
Maîtriser les données non linéaires : un guide du SplineTransformer de Scikit-Learn
que les modèles linéaires peuvent être… enfin, rigides. Avez-vous déjà regardé un nuage de points et réalisé qu’une ligne droite ne suffirait pas ? Nous sommes tous passés par là.
Les données du monde réel sont toujours un défi. La plupart du temps, on a l’impression que l’exception est la règle. Les données que vous obtenez dans votre travail n’ont rien à voir avec ces magnifiques ensembles de données linéaires que nous avons utilisés pendant des années de formation à l’académie.
Par exemple, vous regardez quelque chose comme « Demande d’énergie par rapport à la température ». Ce n’est pas une ligne ; c’est une courbe. Habituellement, notre premier réflexe est de recourir à la régression polynomiale. Mais c’est un piège !
Si vous avez déjà vu une courbe de modèle se déchaîner sur les bords de votre graphique, vous avez été témoin du «Phénomène Runge.« Les polynômes de haut degré sont comme un enfant avec un crayon, car ils sont trop flexibles et n’ont aucune discipline.
C’est pourquoi je vais vous montrer cette option appelée Cannelures. C’est une solution intéressante : plus flexible qu’une droite, mais bien plus disciplinée qu’un polynôme.
Les splines sont des fonctions mathématiques définies par des polynômes et utilisées pour lisser une courbe.
Au lieu d’essayer d’adapter une équation complexe à l’ensemble de votre ensemble de données, vous divisez les données en segments en des points appelés noeuds. Chaque segment possède son propre polynôme simple, et ils sont tous assemblés si facilement que vous ne pouvez même pas voir les coutures.
Le problème avec les polynômes
Imaginons que nous ayons une tendance non linéaire et que nous appliquons un polynôme x² ou x³ à cela. Cela semble correct localement, mais nous regardons ensuite les limites de vos données et la courbe s’éloigne considérablement. Selon Le phénomène de Runge [2], les polynômes de haut degré ont ce problème où un point de données étrange à une extrémité peut dérégler toute la courbe à l’autre extrémité.

Pourquoi les splines sont le choix « parfait »
Les splines n’essaient pas d’adapter une équation géante à tout. Au lieu de cela, ils divisent vos données en segments à l’aide de points appelés noeuds. Nous avons certains avantages à utiliser des nœuds.
- Contrôle local : Ce qui se passe dans un segment reste dans ce segment. Étant donné que ces morceaux sont locaux, un point de données étrange à une extrémité de votre graphique ne gâchera pas l’ajustement à l’autre extrémité.
- Douceur: Ils utilisent des « B-splines » (Basis splines) pour garantir que là où les segments se rencontrent, la courbe est parfaitement lisse.
- Stabilité: Contrairement aux polynômes, ils ne se déchaînent pas aux limites.
D’accord. Assez parlé, implémentons maintenant cette solution.
L’implémenter avec Scikit-Learn
Scikit-Learn SplineTransformer est le choix idéal pour cela. Il transforme une seule caractéristique numérique en plusieurs fonctionnalités de base qu’un modèle linéaire simple peut ensuite utiliser pour apprendre des formes complexes et non linéaires.
Importons quelques modules.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import SplineTransformer
from sklearn.linear_model import Ridge
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCVEnsuite, nous créons des données oscillantes courbes.
# 1. Create some 'wiggly' synthetic data (e.g., seasonal sales)
rng = np.random.RandomState(42)
X = np.sort(rng.rand(100, 1) * 10, axis=0)
y = np.sin(X).ravel() + rng.normal(0, 0.1, X.shape[0])
# Plot the data
plt.figure(figsize=(12, 5))
plt.scatter(X, y, color='gray', alpha=0.5, label='Data')
plt.legend()
plt.title("Data")
plt.show()
D’accord. Nous allons maintenant créer un pipeline qui exécute le SplineTranformer avec les paramètres par défaut, suivis d’une régression Ridge.
# 2. Build a pipeline: Splines + Linear Model
# n_knots=5 (default) creates 4 segments; degree=3 makes it a cubic spline
model = make_pipeline(
SplineTransformer(n_knots=5, degree=3),
Ridge(alpha=0.1)
)Ensuite, nous ajusterons le nombre de nœuds pour notre modèle. Nous utilisons GridSearchCV pour exécuter plusieurs versions du modèle, en testant différents nombres de nœuds jusqu’à ce qu’il trouve celui qui fonctionne le mieux sur nos données.
# We tune 'n_knots' to find the best tune
param_grid = {'splinetransformer__n_knots': range(3, 12)}
grid = GridSearchCV(model, param_grid, cv=5)
grid.fit(X, y)
print(f"Best knot count: {grid.best_params_['splinetransformer__n_knots']}")Best knot count: 8Ensuite, nous reformons notre modèle spline avec le meilleur nombre de nœuds, prédire et tracer les données. Comprenons également ce que nous faisons ici avec cette analyse rapide du SplineTransformer arguments de classe :
n_knots: nombre de joints dans la courbe. Plus vous en avez, plus la courbe devient flexible.degree: Ceci définit la « douceur » des segments. Il fait référence au degré du polynôme utilisé entre les nœuds (1 est une ligne ; 2 est plus lisse ; 3 est la valeur par défaut).knots: Celui-ci indique le modèle où pour placer les joints. Par exemple,uniformsépare la courbe en espaces égaux, tandis que le quantile alloue plus de nœuds là où les données sont plus denses.- Conseil: Utiliser
'quantile'si vos données sont groupées.
- Conseil: Utiliser
extrapolation: indique au modèle ce qu’il doit faire lorsqu’il rencontre des données dehors la portée qu’il a vue pendant l’entraînement.- Conseil: utiliser
'periodic'pour les données cycliques, telles que le calendrier ou l’horloge.
- Conseil: utiliser
include_bias: S’il faut inclure une colonne « biais » (une colonne de tous les uns). Si vous utilisez unLinearRegressionouRidgemodèle plus tard dans votre pipeline, ces modèles ont généralement leur proprefit_intercept=Truevous pouvez donc souvent définir ceci surFalsepour éviter la redondance.
# 2. Build the optimized Spline
model = make_pipeline(
SplineTransformer(n_knots=8,
degree=3,
knots= 'uniform',
extrapolation='constant',
include_bias=False),
Ridge(alpha=0.1)
).fit(X, y)
# 3. Predict and Visualize
y_plot = model.predict(X)
# Plot
plt.figure(figsize=(12, 5))
plt.scatter(X, y, color='gray', alpha=0.5, label='Data')
plt.plot(X, y_plot, color='teal', linewidth=3, label='Spline Model')
plt.plot(X, y_plot_10, color='purple', linewidth=2, label='Polynomial Fit (Degree 20)')
plt.legend()
plt.title("Splines: Flexible yet Disciplined")
plt.show()Voici le résultat. Avec les splines, nous avons un meilleur contrôle et un modèle plus fluide, éliminant le problème des extrémités.
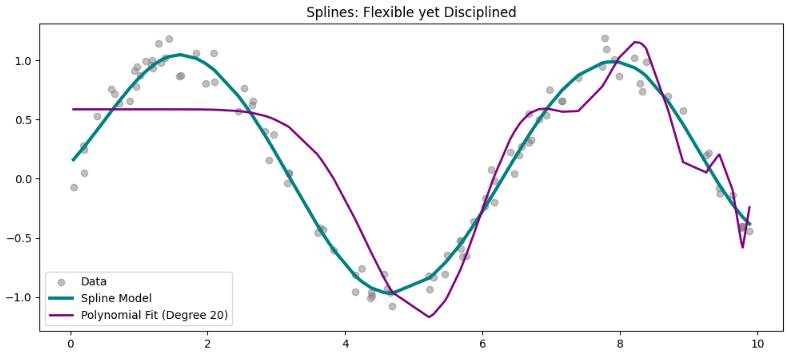
Nous comparons un modèle polynomial de degree=20 avec le modèle spline. On peut affirmer que les diplômes inférieurs peuvent réaliser une bien meilleure modélisation de ces données, et cela serait correct. J’ai testé jusqu’au 13ème degré, et cela correspond bien à cet ensemble de données.
Pourtant, c’est exactement le but de cet article. Lorsque le modèle ne s’adapte pas très bien aux données et que nous devons continuer à augmenter le degré polynomial, nous tomberons certainement dans la situation bords sauvages problème.
Applications réelles
Où utiliseriez-vous réellement cela en entreprise ?
- Cycles de séries chronologiques : Utiliser
extrapolation='periodic'pour des fonctionnalités telles que « heure du jour » ou « mois de l’année ». Cela garantit que le modèle sait que 23h59 est juste à côté de 00h01. Avec cet argument, nous disons auSplineTransformerque la fin de notre cycle (heure 23) devrait s’enrouler et rejoindre le début (heure 0). Ainsi, la spline garantit que la pente et la valeur en fin de journée correspondent parfaitement au début de la journée suivante. - Dose-réponse en médecine : Modéliser la manière dont un médicament affecte un patient. La plupart des médicaments suivent une courbe non linéaire où le bénéfice finit par se stabiliser (saturation) ou, pire, se transformer en toxicité. Les splines sont ici la « référence » car elles peuvent cartographier ces changements biologiques complexes sans forcer les données à prendre une forme rigide.
- Revenu vs expérience : Le salaire augmente souvent rapidement au début, puis se stabilise ; les splines capturent parfaitement ce « virage ».
Avant de partir
Nous avons abordé beaucoup de choses ici, depuis les raisons pour lesquelles les polynômes peuvent être un choix « sauvage » jusqu’à la manière dont les splines périodiques résolvent l’intervalle de minuit. Voici un résumé rapide à garder dans votre poche arrière :
- La règle d’or : Utilisez les splines lorsqu’une ligne droite est trop simple, mais qu’un polynôme de haut degré commence à osciller et à être surajusté.
- Les nœuds sont la clé : Les nœuds sont les « articulations » de votre modèle. Trouver le bon numéro via
GridSearchCVC’est la différence entre une courbe douce et un désordre irrégulier. - Puissance périodique : Pour toute fonctionnalité qui cycle (heures, jours, mois), utilisez
extrapolation='periodic'. Cela garantit que le modèle comprend que la fin du cycle revient parfaitement au début. - Ingénierie des fonctionnalités > Modèles complexes : Souvent, un simple
Ridgerégression combinée avecSplineTransformersurpassera un modèle complexe de « Black Box » tout en restant beaucoup plus facile à expliquer à votre patron.
Si vous avez aimé ce contenu, découvrez mon travail et mes contacts sur mon site internet.
Dépôt GitHub
Voici le code complet de cet exercice, et quelques extras.
https://github.com/gurezende/Studying/blob/master/Python/sklearn/SplineTransformer.ipynb
Références
[1. SplineTransformer Documentation] https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.SplineTransformer.html
[2. Runge’s Phenomenon] https://en.wikipedia.org/wiki/Runge%27s_phenomenon
[3. Make Pipeline Docs] https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.make_pipeline.html


