
Apprentissage fédéré et schémas d’agrégation personnalisés
Lire ce document ?
Ce document est destiné praticiens, chercheurs et ingénieurs de l’apprentissage automatique intéressé à explorer schémas d’agrégation personnalisés dans l’apprentissage fédéré. Il est particulièrement utile pour ceux qui souhaitent concevoir, tester et analyser de nouvelles méthodes d’agrégation dans des environnements réels et distribués.
Introduction
Apprentissage automatique (ML) continue de stimuler l’innovation dans divers domaines tels que la santé, la finance et la défense. Cependant, même si les modèles de ML s’appuient largement sur de grands volumes de données centralisées de haute qualité, les préoccupations concernant la confidentialité, la propriété et la conformité réglementaire des données restent des obstacles importants.
Apprentissage fédéré (FL) répond à ces défis en permettant la formation de modèles sur des ensembles de données distribués, permettant ainsi aux données de rester décentralisées tout en contribuant à un modèle mondial partagé. Cette approche décentralisée rend FL particulièrement utile dans les domaines sensibles où la centralisation des données est peu pratique ou limitée.
Pour tirer pleinement parti de FL, comprendre et concevoir agrégation personnalisée les schémas sont importants. Une agrégation efficace influence non seulement la précision et la robustesse du modèle, mais gère également des problèmes tels que l’hétérogénéité des données, la fiabilité des clients et le comportement contradictoire. L’analyse et la création de méthodes d’agrégation sur mesure constituent donc une étape clé vers l’optimisation des performances et la garantie de l’équité dans les contextes fédérés.
Dans mon article précédent, nous avons exploré le paysage des cyberattaques dans l’apprentissage fédéré et en quoi il diffère du ML centralisé traditionnel. Cette discussion a introduit Mise à l’échelleest open source boîte à outils de simulation d’attaquequi aide les chercheurs et les praticiens à analyser l’impact de différents types d’attaques et à évaluer les limites des systèmes d’atténuation existants, en particulier dans des conditions difficiles telles qu’un déséquilibre extrême des données, des distributions non IID et la présence de retardataires ou de participants tardifs.
Cependant, ce premier article n’expliquait pas comment concevoir, implémenter et tester vos propres schémas dans des environnements distribués et réels.
Cela peut sembler complexe, mais cet article propose un guide rapide, étape par étape, couvrant les concepts de base nécessaires à la conception et au développement de schémas d’agrégation personnalisés pour les paramètres fédérés du monde réel.
Que sont Fonctions du serveur ?
Agrégateurs personnalisés sont des fonctions qui s’exécutent côté serveur d’une configuration d’apprentissage fédéré. Ils définissent la manière dont les mises à jour de modèles provenant des clients sont traitées, comme l’agrégation, la validation ou le filtrage, avant de produire le modèle global suivant. Fonction serveur est le terme utilisé dans la plateforme Scaleout Edge AI pour désigner les agrégateurs personnalisés.
Au-delà de la simple agrégation, les fonctions serveur permettent aux chercheurs et aux développeurs de concevoir de nouveaux systèmes intégrant la préservation de la confidentialité, l’équité, la robustesse et l’efficacité de la convergence. En personnalisant cette couche, on peut également expérimenter des mécanismes de défense innovants, des règles d’agrégation adaptatives ou des méthodes d’optimisation adaptées à des données et à des scénarios de déploiement spécifiques.
Les fonctions de serveur constituent le mécanisme de la plateforme Scaleout Edge AI permettant de mettre en œuvre des schémas d’agrégation personnalisés. En plus de cette flexibilité, la plateforme comprend quatre agrégateurs intégrés : FedAvg (par défaut), FedAdam (FedOpt), FedYogi (FedOpt) et FedAdaGrad (FedOpt). La mise en œuvre des méthodes du Famille FedOpt suit l’approche décrite dans le document. Pour plus de détails, veuillez vous référer au documentation de la plateforme.
Création d’un schéma d’agrégation personnalisé
Dans cet article de blog, Je vais vous montrer comment vous pouvez créer et tester votre propre système d’atténuation des attaques à l’aide de la plateforme Edge AI de Scaleout. L’un des principaux catalyseurs à cet égard est la plateforme. Fonction serveur fonctionnalité.
Dans le cadre de cet article, l’accent sera mis sur la manière de développer et d’exécuter un processus d’agrégation personnalisé dans un environnement géographiquement distribué. Je vais ignorer la configuration de base et supposer que vous connaissez déjà la plateforme Scaleout. Si vous débutez, voici quelques ressources utiles :
Exemple de démarrage rapide FL : https://docs.scaleoutsystems.com/en/stable/quickstart.html
Architecture-cadre : https://docs.scaleoutsystems.com/en/stable/architecture.html
Référence de l’API client : https://docs.scaleoutsystems.com/en/stable/apiclient.html Serveur
Guide des fonctions : https://docs.scaleoutsystems.com/en/stable/serverfunctions.html
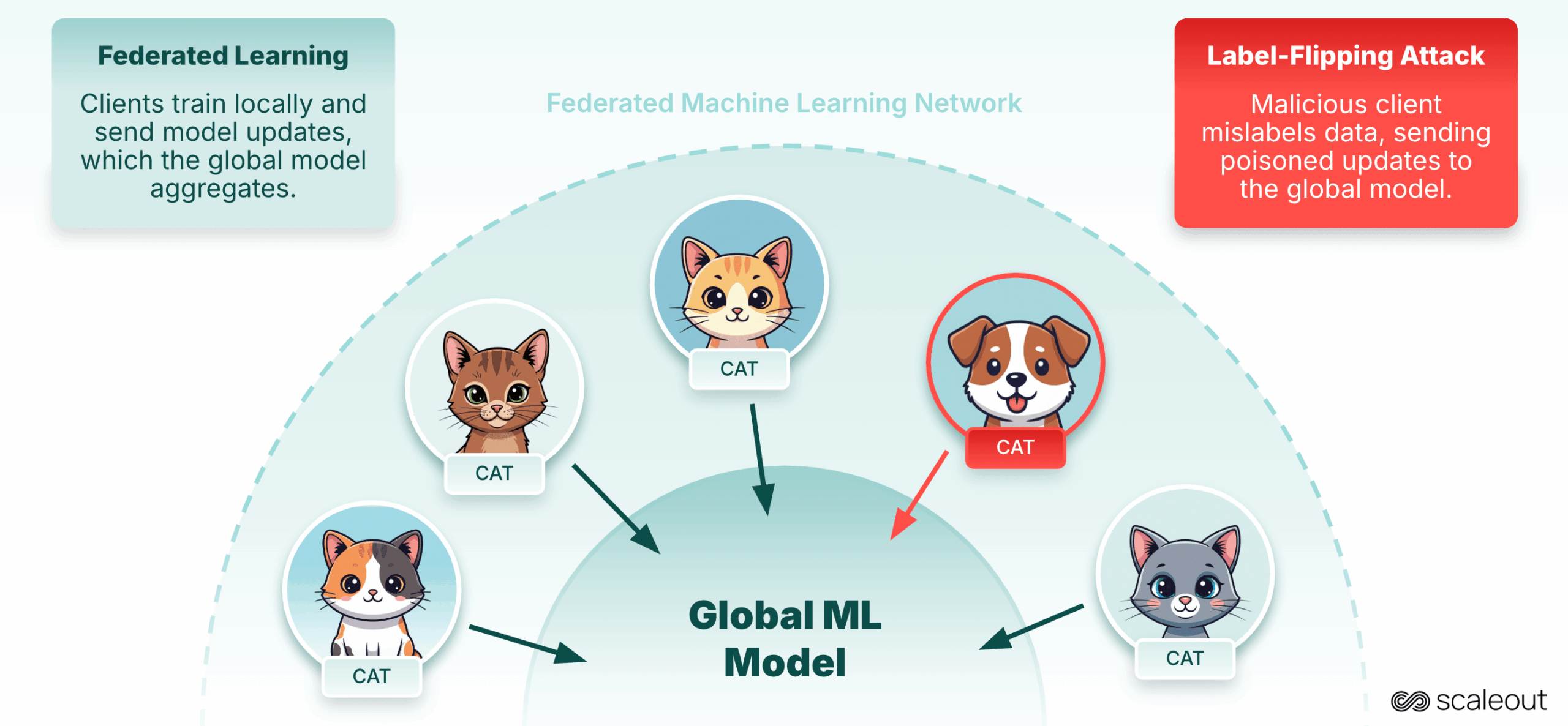
Exemple : attaque par retournement d’étiquette
Considérons une attaque concrète, Label-Flipping. Dans ce scénario, un client malveillant modifie intentionnellement les étiquettes de son ensemble de données local (par exemple, en transformant « chat » en « chien »). Lorsque ces mises à jour empoisonnées sont envoyées au serveur, le modèle global apprend des modèles incorrects, ce qui entraîne une précision et une fiabilité réduites.
Pour cette expérience, nous avons utilisé le MNIST ensemble de données open source, divisé en six partitions, chacune affectée à un client distinct. le client-6 agit comme un participant malveillant en retournant les étiquettes dans ses données locales, en les utilisant pour la formation et en envoyant le modèle local résultant à l’agrégateur.

| Client malveillant | IDENTIFIANT |
|---|---|
| client-6 | 07505d04-08a5-4453-ad55-d541e9e4ef57 |
Ici, vous pouvez voir un exemple de point de données (une image en niveaux de gris) du client-6, où les étiquettes ont été intentionnellement inversées. En modifiant les étiquettes, ce client tente de corrompre le modèle global lors du processus d’agrégation.

Tâche
Empêchez le client-6 d’interférer avec le développement du modèle global.
Atténuation avec similarité cosinus
Pour contrer cela, nous utilisons un approche basée sur la similarité cosinus à titre d’exemple. L’idée est simple : comparer le vecteur de mise à jour de chaque client avec le modèle global (étape 1). Si le score de similarité est inférieur à un seuil prédéfini (s̄ᵢ < 𝓣), la mise à jour provient probablement d'un client malveillant (étapes 2 à 4). Dans la dernière étape (étape 5), la contribution de ce client est exclue du processus d'agrégation, qui dans ce cas utilise un système de moyenne fédérée pondérée (FedAVG).

Note: Il s’agit d’un schéma simple d’atténuation des attaques, principalement destiné à démontrer la flexibilité de la prise en charge de l’agrégation personnalisée dans des scénarios d’apprentissage fédéré réalistes. Le même système peut ne pas être efficace dans les cas très difficiles, tels que ceux comportant des ensembles de données déséquilibrés ou des conditions non-IID.
Le Implémentation Python ci-dessous illustre le flux de travail de l’agrégateur personnalisé : identification des clients en ligne (étape 1), calcul des scores de similarité cosinus (étapes 2 à 3), exclusion du client malveillant (étape 4) et réalisation d’une moyenne pondérée fédérée (étape 5).
Étape 1
# --- Compute deltas (client - previous_global) ---
prev_flat = self._flatten_params(previous_global)
flat_deltas, norms = [], []
for params in client_params:
flat = self._flatten_params(params)
delta = flat - prev_flat
flat_deltas.append(delta)
norms.append(np.linalg.norm(delta))Étapes 2 et 3
# --- Cosine similarity matrix ---
similarity_matrix = np.zeros((num_clients, num_clients), dtype=float)
for i in range(num_clients):
for j in range(i + 1, num_clients):
denom = norms[i] * norms[j]
sim = float(np.dot(flat_deltas[i], flat_deltas[j]) / denom) if denom > 0 else 0.0
similarity_matrix[i, j] = sim
similarity_matrix[j, i] = sim
# --- Average similarity per client ---
avg_sim = np.zeros(num_clients, dtype=float)
if num_clients > 1:
avg_sim = np.sum(similarity_matrix, axis=1) / (num_clients - 1)
for cid, s in zip(client_ids, avg_sim):
logger.info(f"Round {self.round}: Avg delta-cosine similarity for {cid}: {s:.4f}")Étape 4
# --- Mark suspicious clients ---
suspicious_indices = [i for i, s in enumerate(avg_sim) if s < self.similarity_threshold]
suspicious_clients = [client_ids[i] for i in suspicious_indices]
if suspicious_clients:
logger.warning(f"Round {self.round}: Excluding suspicious clients: {suspicious_clients}")
# --- Keep only non-suspicious clients ---
keep_indices = [i for i in range(num_clients) if i not in suspicious_indices]
if len(keep_indices) < 3: # safeguard
logger.warning("Too many exclusions, falling back to ALL clients.")
keep_indices = list(range(num_clients))
kept_client_ids = [client_ids[i] for i in keep_indices]
logger.info(f"Round {self.round}: Clients used for FedAvg: {kept_client_ids}")Étape 5
# === Weighted FedAvg ===
weighted_sum = [np.zeros_like(param) for param in previous_global]
total_weight = 0
for i in keep_indices:
client_id = client_ids[i]
client_parameters, metadata = client_updates[client_id]
num_examples = metadata.get("num_examples", 1)
total_weight += num_examples
for j, param in enumerate(client_parameters):
weighted_sum[j] += param * num_examples
if total_weight == 0:
logger.error("Aggregation failed: total_weight = 0.")
return previous_global
new_global = [param / total_weight for param in weighted_sum]
logger.info("Models aggregated with FedAvg + cosine similarity filtering")
return new_globalLe code complet est disponible sur Github : https://github.com/sztoor/server_functions_cosine_similarity_example.git
Activation étape par étape des fonctions du serveur
- Connectez-vous à Studio évolutif et créez un nouveau projet.
- Téléchargez le Package de calcul et Modèle de graine au projet.
- Connectez les clients au Studio en installant Scaleout bibliothèques côté client via pépin ( # pip install fedn) . J’ai connecté six clients.
Note: Pour les étapes 1 à 3, veuillez vous référer au Guide de démarrage rapide pour des instructions détaillées.
- Clonez le référentiel Github à partir du lien fourni. Cela vous donnera deux fichiers Python :
- server_functions.py – contient le schéma d’agrégation basé sur la similarité cosinus.
- scaleout_start_session.py – se connecte au Studio, pousse la fonction serveur locale et démarre une session de formation basée sur des paramètres prédéfinis (par exemple, 5 tours, délai d’attente de 180 secondes).
- Exécutez le script scaleout_start_session.py.
Pour plus de détails sur ces étapes, reportez-vous au site officiel Fonctions du serveur Guide.
Résultat et discussion
Les étapes à suivre lors de l’exécution scaleout_start_session.py sont décrites ci-dessous.
Dans cette configuration, six clients étaient connectés au studio, avec client-6 en utilisant un ensemble de données délibérément inversé pour simuler un comportement malveillant. Les journaux de Scaleout Studio fournissent une vue détaillée de Fonction serveur l’exécution et comment le système répond pendant l’agrégation. Dans Section 1les journaux montrent que le serveur a reçu avec succès les modèles de tous les clients, confirmant que la communication et le téléchargement des modèles fonctionnaient comme prévu. Section 2 présente les scores de similarité pour chaque client. Ces scores quantifient dans quelle mesure la mise à jour de chaque client s’aligne sur la tendance globale, fournissant ainsi une mesure permettant de détecter les anomalies.
Section 1
2025-10-20 11:35:08 [INFO] Received client selection request.
2025-10-20 11:35:08 [INFO] Clients selected: ['eef3e17f-d498-474c-aafe-f7fa7203e9a9', 'e578482e-86b0-42fc-8e56-e4499e6ca553', '7b4b5238-ff67-4f03-9561-4e16ccd9eee7', '69f6c936-c784-4ab9-afb2-f8ccffe15733', '6ca55527-0fec-4c98-be94-ef3ffb09c872', '07505d04-08a5-4453-ad55-d541e9e4ef57']
2025-10-20 11:35:14 [INFO] Received previous global model
2025-10-20 11:35:14 [INFO] Received metadata
2025-10-20 11:35:14 [INFO] Received client model from client eef3e17f-d498-474c-aafe-f7fa7203e9a9
2025-10-20 11:35:14 [INFO] Received metadata
2025-10-20 11:35:15 [INFO] Received client model from client e578482e-86b0-42fc-8e56-e4499e6ca553
2025-10-20 11:35:15 [INFO] Received metadata
2025-10-20 11:35:15 [INFO] Received client model from client 07505d04-08a5-4453-ad55-d541e9e4ef57
2025-10-20 11:35:15 [INFO] Received metadata
2025-10-20 11:35:15 [INFO] Received client model from client 69f6c936-c784-4ab9-afb2-f8ccffe15733
2025-10-20 11:35:15 [INFO] Received metadata
2025-10-20 11:35:15 [INFO] Received client model from client 6ca55527-0fec-4c98-be94-ef3ffb09c872
2025-10-20 11:35:16 [INFO] Received metadata
2025-10-20 11:35:16 [INFO] Received client model from client 7b4b5238-ff67-4f03-9561-4e16ccd9eee7Section 2
2025-10-20 11:35:16 [INFO] Receieved aggregation request: aggregate
2025-10-20 11:35:16 [INFO] Round 0: Avg delta-cosine similarity for eef3e17f-d498-474c-aafe-f7fa7203e9a9: 0.7498
2025-10-20 11:35:16 [INFO] Round 0: Avg delta-cosine similarity for e578482e-86b0-42fc-8e56-e4499e6ca553: 0.7531
2025-10-20 11:35:16 [INFO] Round 0: Avg delta-cosine similarity for 07505d04-08a5-4453-ad55-d541e9e4ef57: -0.1346
2025-10-20 11:35:16 [INFO] Round 0: Avg delta-cosine similarity for 69f6c936-c784-4ab9-afb2-f8ccffe15733: 0.7528
2025-10-20 11:35:16 [INFO] Round 0: Avg delta-cosine similarity for 6ca55527-0fec-4c98-be94-ef3ffb09c872: 0.7475
2025-10-20 11:35:16 [INFO] Round 0: Avg delta-cosine similarity for 7b4b5238-ff67-4f03-9561-4e16ccd9eee7: 0.7460Section 3
2025-10-20 11:35:16 ⚠️ [WARNING] Round 0: Excluding suspicious clients: ['07505d04-08a5-4453-ad55-d541e9e4ef57']Article 4
2025-10-20 11:35:16 [INFO] Round 0: Clients used for FedAvg: ['eef3e17f-d498-474c-aafe-f7fa7203e9a9', 'e578482e-86b0-42fc-8e56-e4499e6ca553', '69f6c936-c784-4ab9-afb2-f8ccffe15733', '6ca55527-0fec-4c98-be94-ef3ffb09c872', '7b4b5238-ff67-4f03-9561-4e16ccd9eee7']
2025-10-20 11:35:16 [INFO] Models aggregated with FedAvg + cosine similarity filteringSection 3 souligne que client-6 (ID…e4ef57) a été identifié comme malveillant. Le message d’avertissement indique que ce client serait exclu du processus d’agrégation. Cette exclusion est justifiée par son score de similarité extrêmement faible de –0,1346le plus bas parmi tous les clients, et par la valeur seuil (𝓣) définie dans la fonction serveur. En supprimant le client-6, l’étape d’agrégation garantit que le modèle global n’est pas affecté par les mises à jour aberrantes. Article 4 répertorie ensuite les ID client inclus dans l’agrégation, confirmant que seuls les clients de confiance ont contribué au modèle global mis à jour.
Tâche accomplie
le client-6 a été exclu avec succès du processus d’agrégation à l’aide du schéma d’agrégation personnalisé.
Avec les messages du journal, la plateforme fournit des informations riches par client qui améliorent la compréhension du comportement des clients. Ceux-ci incluent la perte et la précision de la formation par client, les mesures de performances globales du modèle et les temps de formation pour chaque client. Une autre fonctionnalité clé est le suivi du modèle, qui suit les mises à jour du modèle au fil du temps et permet une analyse détaillée de l’impact de chaque client sur le modèle global. Ensemble, les sections et les données supplémentaires fournissent une vue complète des contributions des clients, illustrant clairement la distinction entre les clients normaux et les clients malveillants. client-6 (ID…e4ef57)et démontrant l’efficacité de la fonction serveur pour atténuer les attaques potentielles.

(image créée par l’auteur).


Les graphiques de précision et de perte de formation côté client mettent en évidence les performances de chaque client. Ils montrent que le client-6 s’écarte considérablement des autres. L’inclure dans le processus d’agrégation nuirait aux performances du modèle global.
Résumé
Cet article de blog souligne l’importance des agrégateurs personnalisés pour répondre à des besoins particuliers et permet le développement de modèles robustes, efficaces et très précis dans des paramètres d’apprentissage automatique fédéré. Il souligne également l’intérêt de tirer parti des éléments de base existants plutôt que de repartir entièrement de zéro et de consacrer beaucoup de temps à des composants qui ne sont pas essentiels à l’idée de base.
Federated Learning offre un moyen puissant de débloquer des ensembles de données difficiles, voire impossibles, à centraliser en un seul endroit. Des études comme celle-ci démontrent que même si cette approche est très prometteuse, elle nécessite également une compréhension approfondie des systèmes sous-jacents. Heureusement, il existe des plates-formes prêtes à l’emploi qui facilitent l’exploration de cas d’utilisation réels, l’expérimentation de différents schémas d’agrégation et la conception de solutions adaptées à des besoins spécifiques.
Liens utiles
Détails de l’auteur :
Salman Toor
CTO et co-fondateur, Mise à l’échelle.
professeur agrégé
Département des technologies de l’information,
Université d’Uppsala, Suède
LinkedIn Google Scholar
You may also like


