
Apprentissage fédéré, partie 1 : les bases des modèles de formation là où résident les données
I le concept d’apprentissage fédéré (EF) à travers un bande dessinée par Google en 2019. C’était un article brillant et a fait un excellent travail en expliquant comment les produits peuvent s’améliorer sans envoyer les données des utilisateurs vers le cloud. Dernièrement, j’ai voulu comprendre plus en détail l’aspect technique de ce domaine. Les données de formation sont devenues un bien si important car elles sont essentielles à la création de bons modèles, mais une grande partie de celles-ci restent inutilisées car elles sont fragmentées, non structurées ou enfermées dans des silos.
En commençant à explorer ce domaine, j’ai découvert Cadre fleuriêtre le moyen le plus simple et le plus convivial pour les débutants de démarrer en Floride. Il est open source, la documentation est claire et la communauté qui l’entoure est très active et utile. C’est une des raisons de mon regain d’intérêt pour ce domaine.
Cet article est la première partie d’une série dans laquelle j’explore l’apprentissage fédéré plus en profondeur, couvrant ce que c’est, comment il est mis en œuvre, les problèmes ouverts auxquels il est confronté et pourquoi il est important dans les contextes sensibles à la confidentialité. Dans les prochains articles, j’approfondirai la mise en œuvre pratique avec le Fleur cadre, discutez de la confidentialité dans l’apprentissage fédéré et examinez comment ces idées s’étendent à des cas d’utilisation plus avancés.
Quand l’apprentissage automatique centralisé n’est pas idéal
Nous savons que les modèles d’IA dépendent de grandes quantités de données, mais la plupart des données les plus utiles sont sensibles, distribuées et difficiles d’accès. Pensez aux données contenues dans les hôpitaux, les téléphones, les voitures, les capteurs et autres systèmes périphériques. Les problèmes de confidentialité, les règles locales, le stockage limité et les limites du réseau rendent le déplacement de ces données vers un emplacement central très difficile, voire impossible. En conséquence, de grandes quantités de données précieuses restent inutilisées. Dans le domaine des soins de santé, ce problème est particulièrement visible. Les hôpitaux génèrent des dizaines de pétaoctets de données chaque année, mais des études estiment que jusqu’à 97 % de ces données restent inutilisées.
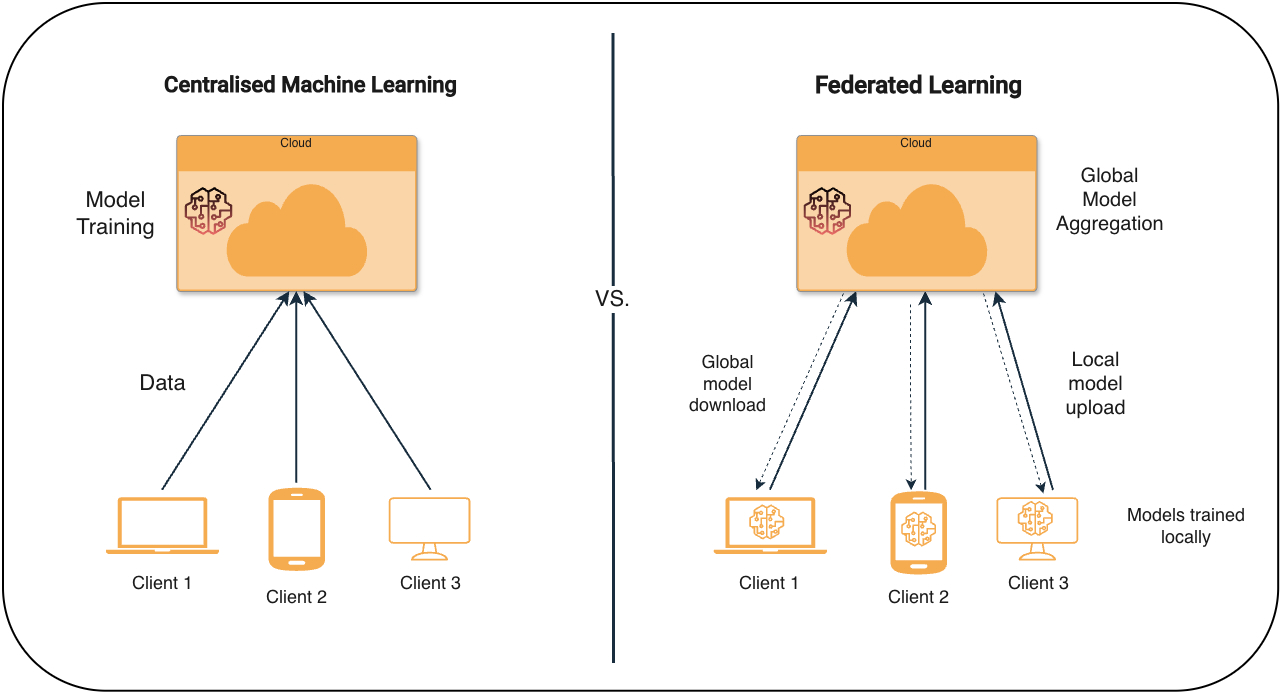
L’apprentissage automatique traditionnel suppose que toutes les données de formation peuvent être collectées en un seul endroit, généralement sur un serveur ou un centre de données centralisé. Cela fonctionne lorsque les données peuvent être librement déplacées, mais cela ne fonctionne pas lorsque les données sont privées ou protégées. En pratique, la formation centralisée dépend également d’une connectivité stable, d’une bande passante suffisante et d’une faible latence, difficiles à garantir dans les environnements distribués ou en périphérie.

Dans de tels cas, deux choix courants apparaissent. Une option consiste à ne pas utiliser les données du tout, ce qui signifie que les informations précieuses restent enfermées dans des silos.
L’autre option consiste à laisser chaque entité locale entraîner un modèle sur ses propres données et partager uniquement ce que le modèle apprend, tandis que les données brutes ne quittent jamais leur emplacement d’origine. Cette deuxième option constitue la base de l’apprentissage fédéré, qui permet aux modèles d’apprendre à partir de données distribuées sans les déplacer. Un exemple bien connu est Google Gboard sur Androidoù des fonctionnalités telles que la prédiction du mot suivant et Rédaction intelligente fonctionner sur des centaines de millions d’appareils.
Apprentissage fédéré : déplacer le modèle vers les données
L’apprentissage fédéré peut être considéré comme une configuration d’apprentissage automatique collaboratif dans laquelle la formation se déroule sans collecter de données dans un endroit central. Avant d’examiner comment cela fonctionne sous le capot, voyons quelques exemples concrets qui montrent pourquoi cette approche est importante dans les contextes à haut risque, couvrant des domaines allant des soins de santé aux environnements sensibles en matière de sécurité.
Soins de santé
Dans le domaine de la santé, l’apprentissage fédéré a permis Dépistage COVID via IA curialeun système formé dans plusieurs hôpitaux du NHS à l’aide de signes vitaux et de tests sanguins de routine. Étant donné que les données des patients ne pouvaient pas être partagées entre les hôpitaux, la formation a été dispensée localement sur chaque site et seules les mises à jour des modèles ont été échangées. Le modèle global résultant s’est mieux généralisé que les modèles formés dans des hôpitaux individuels, en particulier lorsqu’ils sont évalués sur des sites invisibles.
Imagerie médicale

L’apprentissage fédéré est également exploré en imagerie médicale. Des chercheurs de l’UCL et du Moorfields Eye Hospital l’utilisent pour affiner les modèles de base de grande vision sur des examens oculaires sensibles qui ne peut pas être centralisé.
Défense
Au-delà des soins de santé, l’apprentissage fédéré est également appliqué dans domaines sensibles en matière de sécurité tels que la défense et l’aviation. Ici, les modèles sont formés sur des données physiologiques et opérationnelles distribuées qui doivent rester locales.
Différents types d’apprentissage fédéré
À un niveau élevé, l’apprentissage fédéré peut être regroupé en quelques types courants basés sur qui sont les clients et comment les données sont divisées.
• Apprentissage fédéré multi-appareils ou multi-silos
Apprentissage fédéré multi-appareils implique l’utilisation de nombreux clients pouvant atteindre des millions, comme des appareils personnels ou des téléphones, chacun avec une petite quantité de données locales et une connectivité peu fiable. Cependant, à un moment donné, seule une petite fraction des appareils participe à un tour donné. Google Gboard est un exemple typique de cette configuration.
Traverse-silo apprentissage fédéré, d’autre part, implique un nombre beaucoup plus restreint de clients, généralement des organisations comme des hôpitaux ou des banques. Chaque client détient un vaste ensemble de données et dispose d’un calcul et d’une connectivité stables. La plupart des cas d’utilisation réels en entreprise et dans le secteur de la santé ressemblent à un apprentissage fédéré inter-silos.
• Apprentissage fédéré horizontal ou vertical

Apprentissage fédéré horizontal décrit comment les données sont réparties entre les clients. Dans ce cas, tous les clients partagent le même espace de fonctionnalités, mais chacun contient des échantillons différents. Par exemple, plusieurs hôpitaux peuvent enregistrer les mêmes variables médicales, mais pour des patients différents. Il s’agit de la forme la plus courante d’apprentissage fédéré.
Apprentissage fédéré vertical est utilisé lorsque les clients partagent le même ensemble d’entités mais ont des fonctionnalités différentes. Par exemple, un hôpital et un assureur peuvent tous deux disposer de données sur les mêmes personnes, mais avec des attributs différents. Dans ce cas, la formation nécessite une coordination sécurisée car les espaces de fonctionnalités diffèrent, et cette configuration est moins courante que l’apprentissage fédéré horizontal.
Ces catégories ne s’excluent pas mutuellement. Un système réel est souvent décrit en utilisant les deux axes, par exemple, un apprentissage fédéré trans-silo et horizontal installation.
Comment fonctionne l’apprentissage fédéré
L’apprentissage fédéré suit un processus simple et répété coordonné par un serveur central et exécuté par plusieurs clients détenant des données localement, comme le montre le diagramme ci-dessous.

La formation à l’apprentissage fédéré se déroule par des rondes d’apprentissage fédérées. À chaque tour, le serveur sélectionne un petit sous-ensemble aléatoire de clients, leur envoie les poids actuels du modèle et attend les mises à jour. Chaque client entraîne le modèle localement en utilisant descente de gradient stochastiquegénéralement pour plusieurs époques locales sur ses propres lots, et renvoie uniquement les poids mis à jour. À un niveau élevé, cela suit les cinq étapes suivantes :
- Initialisation
Un modèle global est créé sur le serveur, qui fait office de coordinateur. Le modèle peut être initialisé de manière aléatoire ou partir d’un état pré-entraîné.
2. Distribution du modèle
À chaque tour, le serveur sélectionne un ensemble de clients (sur la base d’un échantillonnage aléatoire ou d’une stratégie prédéfinie) qui participent à la formation et leur envoie les poids globaux actuels du modèle. Ces clients peuvent être des téléphones, des appareils IoT ou des hôpitaux individuels.
3. Formation locale
Chaque client sélectionné entraîne ensuite le modèle localement en utilisant ses propres données. Les données ne quittent jamais le client et tous les calculs ont lieu sur l’appareil ou au sein d’une organisation comme un hôpital ou une banque.
4. Communication de mise à jour du modèle
Après la formation locale, les clients renvoient uniquement les paramètres du modèle mis à jour (pouvant être des poids ou des gradients) au serveur tandis que les données brutes sont partagées à tout moment.
5. Agrégation
Le serveur regroupe les mises à jour client pour produire un nouveau modèle global. Alors que Moyenne fédérée (Fed Moy) est une approche courante pour l’agrégation, d’autres stratégies sont également utilisées. Le modèle mis à jour est ensuite renvoyé aux clients et le processus se répète jusqu’à convergence.
L’apprentissage fédéré est un processus itératif et chaque passage dans cette boucle est appelé un tour. La formation d’un modèle fédéré nécessite généralement plusieurs cycles, parfois des centaines, en fonction de facteurs tels que la taille du modèle, la distribution des données et le problème à résoudre.
L’intuition mathématique derrière la moyenne fédérée
Le flux de travail décrit ci-dessus peut également être écrit de manière plus formelle. La figure ci-dessous montre l’original Moyenne fédérée (Fed Moy) algorithme de L’article fondateur de Google. Cet algorithme est ensuite devenu la principale référence et a démontré que l’apprentissage fédéré peut fonctionner dans la pratique. Cette formulation est en fait devenue aujourd’hui le point de référence pour la plupart des systèmes d’apprentissage fédérés.

L’algorithme original de moyenne fédérée, montrant la boucle de formation serveur-client et l’agrégation pondérée des modèles locaux.
Au cœur de Federated Averaging se trouve l’étape d’agrégation, où le serveur met à jour le modèle global en prenant une moyenne pondérée des modèles client formés localement. Cela peut s’écrire comme suit :

Cette équation montre clairement comment chaque client contribue au modèle global. Les clients disposant de plus de données locales ont une plus grande influence, tandis que ceux disposant de moins d’échantillons contribuent proportionnellement moins. En pratique, cette idée simple est la raison pour laquelle Fed Avg est devenu la référence par défaut pour l’apprentissage fédéré.
Une implémentation simple de NumPy
Regardons un exemple minimal où cinq clients ont été sélectionnés. Par souci de simplicité, nous supposons que chaque client a déjà terminé la formation locale et renvoyé ses poids de modèle mis à jour ainsi que le nombre d’échantillons utilisés. À l’aide de ces valeurs, le serveur calcule une somme pondérée qui produit le nouveau modèle global pour le prochain tour. Cela reflète directement l’équation Fed Avg, sans introduire de formation ni de détails côté client.
import numpy as np
# Client models after local training (w_{t+1}^k)
client_weights = [
np.array([1.0, 0.8, 0.5]), # client 1
np.array([1.2, 0.9, 0.6]), # client 2
np.array([0.9, 0.7, 0.4]), # client 3
np.array([1.1, 0.85, 0.55]), # client 4
np.array([1.3, 1.0, 0.65]) # client 5
]
# Number of samples at each client (n_k)
client_sizes = [50, 150, 100, 300, 4000]
# m_t = total number of samples across selected clients S_t
m_t = sum(client_sizes) # 50+150+100+300+400
# Initialize global model w_{t+1}
w_t_plus_1 = np.zeros_like(client_weights[0])
# FedAvg aggregation:
# w_{t+1} = sum_{k in S_t} (n_k / m_t) * w_{t+1}^k
# (50/1000) * w_1 + (150/1000) * w_2 + ...
for w_k, n_k in zip(client_weights, client_sizes):
w_t_plus_1 += (n_k / m_t) * w_k
print("Aggregated global model w_{t+1}:", w_t_plus_1)
-------------------------------------------------------------
Aggregated global model w_{t+1}: [1.27173913 0.97826087 0.63478261]
Comment l’agrégation est calculée
Juste pour mettre les choses en perspective, nous pouvons étendre l’étape d’agrégation à seulement deux clients et voir comment les chiffres s’alignent.

Défis dans les environnements d’apprentissage fédérés
L’apprentissage fédéré comporte son propre ensemble de défis. L’un des problèmes majeurs lors de sa mise en œuvre est que les données entre les clients sont souvent non-IID (non indépendantes et distribuées de manière identique). Cela signifie que différents clients peuvent voir des distributions de données très différentes, ce qui peut ralentir la formation et rendre le modèle global moins stable. Par exemple, les hôpitaux d’une fédération peuvent desservir différentes populations qui peuvent suivre différents modèles.
Les systèmes fédérés peuvent impliquer de quelques organisations à des millions d’appareils et la gestion de la participation, des abandons et de l’agrégation devient plus difficile à mesure que le système évolue.
Même si l’apprentissage fédéré conserve les données brutes au niveau local, il ne résout pas entièrement confidentialité tout seul. Les mises à jour de modèles peuvent toujours divulguer des informations privées si elles ne sont pas protégées et des méthodes de confidentialité supplémentaires sont donc souvent nécessaires. Enfin, communication peut être une source de goulot d’étranglement. Étant donné que les réseaux peuvent être lents ou peu fiables, l’envoi de mises à jour fréquentes peut s’avérer coûteux.
Conclusion et quelle est la suite
Dans cet article, nous avons compris comment fonctionne l’apprentissage fédéré à un niveau élevé et avons également parcouru une implémentation simple de Numpy. Cependant, au lieu d’écrire la logique de base à la main, il existe des frameworks comme Flower qui offrent un moyen simple et flexible de créer des systèmes d’apprentissage fédéré. Dans la partie suivante, nous utiliserons Flower pour faire le gros du travail à notre place afin que nous puissions nous concentrer sur le modèle et les données plutôt que sur les mécanismes de l’apprentissage fédéré. Nous examinerons également LLM fédérésoù la taille du modèle, le coût de communication et les contraintes de confidentialité deviennent encore plus importants.
Remarque : Toutes les images, sauf indication contraire, sont créées par l’auteur.


