
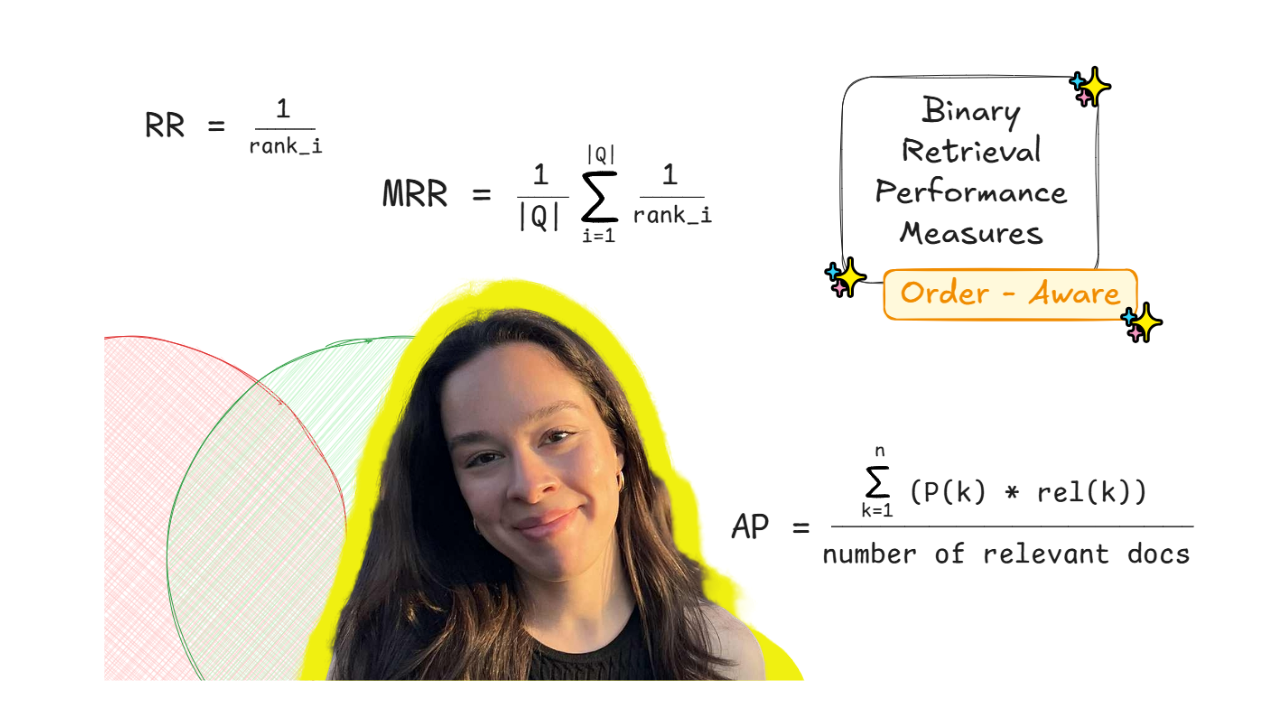
Comment évaluer la qualité de la récupération dans les pipelines RAG (partie 2) : rang réciproque moyen (MRR) et précision moyenne (AP)
Si tu as raté Partie 1 : Comment évaluer la qualité de la récupération dans les pipelines RAGVérifiez-le ici
Dans mon article précédent, j’ai examiné comment évaluer la qualité de récupération d’un pipeline RAG, ainsi que quelques mesures de base pour ce faire. Plus précisément, cette première partie s’est principalement concentrée sur des mesures binaires, ignorant l’ordre, évaluant essentiellement si des résultats pertinents existent ou non dans l’ensemble récupéré. Dans cette deuxième partie, nous allons explorer plus en détail les mesures binaires sensibles à l’ordre. C’est-à-dire des mesures qui prennent en compte le classement avec lequel chaque résultat pertinent est récupéré, en plus d’évaluer s’il est récupéré ou non. Ainsi, dans cet article, nous allons examiner de plus près deux métriques binaires tenant compte des commandes couramment utilisées : Rang réciproque moyen (MRR) et Précision moyenne (AP).
Pourquoi le classement est important dans l’évaluation de la récupération
Une récupération efficace est très importante dans un pipeline RAG, étant donné qu’un bon mécanisme de récupération est la toute première étape pour générer des réponses valides, fondées sur nos documents. Sinon, si les documents corrects contenant les informations nécessaires ne peuvent pas être identifiés en premier lieu, aucune magie de l’IA ne peut résoudre ce problème et fournir des réponses valables.
Nous pouvons distinguer deux grandes catégories de mesures d’évaluation de la qualité de la récupération : les mesures binaires et graduées. Plus précisément, les mesures binaires classent un morceau récupéré comme pertinent ou non, sans situations intermédiaires. D’un autre côté, lorsque nous utilisons des mesures graduées, nous considérons que la pertinence d’un fragment par rapport à la requête de l’utilisateur est plutôt un spectre, et de cette manière, un fragment récupéré peut être plus ou moins pertinent.
Les mesures binaires peuvent être divisées en mesures ignorant les ordres et en mesures sensibles aux ordres. Les mesures ignorant l’ordre évaluent si un fragment existe ou non dans l’ensemble récupéré, quel que soit le classement avec lequel il a été récupéré. Dans mon dernier article, nous avons examiné en détail les mesures binaires les plus courantes, ignorant les ordres, et avons exécuté un exemple de code approfondi en Python. A savoir, nous sommes allés HitRate@K, Précision@K, Rappel@K et F1@K. En revanche, les mesures binaires sensibles à l’ordre, en plus de considérer si des fragments existent ou non dans l’ensemble récupéré, prennent également en compte le classement avec lequel ils sont récupérés.
Ainsi, dans l’article d’aujourd’hui, nous allons examiner plus en détail les métriques de récupération binaires sensibles aux ordres les plus couramment utilisées, telles que MRR et PAet découvrez également comment ceux-ci peuvent être calculés en Python.
J’écris 🍨Crème de donnéesoù j’apprends et expérimente l’IA et les données. Abonnez-vous ici pour apprendre et explorer avec moi.
Quelques mesures binaires sensibles à l’ordre
Ainsi, des mesures binaires, ignorant l’ordre, comme Precision@K ou Recall@K, nous indiquent si les documents corrects se trouvent ou non quelque part dans les k morceaux supérieurs, mais n’indiquent pas si un document se situe en haut ou tout en bas de ces k morceaux. Et c’est précisément cette information que nous fournissent les mesures tenant compte de l’ordre. Certaines mesures très utiles et couramment utilisées ne tenant pas compte des commandes sont Rang réciproque moyen (MRR) et Précision moyenne (AP). Mais voyons tout cela plus en détail.
🎯 Rang réciproque moyen (MRR)
Une mesure sensible à l’ordre couramment utilisée pour évaluer la récupération est Rang réciproque moyen (MRR). En prenant du recul, le Rang Réciproque (RR) exprime dans quel classement se trouve le premier résultat vraiment pertinentparmi les k premiers résultats récupérés. Plus précisément, il mesure à quelle hauteur le premier résultat pertinent apparaît dans le classement. RR peut être calculé comme suit, avec rang_i étant le rang, le premier résultat pertinent est trouvé :

Nous pouvons également explorer visuellement ce calcul avec l’exemple suivant :

Nous pouvons maintenant rassembler les Rang réciproque moyen (MRR). MRR exprime le moyenne position du premier élément pertinent dans différents ensembles de résultats.

De cette manière, le MRR peut varier de 0 à 1. Autrement dit, plus le MRR est élevé, plus le premier document pertinent apparaît haut dans le classement.
Un exemple concret où une métrique telle que MRR peut être utile pour évaluer l’étape de récupération d’un pipeline RAG serait n’importe quel environnement au rythme rapide, où une prise de décision rapide est nécessaire, et nous devons nous assurer qu’un résultat vraiment pertinent émerge en haut de la recherche. Cela fonctionne bien pour évaluer des systèmes où un seul résultat pertinent suffit et où les informations significatives ne sont pas dispersées dans plusieurs morceaux de texte.
La recherche Google est une bonne métaphore pour mieux comprendre le MRR en tant que mesure d’évaluation de récupération. Nous considérons Google comme un bon moteur de recherche car vous pouvez trouver ce que vous cherchez dans les premiers résultats. Si vous deviez faire défiler jusqu’au résultat 150 pour trouver ce que vous recherchez, vous ne le considéreriez pas comme un bon moteur de recherche. De même, un bon mécanisme de recherche vectorielle dans un pipeline RAG devrait faire apparaître les morceaux pertinents dans des classements raisonnablement élevés et ainsi obtenir un MRR raisonnablement élevé.
🎯 Précision moyenne (AP)
Dans mon article précédent sur les mesures de récupération binaires ne tenant pas compte des commandes, nous avons examiné spécifiquement Precision@k. En particulier, Precision@k indique combien des k documents les plus récupérés sont effectivement pertinents. Precision@k peut être calculé comme suit :

Précision moyenne (AP) s’appuie davantage sur cette idée. Plus précisément, pour calculer AP, nous devons initialement calculer de manière itérative Precision@k pour chaque k lorsqu’un nouvel élément pertinent apparaît. Ensuite, nous pouvons calculer AP en calculant simplement la moyenne de ces scores Precision@k.
Mais voyons un exemple illustratif de ce calcul. Pour cet ensemble d’exemples, nous remarquons que de nouveaux fragments pertinents sont introduits dans l’ensemble récupéré pour k = 1 et k = 4.

Ainsi, nous calculons Precision@1 et Precision@4, puis prenons leur moyenne. Ce sera (1/1 + 2/4)/ 2 = (1 + 0,5)/ 2 = 0,75.
On peut alors généraliser le calcul de AP comme suit :

Encore une fois, AP peut varier de 0 à 1. Plus précisément, plus le score AP est élevé, plus notre système de récupération classe les documents pertinents vers le haut de manière cohérente. En d’autres termes, plus les documents pertinents sont récupérés et plus ils apparaissent avant les non pertinents.
Contrairement au MRR, qui se concentre uniquement sur le premier résultat pertinent, AP prend en compte le classement de tous les fragments pertinents récupérés. Il quantifie essentiellement la quantité ou le peu de déchets que nous obtenons, tout en récupérant les éléments vraiment pertinents, pour divers top k.
Pour mieux appréhender AP et MRR, on peut aussi les imaginer dans le cadre d’une playlist Spotify. De la même manière que dans l’exemple de la recherche Google, un MRR élevé signifierait que la première chanson de la playlist est notre chanson préférée. D’un autre côté, un AP élevé signifierait que toute la playlist est bon, et bon nombre de nos chansons préférées apparaissent fréquemment et vers le haut de la liste de lecture.
Alors, notre recherche vectorielle est-elle utile ?
Normalement, je continuerais cette section avec le Guerre et Paix exemple, comme je l’ai fait dans mes autres tutoriels RAG. Cependant, le code de récupération complet devient assez volumineux pour être inclus dans chaque message. Au lieu de cela, dans cet article, je me concentrerai sur la manière de calculer ces métriques en Python, en faisant de mon mieux pour que les exemples restent concis.
De toute façon! Voyons comment MRR et PA peut être calculé en pratique pour un pipeline RAG en Python. On peut définir des fonctions pour calculer le FR et MRR comme suit:
from typing import List, Iterable, Sequence
# Reciprocal Rank (RR)
def reciprocal_rank(relevance: Sequence[int]) -> float:
for i, rel in enumerate(relevance, start=1):
if rel:
return 1.0 / i
return 0.0
# Mean Reciprocal Rank (MRR)
def mean_reciprocal_rank(all_relevance: Iterable[Sequence[int]]) -> float:
vals = [reciprocal_rank(r) for r in all_relevance]
return sum(vals) / len(vals) if vals else 0.0Nous avons déjà calculé Précision@k dans le post précédent comme suit :
# Precision@k
def precision_at_k(relevance: Sequence[int], k: int) -> float:
k = min(k, len(relevance))
if k == 0:
return 0.0
return sum(relevance[:k]) / kSur cette base, nous pouvons définir Précision moyenne (AP) comme suit:
def average_precision(relevance: Sequence[int]) -> float:
if not relevance:
return 0.0
precisions = []
hit_count = 0
for i, rel in enumerate(relevance, start=1):
if rel:
hit_count += 1
precisions.append(hit_count / i) # Precision@i
return sum(precisions) / hit_count if hit_count else 0.0Chacune de ces fonctions prend en entrée une liste d’étiquettes de pertinence binaires, où 1 signifie qu’un morceau récupéré est pertinent pour la requête et 0 signifie qu’il ne l’est pas. En pratique, ces étiquettes sont générées en comparant les résultats récupérés avec l’ensemble de vérités terrain, exactement comme nous l’avons fait dans la première partie lors du calcul de Precision@K et Recall@K. De cette façon, pour chaque requête (par exemple, «Qui est Anna Pavlovna ?« , nous générons une liste de pertinence binaire selon que chaque morceau récupéré contient ou non le texte de réponse. À partir de là, nous pouvons calculer toutes les métriques en utilisant les fonctions comme indiqué ci-dessus.
Une autre mesure utile tenant compte des commandes que nous pouvons calculer est Précision moyenne moyenne (MAP). Comme vous pouvez l’imaginer, MAP est la moyenne des AP pour différents ensembles récupérés. Par exemple, si nous calculons AP pour trois questions de test différentes dans notre pipeline RAG, le score MAP nous indique la qualité globale du classement pour chacune d’entre elles.
Dans mon esprit
Mesures ignorant l’ordre binaire que nous avons vues dans la première partie de cette série, telles que HitRate@k, Precsion@k, Recall@k et F1@k, peut nous fournir des informations précieuses pour évaluer les performances de récupération d’un pipeline RAG. Néanmoins, de telles mesures nous fournissent uniquement des informations indiquant si un document pertinent est présent ou non dans l’ensemble récupéré.
Mesures tenant compte des ordres binaires examinées dans cet article, comme Rang réciproque moyen (MRR) et précision moyenne (AP) peuvent nous fournir des informations supplémentaires, car ils nous indiquent non seulement si les documents pertinents existent dans les résultats récupérés, mais également dans quelle mesure ils sont classés. De cette façon, nous pouvons avoir un meilleur aperçu des performances du mécanisme de récupération de notre pipeline RAG, en fonction de la tâche et du type de documents que nous utilisons.
Restez à l’écoute pour la prochaine et dernière partie de cette série d’évaluations de récupération, où je discuterai mesures d’évaluation de la récupération graduée pour les canalisations RAG.
Vous avez adoré cet article ? Soyons amis ! Rejoignez-moi sur :
📰Sous-pile 💌 Moyen 💼LinkedIn ☕Achetez-moi un café!
Qu’en est-il des pialgorithmes ?
Vous cherchez à apporter la puissance de RAG dans votre organisation ?
pialgorithmes je peux le faire pour toi 👉 réserver une démo aujourd’hui
You may also like


