
Joyaux cachés dans NumPy : 7 fonctions que tout data scientist devrait connaître
l’analyse de données depuis un an maintenant. Jusqu’à présent, je peux me considérer comme confiant dans SQL et Power BI. La transition vers Python a été assez passionnante. J’ai été exposé à des approches plus intéressantes et plus intelligentes de l’analyse des données.
Après avoir perfectionné mes compétences sur les principes fondamentaux de Python, la prochaine étape idéale était de commencer à découvrir certaines des bibliothèques Python pour l’analyse de données. NumPy en fait partie. Étant un passionné de mathématiques, j’aimerais naturellement explorer cette bibliothèque Python.
Cette bibliothèque est conçue pour les personnes qui souhaitent effectuer des calculs mathématiques à l’aide de Python, depuis les mathématiques de base et l’algèbre jusqu’aux concepts avancés comme le calcul. NumPy peut à peu près tout faire.
Dans cet article, je voulais vous présenter quelques fonctions NumPy avec lesquelles j’ai joué. Que vous soyez un data scientist, un analyste financier ou un chercheur passionné, ces fonctions vous aideront beaucoup. Sans plus tarder, allons-y.
Exemple d’ensemble de données (utilisé partout)
Avant de plonger dans le vif du sujet, je vais définir un petit ensemble de données qui ancrera tous les exemples :
import numpy as np
temps = np.array([30, 32, 29, 35, 36, 33, 31])À l’aide de ce petit ensemble de données de température, je partagerai 7 fonctions qui facilitent les opérations sur les tableaux.
1. np.where()— Le If-Else vectorisé
Avant de définir ce qu’est cette fonction, voici une présentation rapide de la fonction
arr = np.array([10, 15, 20, 25, 30])
indices = np.where(arr > 20)
print(indices)Sortie : (tableau([3, 4]),)
np.where est une fonction basée sur des conditions. Lorsqu’une condition est spécifiée, il génère le ou les index où cette condition est vraie.
Par exemple, dans l’exemple ci-dessus, un tableau est spécifié et j’ai déclaré une fonction np.where qui récupère les enregistrements dont l’élément du tableau est supérieur à 20. La sortie est array([3, 4]), car ce sont les emplacements/indices où cette condition est vraie – ce seront 25 et 30.
Sélection/remplacement conditionnel
C’est également utile lorsque vous essayez de définir une sortie personnalisée pour les sorties qui répondent à votre condition. Ceci est beaucoup utilisé dans l’analyse des données. Par exemple:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
result = np.where(arr % 2 == 0, ‘even’, ‘odd’)
print(result)Sortir: [‘odd’ ‘even’ ‘odd’ ‘even’ ‘odd’]
L’exemple ci-dessus tente de récupérer des nombres pairs. Après la récupération, une fonction de sélection/remplacement de condition est appelée et ajoute un nom personnalisé à nos conditions. Si la condition est vraie, elle est remplacée par pair, et si la condition est fausse, elle est remplacée par impair.
Très bien, appliquons cela à notre petit ensemble de données.
Problème : Remplacez toutes les températures supérieures à 35°C par 35 (plafonnement des lectures extrêmes).
Dans les données du monde réel, en particulier celles provenant de capteurs, de stations météorologiques ou de données utilisateur, les valeurs aberrantes sont assez courantes : des pics soudains ou des valeurs irréalistes qui ne sont pas réalistes.
Par exemple, un capteur de température peut momentanément avoir un problème et enregistrer 42°C alors que la température réelle est de 35°C.
Laisser de telles anomalies dans vos données peut :
- Biais les moyennes : une seule valeur élevée peut faire monter votre moyenne.
- Visualisations déformées : les graphiques peuvent s’étirer pour s’adapter à quelques points extrêmes.
- Modèles trompeurs : les algorithmes d’apprentissage automatique sont sensibles aux plages inattendues.
Réparons ça
adjusted = np.where(temps > 35, 35, temps)Sortie : tableau ([30, 32, 29, 35, 35, 33, 31])
Ça a l’air beaucoup mieux maintenant. Avec seulement quelques lignes de code, nous avons réussi à corriger les valeurs aberrantes irréalistes dans notre ensemble de données.
2. np.clip() — Conserver les valeurs dans la plage
Dans de nombreux ensembles de données pratiques, les valeurs peuvent sortir de la plage attendue, probablement en raison du bruit de mesure, d’une erreur de l’utilisateur ou de différences de mise à l’échelle.
Par exemple:
- Un capteur de température peut indiquer −10°C alors que le minimum possible est de 0°C.
- Un résultat de modèle peut prédire des probabilités telles que 1,03 ou −0,05 en raison de l’arrondi.
- Lors de la normalisation des valeurs de pixels d’une image, certaines peuvent dépasser 0 à 255.
Ces valeurs « hors limites » peuvent sembler mineures, mais elles peuvent :
- Interrompre les calculs en aval (par exemple, calculs de log ou de pourcentage).
- Provoquer des intrigues ou des artefacts irréalistes (en particulier dans le traitement du signal/image).
- Déformer la normalisation et rendre les métriques peu fiables.
np.clip() résout parfaitement ce problème en limitant tous les éléments d’un tableau dans une plage minimale et maximale spécifiée. C’est un peu comme fixer des limites dans votre ensemble de données.
Exemple:
Problème : Assurez-vous que toutes les lectures restent dans les limites [28, 35] gamme.
clipped = np.clip(temps, 28, 35)
clippedSortie : tableau ([30, 32, 29, 35, 35, 33, 31])
Voici ce que cela fait :
- Toute valeur inférieure à 28 devient 28.
- Toute valeur supérieure à 35 devient 35.
- Tout le reste reste le même.
Bien sûr, cela pourrait aussi être fait avec np.where() comme çatemps = np.where(temps < 28, 28, np.where(temps > 35, 35, temps))
Mais je préfère utiliser np.clip() car c’est beaucoup plus propre et plus rapide.
3. np.ptp() — Trouvez la plage de vos données sur une seule ligne
np.ptp() (crête à crête) vous montre essentiellement la différence entre les éléments maximum et minimum.
C’est en gros :np.ptp(a) == np.max(a) — np.min(a)
Mais dans une fonction propre et expressive.
Voici comment ça marche
arr = np.array([[1, 5, 2],
[8, 3, 7]])
# Calculate peak-to-peak range of the entire array
range_all = np.ptp(arr)
print(f”Peak-to-peak range of the entire array: {range_all}”)Ce sera donc notre valeur maximale (8) – valeur minimale (1)
Sortie : Plage crête à crête de l’ensemble du réseau : 7
Alors pourquoi est-ce utile ? Tout comme pour les moyennes, il est souvent tout aussi important de comprendre dans quelle mesure vos données varient. Dans les données météorologiques, par exemple, cela vous montre à quel point les conditions étaient stables ou volatiles.
Au lieu d’appeler séparément max() et min(), ou de soustraire manuellement. np.ptp() le rend concis, lisible et vectorisé, particulièrement utile lorsque vous calculez des plages sur plusieurs lignes ou colonnes.
Maintenant, appliquons cela à notre ensemble de données.
Problème : Dans quelle mesure la température a-t-elle varié cette semaine ?
temps = np.array([30, 32, 29, 35, 36, 33, 31])
np.ptp(temps)Sortie : np.int64(7)
Cela nous indique que la température a fluctué de 7°C sur la période, de 29°C à 36°C.
4. np.diff() — Détecter les changements quotidiens
np.diff() est le moyen le plus rapide de mesurer l’élan, la croissance ou le déclin au fil du temps. Il calcule essentiellement les différences entre les éléments d’un tableau.
Pour vous dresser un tableau, si votre ensemble de données était un voyage, np.ptp() vous indique la distance parcourue au total, tandis que np.diff() vous indique la distance parcourue entre chaque arrêt.
Essentiellement:
np.diff([a1, a2, a3, …]) = [a2 — a1, a3 — a2, …]
Appliquons cela à notre ensemble de données.
Regardons à nouveau nos données de température :
temps = np.array([30, 32, 29, 35, 36, 33, 31])
daily_change = np.diff(temps)
print(daily_change)Sortir: [ 2 -3 6 1 -3 -2]
Dans le monde réel, np.diff() est utilisé pour
- Analyse de séries chronologiques — Suivez les changements quotidiens de température, de ventes ou de cours des actions.
- Traitement du signal — Identifiez les pics ou les baisses soudaines des données des capteurs.
- Validation des données — Détectez les sauts ou les incohérences entre des mesures consécutives.
5. np.gradient() — Capturez les tendances et les pentes lisses
Pour être honnête, lorsque j’ai découvert cela pour la première fois, j’ai eu du mal à comprendre. Mais essentiellement, np.gradient() calcule le gradient numérique (une estimation fluide du changement ou de la pente) sur vos données. C’est similaire à np.diff(), cependant, np.gradient() fonctionne même si vos valeurs X sont inégalement espacées (par exemple, horodatages irréguliers). Il fournit un signal plus fluide, rendant les tendances plus faciles à interpréter visuellement.
Par exemple:
time = np.array([0, 1, 2, 4, 7])
temp = np.array([30, 32, 34, 35, 36])
np.gradient(temp, time)Sortie : tableau ([2. , 2. , 1.5 , 0.43333333, 0.33333333])
Décomposons cela un peu.
Normalement, np.gradient() suppose que les valeurs x (vos positions d’index) sont régulièrement espacées — comme 0, 1, 2, 3, 4, etc. Mais dans l’exemple ci-dessus, le tableau temporel n’est pas uniformément espacé : remarquez que les sauts sont 1, 1, 2, 3. Cela signifie que les relevés de température n’ont pas été effectués toutes les heures.
En faisant passer le temps comme deuxième argument, nous disons essentiellement à NumPy d’utiliser les intervalles de temps réels pour calculer la vitesse à laquelle la température change.
Pour expliquer le résultat ci-dessus. Cela signifie qu’entre 0 et 2 heures, la température a augmenté rapidement (environ 2°C par heure) et entre 2 et 7 heures, la hausse a ralenti jusqu’à environ 0,3 à 1°C par heure.
Appliquons cela à notre ensemble de données.
Problème : Estimer le taux de changement de température (comme la pente).
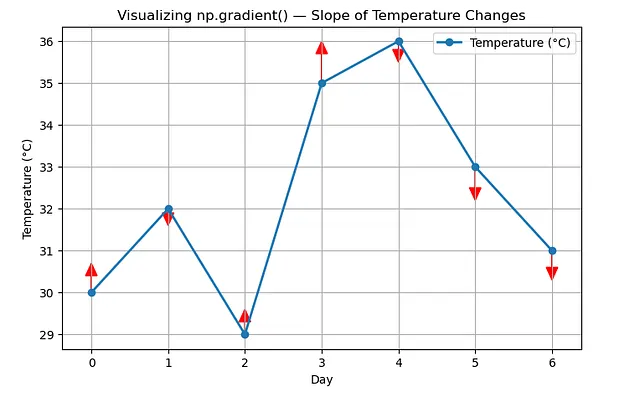
temps = np.array([30, 32, 29, 35, 36, 33, 31])
grad = np.gradient(temps)
np.round(grad, 2)Sortie : tableau ([ 2. , -0.5, 1.5, 3.5, -1. , -2.5, -2. ])
Vous pouvez le lire comme :
- +2 → température augmentant rapidement (échauffement précoce)
- -0,5 → légère baisse (refroidissement mineur)
- +1,5, +3,5 → forte hausse (gros saut de chaleur)
- -1, -2,5, -2 → tendance au refroidissement constante
Cela raconte donc une histoire de température de la semaine. Visualisons cela très rapidement avec matplotlib.
Remarquez à quel point il est facile d’interpréter la visualisation. C’est ce qui rend np.gradient() si utile.

6. np.percentile() – Repérer les valeurs aberrantes ou les seuils
C’est l’une de mes fonctions préférées. np.percentile() vous aide à récupérer des morceaux ou des tranches de vos données. Numpy le définit bien.
numpy.percentile calcule le q-ième centile des données le long d’un axe spécifiéoù q est un pourcentage compris entre 0 et 100.
Dans np.percentile(), il y a généralement un seuil à atteindre (qui est de 100 %). Vous pouvez ensuite revenir en arrière et vérifier le pourcentage d’enregistrements inférieurs à ce seuil.
Essayons cela avec les records de ventes
Disons que votre objectif de ventes mensuel est de 60 000 $.
Vous pouvez utiliser np.percentile() pour comprendre à quelle fréquence et avec quelle force vous atteignez ou manquez cet objectif.
import numpy as np
sales = np.array([45, 50, 52, 48, 60, 62, 58, 70, 72, 66, 63, 80])
np.percentile(sales, [25, 50, 75, 90])Sortir: [51.0 61.0 67.5 73.0]
Pour décomposer cela :
- 25e centile = 51 000 $ → 25 % de vos mois ont été inférieurs à 51 000 ₦ (peu performants)
- 50e centile = 61 000 $ → la moitié de vos mois étaient inférieurs à 61 000 ₦ (autour de votre objectif)
- 75e centile = 67,5 000 $ → les mois les plus performants sont confortablement au-dessus de l’objectif
- 90e centile = 73 000 $ → vos meilleurs mois ont atteint 73 000 ₦ ou plus
Alors maintenant, vous pouvez dire :
« Nous avons atteint ou dépassé notre objectif de 60 000 $ environ sur la moitié de tous les mois. »
Cela peut également être visualisé à l’aide d’une carte KPI. C’est assez puissant.
C’est la narration de KPI avec des données.
Appliquons cela à notre ensemble de données de température.
import numpy as np
temps = np.array([30, 32, 29, 35, 36, 33, 31])
np.percentile(temps, [25, 50, 75])Sortir: [30.5 32. 34.5]
Voici ce que cela signifie :
- 25% des relevés sont inférieurs à 30,5°C
- 50 % (la médiane) sont en dessous de 32°C
- 75% sont en dessous de 34,5°C
7. np.unique() – Trouvez rapidement des valeurs uniques et leurs comptes
Cette fonction est parfaite pour nettoyer, résumer ou catégoriser des données. np.unique() trouve tous les éléments uniques de votre tableau. Il peut également vérifier la fréquence à laquelle ces éléments apparaissent dans votre tableau.
Par exemple, disons que vous avez une liste de catégories de produits de votre magasin :
import numpy as np
products = np.array([
‘Shoes’, ‘Bags’, ‘Bags’, ‘Hats’,
‘Shoes’, ‘Shoes’, ‘Belts’, ‘Hats’
])
np.unique(products)Sortie : tableau ([‘Bags’, ‘Belts’, ‘Hats’, ‘Shoes’]dtype=’
Vous pouvez aller plus loin en comptant le nombre de fois qu’ils apparaissent à l’aide de la propriété return_counts :
np.unique(products, return_counts=True)Sortie : (tableau([‘Bags’, ‘Belts’, ‘Hats’, ‘Shoes’]dtype=’
Appliquons cela à mon ensemble de données de température. Actuellement, il n’y a pas de doublons, nous allons donc simplement récupérer notre même entrée.
import numpy as np
temps = np.array([30, 32, 29, 35, 36, 33, 31])
np.unique(temps)Sortie : tableau ([29, 30, 31, 32, 33, 35, 36])
Remarquez également comment les chiffres sont organisés en conséquence – par ordre croissant.
Vous pouvez également demander à NumPy de compter combien de fois chaque valeur apparaît :
np.unique(temps, return_counts=True)Sortie : (tableau([29, 30, 31, 32, 33, 35, 36]), tableau([1, 1, 1, 1, 1, 1, 1]))
Conclusion
Jusqu’à présent, ce sont les fonctions sur lesquelles je suis tombé par hasard. Et je les trouve très utiles dans l’analyse des données. La beauté de NumPy est que plus vous jouez avec, plus vous découvrez ces minuscules one-liners qui remplacent les pages de code. Alors la prochaine fois que vous vous disputerez avec des données ou que vous déboguerez un ensemble de données désordonné, éloignez-vous un peu des Pandas et essayez d’utiliser l’une de ces fonctions. Merci d’avoir lu!
You may also like


