similaires. J’en ai collecté et lu autant que j’ai pu trouver. Non pas pour copier, mais pour comprendre le format, la profondeur et les attentes. Leur lecture m’a donné l’impression de :
- Ce que l’industrie attend de ce type de ressource
- Ce qui est déjà bien couvert
- Où il y a de la place pour dire quelque chose de nouveau
Cela m’a également aidé à repérer les lacunes. La plupart des rapports se concentrent sur le volume de détection. Très peu d’entre eux se penchent sur ce qui se passe après la détection. C’est devenu notre angle.
Sauter cette phase aurait signifié rédiger un rapport rempli d’observations au niveau de la surface qui ne se différenciaient pas des autres excellents contenus produits par d’autres.
3. Parlez tôt et souvent à votre public cible
Les premières versions de l’analyse montraient simplement des moyennes. Taux de correction moyen, temps moyen de correction, résultats moyens par pension. Les chiffres étaient bons. L’histoire était ennuyeuse.
La percée a eu lieu après avoir discuté avec de vrais praticiens : les ingénieurs de sécurité, les responsables AppSec et les RSSI qui liraient le produit final. Tout le monde voulait répondre à une question : comment puis-je me comparer aux équipes qui réussissent bien ?
Ces commentaires ont directement façonné deux des décisions les plus importantes du rapport.
Premièrement, cela a conduit à une segmentation basée sur des cohortes. J’ai divisé les organisations en deux groupes : les 15 % les plus performants par taux fixe (« leaders ») et tous les autres (« le terrain »). Ceci est similaire à la façon dont les rapports basés sur des enquêtes segmentent par niveau de maturité, sauf que j’utilisais des données comportementales plutôt que des réponses autodéclarées. Soudain, les données étaient contrastées :
- Les dirigeants corrigent 2 à 3 fois plus de vulnérabilités
- Ils résolvent les résultats détectés lors de la révision du code 9 fois plus rapidement que les résultats des analyses complètes du référentiel.
- Ils adoptent des fonctionnalités d’automatisation des flux de travail à des rythmes plus élevés et en extraient plus de valeur
La segmentation faisait la différence entre « voici quelques chiffres » et « voici quelque chose sur lequel vous pouvez agir ».
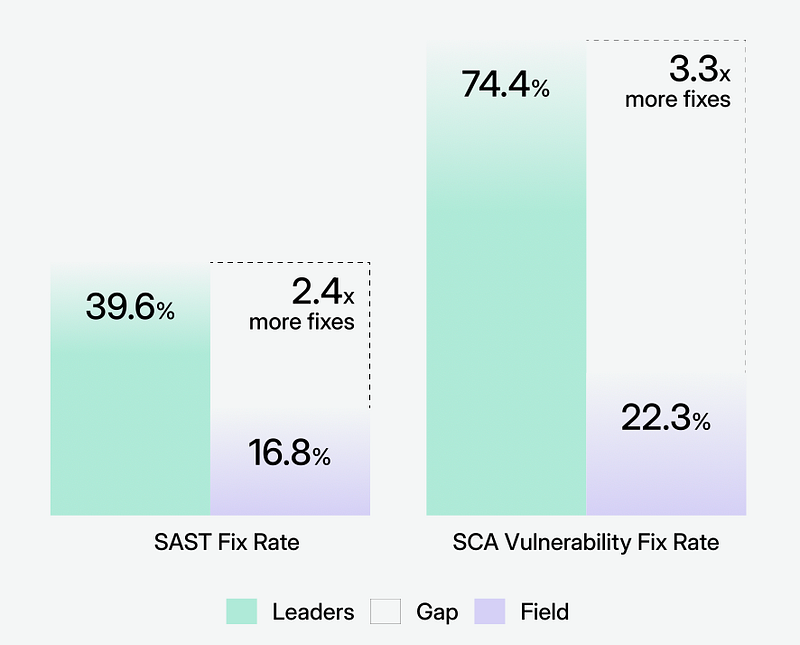
Deuxièmement, il a remodelé la structure du rapport. Les gens ne voulaient pas seulement des points de repère. Ils voulaient savoir quoi faire à leur sujet. « Super, la cohorte des leaders corrige davantage de vulnérabilités de sécurité du code. Comment puis-je devenir un leader ? » Ces commentaires m’ont amené à ajouter une section de recommandations fondées sur des preuves organisées par vitesse de mise en œuvre :
- Gains rapides pour cette semaine
- Changements de processus pour ce trimestre
- Investissements stratégiques pour le semestre
Le rapport final se présente autant comme un manuel que comme une référence. Rien de tout cela ne serait arrivé sans la présentation des premières versions aux lecteurs réels.
4. Impliquez le design dès le début
Celui-ci, j’ai failli l’apprendre trop tard. Les rapports de données vivent ou meurent selon leur apparence. Un mur de graphiques sans hiérarchie visuelle est aussi mauvais qu’une absence de données du tout.
J’ai fait venir notre équipe de conception plus tôt que d’habitude et j’ai passé du temps à les guider à travers le domaine. Que signifie « analyse d’accessibilité » ? Pourquoi la séparation des cohortes est-elle importante ? Lorsque les concepteurs ont compris l’histoire, ils ont fait des choix (code couleur pour les cohortes, zones de légende pour les informations clés, exemples de code avant/après) qui l’ont renforcée sans que j’aie à l’expliquer dans le texte.

5. Donnez-vous du temps
Ce projet a pris des mois. L’exploration des données à elle seule a duré des semaines. Ensuite, il y a eu des itérations sur l’analyse au fur et à mesure que j’ai découvert de nouveaux angles, cycles de conception, révisions juridiques et séries de commentaires des parties prenantes de l’entreprise.
Si j’avais essayé de l’expédier en un trimestre, le résultat aurait été inoubliable.
Où il a atterri
Avec le recul, les deux choses que je changerais concernent toutes deux la vitesse. J’écrirais chaque définition et hypothèse dès le premier jour. Des choses comme « qu’est-ce qui compte comme un référentiel actif » ou « comment calculons-nous le taux de correction » semblent évidentes au début. Ils deviennent rapidement contestés. J’ai finalement créé un document de définitions formelles couvrant plus de 40 métriques, mais le faire plus tôt aurait évité plusieurs séries de retouches. Et j’apporterais une deuxième paire d’yeux pendant l’exploration. Travailler en solo signifiait que personne ne devait vérifier si une découverte était intéressante ou simplement du bruit.
Le rapport lui-même, Remédiation à grande échellecouvre six modèles fondés sur des preuves qui distinguent les équipes de sécurité hautement performantes des autres. Si vous avez abordé un projet de reporting similaire, gourmand en données, je serais curieux de savoir ce que vous avez appris en cours de route.
You may also like


