
Construire un agent IA personnel en quelques heures
J’ai été tellement surpris par la rapidité avec laquelle les constructeurs individuels peuvent désormais expédier des prototypes réels et utiles.
Des outils tels que Claude Code, Google AntiGravity et l’écosystème croissant qui les entoure ont franchi un seuil : vous pouvez inspecter ce que d’autres construisent en ligne et réaliser à quelle vitesse vous pouvez construire aujourd’hui.
Au cours des dernières semaines, j’ai commencé à réserver une à deux heures par jour exclusivement pour construire avec ma pile AI-first :
- Google AntiGravité
- Google Gémeaux Pro
- Modèles Claude accessibles via AntiGravity
Cette configuration a fondamentalement changé ma façon de penser le prototypage, la vitesse d’itération et ce qu’un « agent d’IA personnel » peut faire de manière réaliste aujourd’hui. Plus important encore, cela m’a ramené au codage et à la construction pratiques, quelque chose que j’avais personnellement sacrifié une fois que mon rôle chez DareData était passé à la gestion et à l’orchestration plutôt qu’à l’exécution.
Individuellement, cette révolution a été une bénédiction pour quelqu’un qui allait toujours dériver vers des rôles de direction. Cela supprime le compromis que j’avais accepté : développer une entreprise signifiait abandonner complètement la construction. Je n’ai plus à choisir entre construire et gérer, ils se renforcent mutuellement.
Mais il y a ici une implication plus large pour les personnes qui sont « juste » en train de se développer. Si les agents d’IA gèrent de plus en plus l’exécution, alors la mise en œuvre pure ne suffit plus. Les développeurs seront poussés (qu’ils le veuillent ou non) vers la coordination, la prise de décision et… la gestion – quelque chose que les contributeurs individuels détestent par cœur. En d’autres termes, les compétences de gestion font partie de la pile technique et les agents d’IA font partie du contexte géré.
Ce qui m’a le plus surpris, c’est à quel point mes compétences en gestion existantes se sont révélées transférables :
- Guider l’agent plutôt que le microgérer
- Demander des résultats plutôt que des instructions
- Cartographier, prioriser et pointer les zones grises
En pratique, je gère et coordonne un employé virtuel. Je peux profondément influencer certaines parties de son travail tout en restant presque entièrement ignorant des autres – et ce n’est pas un bug, c’est une fonctionnalité importante. Dans mon assistant personnel d’IA, par exemple, je peux raisonner clairement sur le backend, mais je n’ai pratiquement aucune idée du frontend. Le système fonctionne toujours, car mon rôle n’est plus de tout savoir, mais d’orienter le système dans la bonne direction.
Ceci est directement analogue à la façon dont je coordonne les personnes au sein de l’entreprise. À mesure que DareData se développe, nous n’embauchons pas de répliques de fondateurs. Nous embauchons intentionnellement des personnes capables de faire des choses que nous ne pouvons pas faire et, avec le temps, des choses que nous n’apprendrons jamais suffisamment en profondeur pour bien les faire.

Assez d’introspection sur la gestion. Regardons ce que je construis car c’est pour cela que vous êtes ici :
- Un assistant personnel d’IA conçu autour de mes routines réelles, et non un modèle de productivité générique. Il s’adapte à ma façon de travailler, de penser et de prendre des décisions.
- Une application mobile qui recommande un album de musique par semaine, sans système de recommandation traditionnel. Pas de renforcement de la zone de confort et cela m’aide à élargir mes zones d’écoute.
- Un jeu mobile construit autour d’un seul personnage progressant dans des donjons en couches, développé principalement comme un terrain de jeu créatif plutôt que comme un produit commercial.
La partie intéressante est que, même si je suis à l’aise avec le codage de la majeure partie du backend, le développement front-end n’est pas une compétence que je possède – et si j’étais obligé de le faire moi-même, ces projets ralentiraient de quelques heures à plusieurs jours, ou tout simplement ne seraient jamais livrés.
Cette contrainte est désormais largement hors de propos. Avec cette nouvelle pile, l’imagination devient le véritable goulot d’étranglement. Le coût de « ne pas connaître » une couche entière s’est effondré.
Donc, dans le reste de cet article, je vais présenter mon assistant personnel d’IA : ce qu’il fait, comment il est structuré et pourquoi il fonctionne pour moi. Mon objectif est de le rendre open source une fois qu’il sera stabilisé, afin que d’autres puissent l’adapter à leurs propres flux de travail. C’est actuellement très spécifique à ma vie, mais cette spécificité est intentionnelle, et la rendre plus générale fait partie de l’expérience.
Rencontrez Fernão
Fernão Lopes était un chroniqueur de la monarchie portugaise. J’ai délibérément choisi un personnage historique portugais : les Portugais ont l’habitude d’attacher des noms historiques à presque tout. Si cela ressemble à un stéréotype portugais, c’est intentionnel.
Fernão est portugais mais parle réellement anglais, appelez-le un chroniqueur moderne du 21e siècle.

À ce stade, je fais deux choses que j’évite habituellement : anthropomorphiser l’IA et m’appuyer sur un instinct de dénomination très portugais. Considérez cela comme un signe inoffensif de mon vieillissement.
Cela mis à part, que fait réellement Fernão pour moi ? Le meilleur endroit pour commencer est sa première page.

Fernão est un mec cool qui s’occupe actuellement de cinq tâches :
- Horaire de la journée: planifie ma journée en rassemblant des calendriers, des tâches et des objectifs, puis en les transformant en quelque chose que je peux suivre.
- Assistante de rédaction: m’aide à réviser et à nettoyer les brouillons d’articles de blog et d’autres textes.
- Assistant de portefeuille: suggère des sociétés ou des ETF à ajouter en fonction des besoins de rééquilibrage et de ce qui se passe dans le monde macro (sans prétendre être une boule de cristal).
- Organisateur financier: extrait les dépenses de mes relevés bancaires et télécharge le tout dans l’application Cashew, m’épargnant ainsi une autre tâche qui me prenait environ 3 à 4 heures par mois.
- Abonnements et réductions: garde une trace de tous mes abonnements et fait apparaître les réductions ou avantages que j’ai probablement mais que je ne me souviens jamais d’utiliser.
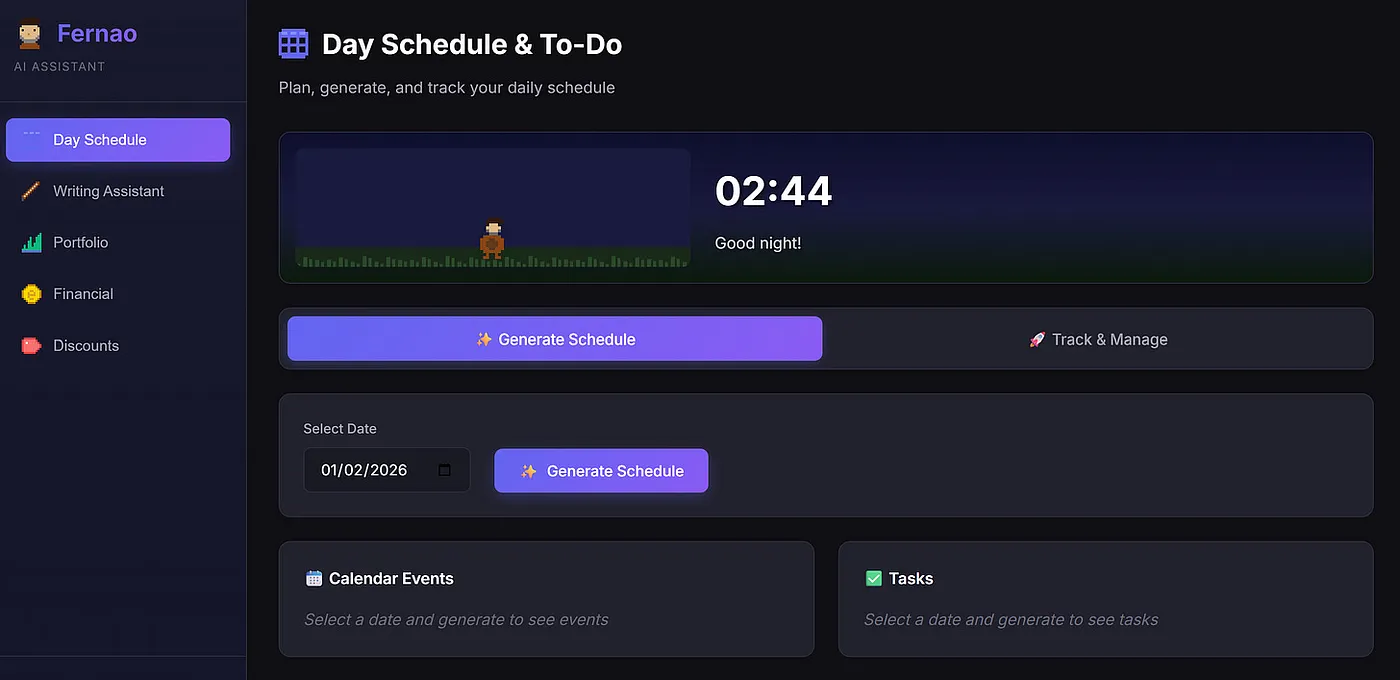
Dans cet article, je me concentrerai sur l’application Day Schedule.
Pour le moment, Fernão Horaire de la journée fait trois choses simples :
- Récupère mon calendrier, y compris toutes les réunions programmées
- Extrait mes tâches de Microsoft To Do
- Récupère mes résultats clés personnels de Notion
Tout cela est connecté via des API. L’idée est simple : chaque jour, Fernão examine mes contraintes, mes priorités et mes engagements, puis génère pour moi le meilleur planning possible.

Générer un planning dans le front-end est assez simple (tout le front-end était codé en ambiance). Voici le bouton Générer un planning :

Une fois que j’ai cliqué sur Générer un programme, Fernão commence à cuisiner en arrière-plan :

Les étapes sont alors, dans l’ordre : récupérer mon calendrier, mes tâches et mes données Notion.
Le point suivant est également celui où les connaissances de base en matière de codage commencent vraiment à avoir de l’importance, non pas parce que tout le code suivant ne fonctionne pas, mais parce que vous devez comprendre quoi se passe et où les choses peuvent éventuellement se briser ou nécessiter des améliorations.
Commençons par la récupération du calendrier. Pour le moment, cela est géré par une seule et gigantesque fonction créée par Claude qui est complètement non optimisé.
def get_events_for_date(target_date=None):
"""
Fetches events for a specific date from Google Calendar via ICS feeds.
Args:
target_date: datetime.date object for the target day. If None, uses today.
Returns a list of event dictionaries.
"""
# Hardcoded calendar URLs (not using env var to avoid placeholder issues)
CALENDAR_URLS = [
'cal1url',
'call2url'
]
LOCAL_TZ = os.getenv('TIMEZONE', 'Europe/Lisbon')
# Get timezone
local = tz.gettz(LOCAL_TZ)
# If no target date provided, use today
if target_date is None:
target_date = datetime.now(local).date()
# Create datetime for the target day boundaries
day_start = datetime.combine(target_date, datetime.min.time()).replace(tzinfo=local)
day_end = day_start + timedelta(days=1)
# Debug: Print the date range we're checking
print(f"\n[Debug] Checking calendars for date: {target_date.strftime('%Y-%m-%d')}")
print(f" Start: {day_start.strftime('%Y-%m-%d %H:%M %Z')}")
print(f" End: {day_end.strftime('%Y-%m-%d %H:%M %Z')}")
print(f" Timezone: {LOCAL_TZ}")
all_events = []
# Fetch from each calendar
for idx, cal_url in enumerate(CALENDAR_URLS, 1):
calendar_name = f"Calendar {idx}"
print(f"\n[Debug] Fetching {calendar_name}...")
try:
# Load calendar from ICS URL with adequate timeout
r = requests.get(cal_url, timeout=30)
r.raise_for_status()
cal = Calendar(r.text)
events_found_this_cal = 0
total_events_in_cal = len(list(cal.events))
print(f" Total events in {calendar_name}: {total_events_in_cal}")
# Use timeline to efficiently filter events for target day's date range
# Convert local times to UTC for timeline filtering
day_start_utc = day_start.astimezone(timezone.utc)
day_end_utc = day_end.astimezone(timezone.utc)
# Get events in target day's range using timeline
days_timeline = cal.timeline.overlapping(day_start_utc, day_end_utc)
for e in days_timeline:
if not e.begin:
continue
# Get event start time
start = e.begin.datetime
if start.tzinfo is None:
start = start.replace(tzinfo=timezone.utc)
# Convert to local timezone
start_local = start.astimezone(local)
# Debug: Print first few events to see dates
if events_found_this_cal < 3:
print(f" Event: '{e.name}' at {start_local.strftime('%Y-%m-%d %H:%M')}")
# Get end time
end = e.end.datetime if e.end else None
end_local = end.astimezone(local) if end else None
all_events.append({
"title": e.name,
"start": start_local.strftime("%H:%M"),
"end": end_local.strftime("%H:%M") if end_local else None,
"location": e.location or "",
"description": e.description or ""
})
events_found_this_cal += 1
print(f" [OK] Found {events_found_this_cal} event(s) for target day in {calendar_name}")
except requests.exceptions.RequestException as e:
print(f" [X] Network error fetching {calendar_name}: {str(e)}")
continue
except Exception as e:
print(f" [X] Error processing {calendar_name}: {type(e).__name__}: {str(e)}")
continue
# Sort by start time
all_events.sort(key=lambda x: x["start"])
# Print all events in detail
if all_events:
print(f"\n[Google Calendar] Found {len(all_events)} event(s) for {target_date.strftime('%Y-%m-%d')}:")
print("-" * 60)
for event in all_events:
time_str = f"{event['start']}-{event['end']}" if event['end'] else event['start']
location_str = f" @ {event['location']}" if event['location'] else ""
print(f" {time_str} | {event['title']}{location_str}")
print("-" * 60)
else:
print(f"\n[Google Calendar] No events for {target_date.strftime('%Y-%m-%d')}")
return all_eventsEn tant que développeur Python, tous les print les déclarations me donnent la nausée. Mais c’est un problème pour la prochaine phase de Fernão : refactoriser et optimiser le code une fois que la logique du produit est solide.
C’est aussi là que je vois vraiment le humain + IA travail dynamique. Je peux immédiatement repérer plusieurs façons d’améliorer cette fonction (réduire la verbosité, réduire la latence inutile, nettoyer le flux), mais bien y parvenir nécessite encore du temps, du jugement et de l’intention. L’IA m’aide à avancer rapidement ; ça ne remplace pas le besoin de savoir quoi extraordinaire on dirait.
Pour l’instant, je n’ai pas passé beaucoup de temps à l’optimiser, et c’est un choix conscient. Malgré ses aspérités, la fonction fait exactement ce qu’elle doit faire : elle extrait les données de mes calendriers et transmet les informations de la réunion à Fernão, permettant ainsi tout ce qui suit.
Ensuite, Fernão extrait mes tâches de Microsoft To Do. C’est là que vivent mes tâches quotidiennes (les petites choses concrètes qui doivent être faites et qui structurent une journée précise). Tout cela est configuré directement dans l’application Microsoft To Do, qui constitue un élément essentiel de mon flux de travail quotidien.
Si vous êtes curieux de connaître le système de productivité plus large derrière cela, j’en ai parlé dans un article connexe sur le frère de ce blog (Wait a Day) lié ci-dessous.
Alors, regardons une autre fonction verbalisée :
def get_tasks(target_date=None):
"""
Fetches tasks from Microsoft To Do for a specific date (tasks due on or before that date).
Args:
target_date: datetime.date object for the target day. If None, uses today.
Returns a list of task dictionaries.
"""
CLIENT_ID = os.getenv('MS_CLIENT_ID', 'CLIENT_ID_KEY')
AUTHORITY = "https://login.microsoftonline.com/consumers"
SCOPES = ['Tasks.ReadWrite', 'User.Read']
# Setup persistent token cache
cache = SerializableTokenCache()
cache_file = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(__file__))), '.token_cache.bin')
if os.path.exists(cache_file):
with open(cache_file, 'r') as f:
cache.deserialize(f.read())
# Authentication with persistent cache
app = PublicClientApplication(CLIENT_ID, authority=AUTHORITY, token_cache=cache)
accounts = app.get_accounts()
result = None
if accounts:
result = app.acquire_token_silent(SCOPES, account=accounts[0])
if not result or "access_token" not in result:
for account in accounts:
app.remove_account(account)
result = None
if not result:
flow = app.initiate_device_flow(scopes=SCOPES)
if "user_code" not in flow:
print(f"[MS To Do] Failed to create device flow: {flow.get('error_description', 'Unknown error')}")
return []
if "message" in flow:
print(flow['message'])
result = app.acquire_token_by_device_flow(flow)
if not result or "access_token" not in result:
print(f"[MS To Do] Authentication failed: {result.get('error_description', 'No access token') if result else 'No result'}")
return []
headers = {"Authorization": f"Bearer {result['access_token']}"}
# Get date boundaries for target date
# If no target date provided, use today
if target_date is None:
from datetime import date
target_date = date.today()
# Convert date to datetime in UTC for comparison
now = datetime.now(timezone.utc)
target_day_end = datetime.combine(target_date, datetime.max.time()).replace(tzinfo=timezone.utc)
# Fetch all lists
lists_r = requests.get("https://graph.microsoft.com/v1.0/me/todo/lists", headers=headers)
if lists_r.status_code != 200:
return []
lists_res = lists_r.json().get("value", [])
all_tasks = []
# Fetch tasks from all lists with server-side filtering
for task_list in lists_res:
list_id = task_list["id"]
list_name = task_list["displayName"]
# Simple filter - just get incomplete tasks
params = {"$filter": "status ne 'completed'"}
tasks_r = requests.get(
f"https://graph.microsoft.com/v1.0/me/todo/lists/{list_id}/tasks",
headers=headers,
params=params
)
if tasks_r.status_code != 200:
continue
tasks = tasks_r.json().get("value", [])
# Filter and transform tasks
for task in tasks:
due_date_obj = task.get("dueDateTime")
if not due_date_obj:
continue
due_date_str = due_date_obj.get("dateTime")
if not due_date_str:
continue
try:
due_date = datetime.fromisoformat(due_date_str.split('.')[0])
if due_date.tzinfo is None:
due_date = due_date.replace(tzinfo=timezone.utc)
# Include all tasks due on or before the target date
if due_date <= target_day_end:
# Determine status based on target date
target_day_start = datetime.combine(target_date, datetime.min.time()).replace(tzinfo=timezone.utc)
if due_date < target_day_start:
status = "OVERDUE"
elif due_date <= target_day_end:
status = f"DUE {target_date.strftime('%Y-%m-%d')}"
else:
status = "FUTURE"
all_tasks.append({
"list": list_name,
"title": task["title"],
"due": due_date.strftime("%Y-%m-%d"),
"importance": task.get("importance", "normal"),
"status": status
})
except Exception as e:
continue
# Print task summary
if all_tasks:
print(f"[MS To Do] {len(all_tasks)} task(s) for {target_date.strftime('%Y-%m-%d')} or overdue")
else:
print(f"[MS To Do] No tasks due on {target_date.strftime('%Y-%m-%d')} or overdue")
# Save token cache for next run
if cache.has_state_changed:
with open(cache_file, 'w') as f:
f.write(cache.serialize())
return all_tasksCette fonction récupère une liste complète de mes tâches pour la journée en cours (et en retard des jours précédents) — voici un exemple de leur apparence dans to-do :

Après avoir extrait les tâches de To Do, je veux aussi que Fernão comprenne où j’essaye d’allerpas seulement ce qui est sur la liste d’aujourd’hui. Pour cela, il récupère mes objectifs directement depuis une page Notion où j’ai les résultats clés de mon année.
Voici un exemple de la façon dont ces objectifs sont structurés :
- la première colonne montre ma référence au début de l’année,
- la dernière colonne définit la cible que je souhaite atteindre,
- et la colonne de droite suit mes progrès actuels.
L’échantillon ci-dessous indique le nombre d’articles de blog que je souhaite écrire pour vous cette année, ainsi que le nombre total de livres que je souhaite vendre sur mes trois titres.
Cela donne à Fernão un contexte plus large sur les priorités dans les tâches, comme vous le verrez dans l’invite de création du calendrier.

Au fait, en écrivant cet article, j’ai fini par ajouter un petit widget à l’application. Si nous construisons un assistant personnel, autant lui donner une certaine personnalité.
J’ai donc demandé aux Gémeaux :
« Pouvez-vous ajouter une animation amusante pendant que l’application récupère les événements du calendrier, vérifie les tâches et extrait les données Notion ? Peut-être un petit widget de Fernão remuant une marmite, avec la légende « Fernão cuisine ».»

Une fois ce cycle terminé, les tâches et les événements du calendrier sont collectés et affichés avec succès dans le front-end de Fernão (un échantillon des tâches et des réunions de ma journée est présenté ci-dessous).

Et maintenant la partie amusante : avec des calendriers, des tâches et des objectifs en main, Fernão compose toute ma journée en un seul plan magique :
07:30-09:30 | Gym
09:30-09:40 | Check Timesheets on Odoo (Due: 2026-02-04)
09:40-09:55 | Review Tasks in To-Do - [Organization Task] (Due: 2026-02-04)
09:55-10:15 | Read Feedly Stuff - [News Catchup] (Due: 2026-02-04)
10:15-10:30 | Write culture doc, inspiration: https://pt.slideshare.net/slideshow/culture-1798664/1798664 (Due: 2026-02-04)
10:30-10:45 | Answer LinkedIns - [Organization Task] (Due: 2026-02-04)
10:45-11:00 | Check Looker (Due: 2026-02-04)
11:00-11:30 | This Week in AI Post (Due: 2026-02-04)
11:30-12:00 | Prepare Podcast Decoding AI
12:00-13:00 | Podcast Decoding AI - Ivo Bernardo, DareData (Event)
13:00-14:00 | Lunch Break
14:00-14:30 | Candidate 1 (name hidden) and Ivo Bernardo @ Google Meet (Event)
14:30-18:00 | Prepare DareData State of the Union
18:00-18:30 | Candidate 2 (name hidden) and Ivo Bernardo @ Google Meet (Event)
18:30-19:00 | Candidate 3 (name hidden) and Ivo Bernardo @ Google Meet (Event)
19:00-19:30 | Candidate 4 (name hidden) and Ivo Bernardo @ Google Meet (Event)
19:30-20:00 | Candidate 5 (name hidden) and Ivo Bernardo @ Google Meet (Event)
20:00-20:15 | Check Insider Trading Signals for Stock Ideas https://finviz.com/insidertrading?tc=1 (Overdue)
20:15-20:30 | Marketing Timeline (Overdue)
20:30-21:00 | Dinner Break
21:00-22:00 | Ler
22:00-22:15 | Close of Day - Review and prep for tomorrowC’est un de ces moments qui semble vraiment un peu magique. Non pas parce que la technologie est opaque, mais parce que le résultat est si propre. Un mélange désordonné de réunions, de tâches et d’objectifs à long terme se transforme en une journée que je peux réellement exécuter.
Ce qui le rend encore plus intéressant, c’est la simplicité de la dernière étape. Une fois que tout le gros du travail est effectué en arrière-plan (événements du calendrier, tâches, objectifs), je n’orchestre pas un pipeline complexe ou une chaîne d’invites. J’utilise une seule invite.
Cette invite prend tout ce que Fernão sait sur mes contraintes et mes priorités et en fait le jour que vous êtes sur le point de voir.
name: daily_schedule
description: Generate a daily schedule based on calendar events and tasks
model: gemini-2.5-flash-lite
temperature: 0.3
max_tokens: 8192variables:
- date_context
- events_str
- tasks_str
- context
- todo_context
- auto_context
- currently_reading
- notion_context
- is_today
template: |
You are my personal AI scheduling assistant. Help me plan my day!
**TARGET DATE:** Planning for {date_context}
**EVENTS (Fixed):**
{events_str}
**TASKS TO SCHEDULE:**
{tasks_str}
**MY CONTEXT:**
{context}
**TASK CONTEXT (how long tasks typically take):**
{todo_context}
**AUTO-LEARNED CONTEXT:**
{auto_context}
**CURRENTLY READING:**
{currently_reading}
**RESULTS & OBJECTIVES (from Notion):**
{notion_context}
**SCHEDULING RULES:**
1. **Cannot schedule tasks during calendar events** - events are fixed
2. **Mandatory breaks:**
- Lunch: 12:30-13:30 (reserve when possible)
- Dinner: 20:30-21:00
- Playing with my cat: 45-60 minutes somewhere scattered around the day
3. **Task fitting:** Intelligently fit tasks between events based on available time
4. **Time estimates:** Use the task context to estimate how long each task will take
5. **Working hours:** 09:30 to 22:00
6. **Start the schedule:** {is_today}
**YOUR JOB:**
1. Create a complete hourly schedule for {date_context}
2. Fit all tasks between events and breaks
3. **Prioritize tasks based on my Results & Objectives from Notion** - focus on what matters most
4. Be conversational - if you need more info about a task, ask me!
5. **Save learnings:** If I give you context about tasks, acknowledge it and say you'll remember it
**FORMAT:**
Start with a friendly greeting, then provide the schedule in this format:
```
09:30-10:00 | Task/Event
10:00-11:00 | Task/Event
...
```
After the schedule, ask if I need any adjustments or if you need clarification on any tasks.
Generate my day's schedule now, thanks!Et avec cela, Fernão cuisine définitivement :

Cela a été un système vraiment amusant à construire. Je continuerai à faire évoluer Fernão, en lui donnant de nouvelles responsabilités, en cassant des choses, en les réparant et en partageant ici ce que j’apprends en cours de route.
Au fil du temps, je prévois également d’écrire des tutoriels pratiques sur la façon de créer et de déployer vous-même des applications similaires. Pour l’instant, Fernão ne vit que sur ma machine, et cela restera probablement le cas. Pourtant, j’ai l’intention de le rendre open source. Non pas parce qu’il est universellement utile dans sa forme actuelle (il est profondément adapté à ma vie), mais parce que les idées sous-jacentes pourraient l’être.
Pour rendre cela possible, je devrai abstraire les outils, modulariser les fonctionnalités et permettre l’activation et la désactivation des fonctionnalités afin que d’autres puissent façonner l’assistant autour de leurs propres flux de travail, plutôt que du mien.
J’aurais pu construire quelque chose de similaire en utilisant Claude Code seul. Je ne l’ai pas fait. Je voulais un contrôle total : la liberté d’échanger des modèles, de mélanger des fournisseurs et, éventuellement, d’exécuter Fernão sur un LLM local au lieu de m’appuyer sur des API externes. Ici, la propriété et la flexibilité comptent plus pour moi que la commodité.
Si vous deviez créer un assistant personnel d’IA, quelles tâches lui confieriez-vous ? J’aimerais vraiment entendre vos idées et essayer de les construire au sein de Fernão. Laissez un commentaire car ce projet est encore en évolution et les perspectives extérieures sont souvent le moyen le plus rapide de l’améliorer.
You may also like


