
Assistant SQL multi-agent, partie 2 : Création d’un gestionnaire RAG
dans mon article de blog, j’avais exploré comment créer un assistant SQL multi-agent à l’aide de CrewAI et Streamlit. L’utilisateur peut interroger une base de données SQLite en langage naturel. Les agents IA généreraient une requête SQL basée sur les entrées de l’utilisateur, l’examineraient et vérifieraient sa conformité avant de l’exécuter sur la base de données pour obtenir des résultats. J’ai également mis en place un point de contrôle humain pour garder le contrôle et affiché les coûts LLM associés à chaque requête pour plus de transparence et de contrôle des coûts. Même si le prototype était génial et générait de bons résultats pour ma petite base de données de démonstration, je savais que cela ne suffirait pas pour les bases de données réelles. Dans la configuration précédente, j’envoyais l’intégralité du schéma de base de données en tant que contexte avec l’entrée utilisateur. À mesure que les schémas de base de données grandissent, la transmission du schéma complet au LLM augmente l’utilisation des jetons, ralentit les temps de réponse et rend les hallucinations plus probables. J’avais besoin d’un moyen de fournir uniquement des extraits de schéma pertinents au LLM. C’est ici RAG (Récupération Augmentée Génération) entre.
Dans cet article de blog, je crée un gestionnaire RAG et j’ajoute multiple Stratégies RAG à mon assistant SQL pour comparer leurs performances sur des mesures telles que le temps de réponse et l’utilisation des jetons. L’assistant prend désormais en charge quatre stratégies RAG :
- Pas de RAG : Réussit le schéma complet (référence pour comparaison)
- Mot-clé RAG : Utilise la correspondance de mots clés spécifiques au domaine pour sélectionner les tables pertinentes
- CHIFFON FAISS : Tire parti de la similarité des vecteurs sémantiques via FAISS avec
all-MiniLM-L6-v2intégrations - Chroma RAG : Une solution de stockage de vecteurs persistants avec ChromaDB pour une recherche évolutive de niveau production
Pour ce projet, je me suis concentré uniquement sur les techniques RAG qui sont pratiques, légères et rentables (gratuites). Vous pouvez ajouter n’importe quel nombre d’implémentations et choisir celle qui convient le mieux à votre cas. Pour faciliter l’expérimentation et l’analyse, j’ai créé un outil interactif de comparaison des performances qui évalue la réduction des jetons, le nombre de tables, le temps de réponse et la précision des requêtes pour les quatre stratégies.

Construire un gestionnaire RAG
Le rag_manager.py Le fichier contient l’intégralité de l’implémentation du gestionnaire RAG. Tout d’abord, j’ai créé un BaseRAG class – un modèle que j’utilise pour toutes mes différentes stratégies RAG. Il garantit que chaque approche RAG suit la même structure. Toute nouvelle stratégie comportera deux éléments : une méthode pour récupérer le schéma pertinent basé sur la requête de l’utilisateur et une autre méthode qui explique en quoi consiste l’approche. En utilisant le classe de base abstraite (ABC), je garde le code propre, modulaire et facile à étendre plus tard.
from typing import Dict, List, Any, Optional
from abc import ABC, abstractmethod
class BaseRAG(ABC):
"""Base class for all RAG implementations."""
def __init__(self, db_path: str = DB_PATH):
self.db_path = db_path
self.name = self.__class__.__name__
@abstractmethod
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
"""Get relevant schema for the user query."""
pass
@abstractmethod
def get_approach_info(self) -> Dict[str, Any]:
"""Get information about this RAG approach."""
pass
Pas de stratégie RAG
Il s’agit fondamentalement de la même approche que celle que j’ai utilisée précédemment, où j’ai envoyé l’intégralité du schéma de base de données comme contexte au LLM sans aucun filtrage ni optimisation. Cette approche est idéale pour les très petits schémas (de préférence moins de 10 tables).
class NoRAG(BaseRAG):
"""No RAG - returns full schema."""
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
return get_structured_schema(self.db_path)
def get_approach_info(self) -> Dict[str, Any]:
return {
"name": "No RAG (Full Schema)",
"description": "Uses complete database schema",
"pros": ["Simple", "Always complete", "No setup required"],
"cons": ["High token usage", "Slower for large schemas"],
"best_for": "Small schemas (< 10 tables)"
}
Stratégie RAG par mots-clés
Dans l’approche mot-clé RAG, j’utilise un ensemble de mots-clés prédéfinis mappés à chaque table du schéma. Lorsqu’un utilisateur demande quelque chose, le système vérifie les correspondances de mots clés dans la requête et sélectionne uniquement les tables les plus pertinentes. De cette façon, je n’envoie pas l’intégralité du schéma au LLM, ce qui économise les jetons et accélère les choses. Cela fonctionne bien lorsque votre schéma vous est familier et que vos requêtes sont liées à l’entreprise ou suivent des modèles courants.
Le _build_table_keywords(self) La méthode est au cœur du fonctionnement de la logique de correspondance des mots clés. Il contient un mappage de mots-clés codé en dur pour chaque table du schéma. Il permet d’associer les termes de requête des utilisateurs (comme « ventes », « marque », « client ») aux tableaux les plus probablement pertinents.
class KeywordRAG(BaseRAG):
"""Keyword-based RAG using business context matching."""
def __init__(self, db_path: str = DB_PATH):
super().__init__(db_path)
self.table_keywords = self._build_table_keywords()
def _build_table_keywords(self) -> Dict[str, List[str]]:
"""Build keyword mappings for each table."""
return {
'products': ['product', 'item', 'catalog', 'price', 'category', 'brand', 'sales', 'sold'],
'product_variants': ['variant', 'product', 'sku', 'color', 'size', 'brand', 'sales', 'sold'],
'customers': ['customer', 'user', 'client', 'buyer', 'person', 'email', 'name'],
'orders': ['order', 'purchase', 'transaction', 'sale', 'buy', 'total', 'amount', 'sales'],
'order_items': ['item', 'product', 'quantity', 'line', 'detail', 'sales', 'sold', 'brand'],
'payments': ['payment', 'pay', 'money', 'revenue', 'amount'],
'inventory': ['inventory', 'stock', 'quantity', 'warehouse', 'available'],
'reviews': ['review', 'rating', 'feedback', 'comment', 'opinion'],
'suppliers': ['supplier', 'vendor', 'procurement', 'purchase'],
'categories': ['category', 'type', 'classification', 'group'],
'brands': ['brand', 'manufacturer', 'company', 'sales', 'sold', 'quantity', 'total'],
'addresses': ['address', 'location', 'shipping', 'billing'],
'shipments': ['shipment', 'delivery', 'shipping', 'tracking'],
'discounts': ['discount', 'coupon', 'promotion', 'offer'],
'warehouses': ['warehouse', 'facility', 'location', 'storage'],
'employees': ['employee', 'staff', 'worker', 'person'],
'departments': ['department', 'division', 'team'],
'product_images': ['image', 'photo', 'picture', 'media'],
'purchase_orders': ['purchase', 'procurement', 'supplier', 'order'],
'purchase_order_items': ['purchase', 'procurement', 'supplier', 'item'],
'order_discounts': ['discount', 'coupon', 'promotion', 'order'],
'shipment_items': ['shipment', 'delivery', 'item', 'tracking']
}
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
import re
# Score tables by keyword relevance
query_words = set(re.findall(r'\b\w+\b', user_query.lower()))
table_scores = {}
for table_name, keywords in self.table_keywords.items():
score = 0
# Count keyword matches
for keyword in keywords:
if keyword in query_words:
score += 3
# Partial matches
for query_word in query_words:
if keyword in query_word or query_word in keyword:
score += 1
# Bonus for exact table name match
if table_name.lower() in query_words:
score += 10
table_scores[table_name] = score
# Get top scoring tables
sorted_tables = sorted(table_scores.items(), key=lambda x: x[1], reverse=True)
relevant_tables = [table for table, score in sorted_tables[:max_tables] if score > 0]
# Fallback to default tables if no matches
if not relevant_tables:
relevant_tables = self._get_default_tables(user_query)[:max_tables]
# Build schema for selected tables
return self._build_schema(relevant_tables)
def _get_default_tables(self, user_query: str) -> List[str]:
"""Get default tables based on query patterns."""
query_lower = user_query.lower()
# Sales/revenue queries
if any(word in query_lower for word in ['revenue', 'sales', 'total', 'amount', 'brand']):
return ['orders', 'order_items', 'product_variants', 'products', 'brands']
# Product queries
if any(word in query_lower for word in ['product', 'item', 'catalog']):
return ['products', 'product_variants', 'categories', 'brands']
# Customer queries
if any(word in query_lower for word in ['customer', 'user', 'buyer']):
return ['customers', 'orders', 'addresses']
# Default
return ['products', 'customers', 'orders', 'order_items']
def _build_schema(self, table_names: List[str]) -> str:
"""Build schema string for specified tables."""
if not table_names:
return get_structured_schema(self.db_path)
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
schema_lines = ["Available tables and columns:"]
try:
for table_name in table_names:
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
if columns:
col_names = [col[1] for col in columns]
schema_lines.append(f"- {table_name}: {', '.join(col_names)}")
finally:
conn.close()
return '\n'.join(schema_lines)
def get_approach_info(self) -> Dict[str, Any]:
return {
"name": "Keyword RAG",
"description": "Uses business context keywords to match relevant tables",
"pros": ["Fast", "No external dependencies", "Good for business queries"],
"cons": ["Limited by predefined keywords", "May miss complex relationships"],
"best_for": "Business queries with clear domain terms"
}
Approche FAISS RAG
Le FAISS CHIFFON c’est dans la stratégie que les choses commencent à devenir plus intelligentes. Au lieu de vider l’intégralité du schéma, j’intègre les métadonnées de chaque table (colonnes, relations, contexte métier) dans des vecteurs à l’aide d’un transformateur de phrases. Lorsque l’utilisateur pose une question, celle-ci est également intégrée à cette requête et utilise FAISS pour effectuer une recherche sémantique correspondant au « sens » au lieu de simplement des mots-clés. C’est parfait pour les requêtes pour lesquelles les utilisateurs ne sont pas très précis ou lorsque les tables ont des termes associés. J’aime FAISS car il est gratuit, fonctionne localement et donne des résultats assez précis tout en économisant des jetons.
Le seul problème est que sa configuration nécessite des étapes supplémentaires et utilise plus de mémoire que les approches de base. Les LLM et les modèles d’intégration ne savent pas ce que signifient vos tableaux à moins que vous ne le leur expliquiez. Dans le _get_business_context() méthode, nous devons rédiger manuellement une brève description de ce que chaque table représente dans l’entreprise.
Dans le _extract_table_info() méthode, j’extrait les noms de tables, les noms de colonnes et les relations de clés étrangères à partir des requêtes PRAGMA de SQLite pour créer un dictionnaire avec des informations structurées sur chaque table. Enfin, dans le _create_table_description() méthode, des descriptions complètes pour chaque table sont construites pour être intégrées par un SentenceTransformer.
class FAISSVectorRAG(BaseRAG):
"""FAISS-based vector RAG using sentence transformers."""
def __init__(self, db_path: str = DB_PATH):
super().__init__(db_path)
self.model = None
self.index = None
self.table_info = {}
self.table_names = []
self._initialize()
def _initialize(self):
"""Initialize the FAISS vector store and embeddings."""
try:
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
print("🔄 Initializing FAISS Vector RAG...")
# Load embedding model
self.model = SentenceTransformer('all-MiniLM-L6-v2')
print("✅ Loaded embedding model: all-MiniLM-L6-v2")
# Extract table information and create embeddings
self.table_info = self._extract_table_info()
# Create embeddings for each table
table_descriptions = []
self.table_names = []
for table_name, info in self.table_info.items():
description = self._create_table_description(table_name, info)
table_descriptions.append(description)
self.table_names.append(table_name)
# Generate embeddings
print(f"🔄 Generating embeddings for {len(table_descriptions)} tables...")
embeddings = self.model.encode(table_descriptions)
# Create FAISS index
dimension = embeddings.shape[1]
self.index = faiss.IndexFlatIP(dimension) # Inner product for cosine similarity
# Normalize embeddings for cosine similarity
faiss.normalize_L2(embeddings)
self.index.add(embeddings.astype('float32'))
print(f"✅ FAISS Vector RAG initialized with {len(table_descriptions)} tables")
except Exception as e:
print(f"❌ Error initializing FAISS Vector RAG: {e}")
self.model = None
self.index = None
def _extract_table_info(self) -> Dict[str, Dict]:
"""Extract detailed information about each table."""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
table_info = {}
try:
# Get all table names
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
for (table_name,) in tables:
info = {
'columns': [],
'foreign_keys': [],
'business_context': self._get_business_context(table_name)
}
# Get column information
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
for col in columns:
info['columns'].append({
'name': col[1],
'type': col[2],
'primary_key': bool(col[5])
})
# Get foreign key information
cursor.execute(f"PRAGMA foreign_key_list({table_name});")
fks = cursor.fetchall()
for fk in fks:
info['foreign_keys'].append({
'column': fk[3],
'references_table': fk[2],
'references_column': fk[4]
})
table_info[table_name] = info
finally:
conn.close()
return table_info
def _get_business_context(self, table_name: str) -> str:
"""Get business context description for tables."""
contexts = {
'products': 'Product catalog with items, prices, categories, and brand information. Core inventory data.',
'product_variants': 'Product variations like colors, sizes, SKUs. Links products to specific sellable items.',
'customers': 'Customer profiles with personal information, contact details, and account status.',
'orders': 'Purchase transactions with totals, dates, status, and customer relationships.',
'order_items': 'Individual line items within orders. Contains quantities, prices, and product references.',
'payments': 'Payment processing records with methods, amounts, and transaction status.',
'inventory': 'Stock levels and warehouse quantities for product variants.',
'reviews': 'Customer feedback, ratings, and product reviews.',
'suppliers': 'Vendor information for procurement and supply chain management.',
'categories': 'Product categorization hierarchy for organizing catalog.',
'brands': 'Brand information for products and marketing purposes.',
'addresses': 'Customer shipping and billing address information.',
'shipments': 'Delivery tracking and shipping status information.',
'discounts': 'Promotional codes, coupons, and discount campaigns.',
'warehouses': 'Storage facility locations and warehouse management.',
'employees': 'Staff information and organizational structure.',
'departments': 'Organizational divisions and team structure.',
'product_images': 'Product photography and media assets.',
'purchase_orders': 'Procurement orders from suppliers.',
'purchase_order_items': 'Line items for supplier purchase orders.',
'order_discounts': 'Applied discounts and promotions on orders.',
'shipment_items': 'Individual items within shipment packages.'
}
return contexts.get(table_name, f'Database table for {table_name} related operations.')
def _create_table_description(self, table_name: str, info: Dict) -> str:
"""Create a comprehensive description for embedding."""
description = f"Table: {table_name}\n"
description += f"Purpose: {info['business_context']}\n"
# Add column information
description += "Columns: "
col_names = [col['name'] for col in info['columns']]
description += ", ".join(col_names) + "\n"
# Add relationship information
if info['foreign_keys']:
description += "Relationships: "
relationships = []
for fk in info['foreign_keys']:
relationships.append(f"links to {fk['references_table']} via {fk['column']}")
description += "; ".join(relationships) + "\n"
# Add common use cases based on table type
use_cases = self._get_use_cases(table_name)
if use_cases:
description += f"Common queries: {use_cases}"
return description
def _get_use_cases(self, table_name: str) -> str:
"""Get common use cases for each table."""
use_cases = {
'products': 'product searches, catalog listings, price queries, inventory checks',
'customers': 'customer lookup, registration analysis, geographic distribution',
'orders': 'sales analysis, revenue tracking, order history, status monitoring',
'order_items': 'product sales performance, revenue by product, order composition',
'payments': 'payment processing, revenue reconciliation, payment method analysis',
'brands': 'brand performance, sales by brand, brand comparison',
'categories': 'category analysis, product organization, catalog structure'
}
return use_cases.get(table_name, 'general data queries and analysis')
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
"""Get relevant schema using vector similarity search."""
if self.model is None or self.index is None:
print("⚠️ FAISS not initialized, falling back to full schema")
return get_structured_schema(self.db_path)
try:
import faiss
import numpy as np
# Generate query embedding
query_embedding = self.model.encode([user_query])
faiss.normalize_L2(query_embedding)
# Search for similar tables
scores, indices = self.index.search(query_embedding.astype('float32'), max_tables)
# Get relevant table names
relevant_tables = []
for i, (score, idx) in enumerate(zip(scores[0], indices[0])):
if idx < len(self.table_names) and score > 0.1: # Minimum similarity threshold
relevant_tables.append(self.table_names[idx])
# Fallback if no relevant tables found
if not relevant_tables:
print("⚠️ No relevant tables found, using defaults")
relevant_tables = self._get_default_tables(user_query)[:max_tables]
# Build schema for selected tables
return self._build_schema(relevant_tables)
except Exception as e:
print(f"⚠️ Vector search failed: {e}, falling back to full schema")
return get_structured_schema(self.db_path)
def _get_default_tables(self, user_query: str) -> List[str]:
"""Get default tables based on query patterns."""
query_lower = user_query.lower()
if any(word in query_lower for word in ['revenue', 'sales', 'total', 'amount', 'brand']):
return ['orders', 'order_items', 'product_variants', 'products', 'brands']
elif any(word in query_lower for word in ['product', 'item', 'catalog']):
return ['products', 'product_variants', 'categories', 'brands']
elif any(word in query_lower for word in ['customer', 'user', 'buyer']):
return ['customers', 'orders', 'addresses']
else:
return ['products', 'customers', 'orders', 'order_items']
def _build_schema(self, table_names: List[str]) -> str:
"""Build schema string for specified tables."""
if not table_names:
return get_structured_schema(self.db_path)
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
schema_lines = ["Available tables and columns:"]
try:
for table_name in table_names:
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
if columns:
col_names = [col[1] for col in columns]
schema_lines.append(f"- {table_name}: {', '.join(col_names)}")
finally:
conn.close()
return '\n'.join(schema_lines)
def get_approach_info(self) -> Dict[str, Any]:
return {
"name": "FAISS Vector RAG",
"description": "Uses semantic embeddings and vector similarity search",
"pros": ["Semantic understanding", "Handles complex queries", "No API costs"],
"cons": ["Requires model download", "Higher memory usage", "Setup complexity"],
"best_for": "Complex queries, large schemas, semantic relationships"
}
Stratégie Chroma RAG
Chroma RAG est une version de FAISS plus conviviale pour la production car elle offre un stockage persistant. Au lieu de conserver les intégrations en mémoire, Chroma les stocke localement, donc même si je redémarre l’application, l’index vectoriel est toujours là. Tout comme dans FAISS, je dois toujours décrire manuellement ce que fait chaque table en termes métier (en _get_business_context()). J’intègre mes descriptions de schéma et les stocke dans ChromaDB. Lors de l’initialisation, le transformateur de phrases (MiniLM) est chargé. Si le vecteur existe déjà, il est chargé. Sinon, j’extrait les infos + descriptions et j’appelle _populate_collection() pour générer et stocker des vecteurs. Ce processus ne doit être effectué qu’une seule fois ou lorsque le schéma change.
C’est rapide, cohérent d’une session à l’autre et facile à configurer. Je l’ai choisi parce qu’il est gratuit, ne nécessite pas de services externes et fonctionne bien pour les cas d’utilisation réels où vous souhaitez évoluer sans vous soucier de perdre l’index vectoriel ou de tout retraiter à chaque fois.
class ChromaVectorRAG(BaseRAG):
"""Chroma-based vector RAG using sentence transformers with persistent storage."""
def __init__(self, db_path: str = DB_PATH):
super().__init__(db_path)
self.model = None
self.chroma_client = None
self.collection = None
self.table_info = {}
self.table_names = []
self._initialize()
def _initialize(self):
"""Initialize the Chroma vector store and embeddings."""
try:
import chromadb
from sentence_transformers import SentenceTransformer
print("🔄 Initializing Chroma Vector RAG...")
# Load embedding model
self.model = SentenceTransformer('all-MiniLM-L6-v2')
print("✅ Loaded embedding model: all-MiniLM-L6-v2")
# Initialize Chroma client (persistent storage)
self.chroma_client = chromadb.PersistentClient(path="./data/chroma_db")
# Get or create collection
collection_name = "schema_tables"
try:
self.collection = self.chroma_client.get_collection(collection_name)
print("✅ Loaded existing Chroma collection")
except:
# Create new collection if it doesn't exist
self.collection = self.chroma_client.create_collection(
name=collection_name,
metadata={"description": "Database schema table embeddings"}
)
print("✅ Created new Chroma collection")
# Extract table information and create embeddings
self.table_info = self._extract_table_info()
self._populate_collection()
# Load table names for reference
self._load_table_names()
print(f"✅ Chroma Vector RAG initialized with {len(self.table_names)} tables")
except Exception as e:
print(f"❌ Error initializing Chroma Vector RAG: {e}")
self.model = None
self.chroma_client = None
self.collection = None
def _extract_table_info(self) -> Dict[str, Dict]:
"""Extract detailed information about each table."""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
table_info = {}
try:
# Get all table names
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
for (table_name,) in tables:
info = {
'columns': [],
'foreign_keys': [],
'business_context': self._get_business_context(table_name)
}
# Get column information
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
for col in columns:
info['columns'].append({
'name': col[1],
'type': col[2],
'primary_key': bool(col[5])
})
# Get foreign key information
cursor.execute(f"PRAGMA foreign_key_list({table_name});")
fks = cursor.fetchall()
for fk in fks:
info['foreign_keys'].append({
'column': fk[3],
'references_table': fk[2],
'references_column': fk[4]
})
table_info[table_name] = info
finally:
conn.close()
return table_info
def _get_business_context(self, table_name: str) -> str:
"""Get business context description for tables."""
contexts = {
'products': 'Product catalog with items, prices, categories, and brand information. Core inventory data.',
'product_variants': 'Product variations like colors, sizes, SKUs. Links products to specific sellable items.',
'customers': 'Customer profiles with personal information, contact details, and account status.',
'orders': 'Purchase transactions with totals, dates, status, and customer relationships.',
'order_items': 'Individual line items within orders. Contains quantities, prices, and product references.',
'payments': 'Payment processing records with methods, amounts, and transaction status.',
'inventory': 'Stock levels and warehouse quantities for product variants.',
'reviews': 'Customer feedback, ratings, and product reviews.',
'suppliers': 'Vendor information for procurement and supply chain management.',
'categories': 'Product categorization hierarchy for organizing catalog.',
'brands': 'Brand information for products and marketing purposes.',
'addresses': 'Customer shipping and billing address information.',
'shipments': 'Delivery tracking and shipping status information.',
'discounts': 'Promotional codes, coupons, and discount campaigns.',
'warehouses': 'Storage facility locations and warehouse management.',
'employees': 'Staff information and organizational structure.',
'departments': 'Organizational divisions and team structure.',
'product_images': 'Product photography and media assets.',
'purchase_orders': 'Procurement orders from suppliers.',
'purchase_order_items': 'Line items for supplier purchase orders.',
'order_discounts': 'Applied discounts and promotions on orders.',
'shipment_items': 'Individual items within shipment packages.'
}
return contexts.get(table_name, f'Database table for {table_name} related operations.')
def _populate_collection(self):
"""Populate Chroma collection with table embeddings."""
if not self.collection or not self.table_info:
return
documents = []
metadatas = []
ids = []
for table_name, info in self.table_info.items():
# Create comprehensive description
description = self._create_table_description(table_name, info)
documents.append(description)
metadatas.append({
'table_name': table_name,
'column_count': len(info['columns']),
'has_foreign_keys': len(info['foreign_keys']) > 0,
'business_context': info['business_context']
})
ids.append(f"table_{table_name}")
# Add to collection
self.collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)
print(f"✅ Added {len(documents)} table embeddings to Chroma collection")
def _create_table_description(self, table_name: str, info: Dict) -> str:
"""Create a comprehensive description for embedding."""
description = f"Table: {table_name}\n"
description += f"Purpose: {info['business_context']}\n"
# Add column information
description += "Columns: "
col_names = [col['name'] for col in info['columns']]
description += ", ".join(col_names) + "\n"
# Add relationship information
if info['foreign_keys']:
description += "Relationships: "
relationships = []
for fk in info['foreign_keys']:
relationships.append(f"links to {fk['references_table']} via {fk['column']}")
description += "; ".join(relationships) + "\n"
# Add common use cases
use_cases = self._get_use_cases(table_name)
if use_cases:
description += f"Common queries: {use_cases}"
return description
def _get_use_cases(self, table_name: str) -> str:
"""Get common use cases for each table."""
use_cases = {
'products': 'product searches, catalog listings, price queries, inventory checks',
'customers': 'customer lookup, registration analysis, geographic distribution',
'orders': 'sales analysis, revenue tracking, order history, status monitoring',
'order_items': 'product sales performance, revenue by product, order composition',
'payments': 'payment processing, revenue reconciliation, payment method analysis',
'brands': 'brand performance, sales by brand, brand comparison',
'categories': 'category analysis, product organization, catalog structure'
}
return use_cases.get(table_name, 'general data queries and analysis')
def _load_table_names(self):
"""Load table names from the collection."""
if not self.collection:
return
try:
# Get all items from collection
results = self.collection.get()
self.table_names = [metadata['table_name'] for metadata in results['metadatas']]
except Exception as e:
print(f"⚠️ Could not load table names from Chroma: {e}")
self.table_names = []
def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str:
"""Get relevant schema using Chroma vector similarity search."""
if not self.collection:
print("⚠️ Chroma not initialized, falling back to full schema")
return get_structured_schema(self.db_path)
try:
# Search for similar tables
results = self.collection.query(
query_texts=[user_query],
n_results=max_tables
)
# Extract relevant table names
relevant_tables = []
if results['metadatas'] and len(results['metadatas']) > 0:
for metadata in results['metadatas'][0]:
relevant_tables.append(metadata['table_name'])
# Fallback if no relevant tables found
if not relevant_tables:
print("⚠️ No relevant tables found, using defaults")
relevant_tables = self._get_default_tables(user_query)[:max_tables]
# Build schema for selected tables
return self._build_schema(relevant_tables)
except Exception as e:
print(f"⚠️ Chroma search failed: {e}, falling back to full schema")
return get_structured_schema(self.db_path)
def _get_default_tables(self, user_query: str) -> List[str]:
"""Get default tables based on query patterns."""
query_lower = user_query.lower()
if any(word in query_lower for word in ['revenue', 'sales', 'total', 'amount', 'brand']):
return ['orders', 'order_items', 'product_variants', 'products', 'brands']
elif any(word in query_lower for word in ['product', 'item', 'catalog']):
return ['products', 'product_variants', 'categories', 'brands']
elif any(word in query_lower for word in ['customer', 'user', 'buyer']):
return ['customers', 'orders', 'addresses']
else:
return ['products', 'customers', 'orders', 'order_items']
def _build_schema(self, table_names: List[str]) -> str:
"""Build schema string for specified tables."""
if not table_names:
return get_structured_schema(self.db_path)
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
schema_lines = ["Available tables and columns:"]
try:
for table_name in table_names:
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
if columns:
col_names = [col[1] for col in columns]
schema_lines.append(f"- {table_name}: {', '.join(col_names)}")
finally:
conn.close()
return '\n'.join(schema_lines)
def get_approach_info(self) -> Dict[str, Any]:
return {
"name": "Chroma Vector RAG",
"description": "Uses Chroma DB for persistent vector storage with semantic search",
"pros": ["Persistent storage", "Fast queries", "Scalable", "Easy management"],
"cons": ["Requires disk space", "Initial setup time", "Additional dependency"],
"best_for": "Production environments, persistent workflows, team collaboration"
}
Comparaison des différentes stratégies RAG
Ce RAGManager La classe est le centre de contrôle permettant de basculer entre les différentes stratégies RAG. Sur la base de la requête de l’utilisateur, il choisit la bonne approche, récupère la partie la plus pertinente du schéma et suit les performances telles que le temps de réponse, les économies de jetons et le nombre de tables. Il dispose également d’une fonction de comparaison pour comparer tous les RAG côte à côte et stocke les mesures historiques afin que vous puissiez analyser les performances de chacun au fil du temps. Super pratique pour tester ce qui fonctionne le mieux et optimiser les choses.
Toutes les différentes classes de stratégie RAG sont initialisées et stockées dans self.approaches. Chaque approche RAG est une classe qui hérite de BaseRAGdonc tous ont une interface cohérente (get_relevant_schema() et get_approach_info()). Cela signifie que vous pouvez facilement intégrer une nouvelle stratégie (par exemple Pinecone ou Weaviate) tant qu’elle s’étend BaseRAG.
La méthode get_relevant_schema() renvoie le schéma pertinent pour cette requête en fonction de la stratégie choisie. Si une stratégie invalide est adoptée ou s’il y a un échec pour une raison quelconque, elle revient intelligemment au 'Keyword RAG' stratégie.
La méthode compare_approaches() exécute la même requête dans toutes les stratégies RAG. Il mesure :
- Longueur du schéma résultant
- % de réduction des jetons par rapport au schéma complet
- Temps de réponse
- Nombre de tables renvoyées
C’est vraiment utile pour stratégies de référence côte à côte et choisissez celui qui convient le mieux à votre cas d’utilisation.
class RAGManager:
"""Manager for multiple RAG approaches."""
def __init__(self, db_path: str = DB_PATH):
self.db_path = db_path
self.approaches = {
'no_rag': NoRAG(db_path),
'keyword': KeywordRAG(db_path),
'faiss': FAISSVectorRAG(db_path),
'chroma': ChromaVectorRAG(db_path)
}
self.performance_metrics = {}
def get_available_approaches(self) -> Dict[str, Dict[str, Any]]:
"""Get information about all available RAG approaches."""
return {
approach_id: approach.get_approach_info()
for approach_id, approach in self.approaches.items()
}
def get_relevant_schema(self, user_query: str, approach: str = 'keyword', max_tables: int = 5) -> str:
"""Get relevant schema using specified approach."""
if approach not in self.approaches:
print(f"⚠️ Unknown approach '{approach}', falling back to keyword")
approach = 'keyword'
start_time = time.time()
try:
schema = self.approaches[approach].get_relevant_schema(user_query, max_tables)
# Record performance metrics
end_time = time.time()
self._record_performance(approach, user_query, schema, end_time - start_time)
return schema
except Exception as e:
print(f"⚠️ Error with {approach} approach: {e}")
# Fallback to keyword approach
if approach != 'keyword':
return self.get_relevant_schema(user_query, 'keyword', max_tables)
else:
return get_structured_schema(self.db_path)
def compare_approaches(self, user_query: str, max_tables: int = 5) -> Dict[str, Any]:
"""Compare all approaches for a given query."""
results = {}
full_schema = get_structured_schema(self.db_path)
full_schema_length = len(full_schema)
for approach_id, approach in self.approaches.items():
start_time = time.time()
try:
schema = approach.get_relevant_schema(user_query, max_tables)
end_time = time.time()
results[approach_id] = {
'schema': schema,
'schema_length': len(schema),
'token_reduction': ((full_schema_length - len(schema)) / full_schema_length) * 100,
'response_time': end_time - start_time,
'table_count': len([line for line in schema.split('\n') if line.startswith('- ')]),
'success': True
}
except Exception as e:
results[approach_id] = {
'schema': '',
'schema_length': 0,
'token_reduction': 0,
'response_time': 0,
'table_count': 0,
'success': False,
'error': str(e)
}
return results
def _record_performance(self, approach: str, query: str, schema: str, response_time: float):
"""Record performance metrics for analysis."""
if approach not in self.performance_metrics:
self.performance_metrics[approach] = []
full_schema_length = len(get_structured_schema(self.db_path))
schema_length = len(schema)
metrics = {
'query': query,
'schema_length': schema_length,
'token_reduction': ((full_schema_length - schema_length) / full_schema_length) * 100,
'response_time': response_time,
'table_count': len([line for line in schema.split('\n') if line.startswith('- ')]),
'timestamp': time.time()
}
self.performance_metrics[approach].append(metrics)
def get_performance_summary(self) -> Dict[str, Any]:
"""Get performance summary for all approaches."""
summary = {}
for approach, metrics_list in self.performance_metrics.items():
if not metrics_list:
continue
avg_token_reduction = sum(m['token_reduction'] for m in metrics_list) / len(metrics_list)
avg_response_time = sum(m['response_time'] for m in metrics_list) / len(metrics_list)
avg_table_count = sum(m['table_count'] for m in metrics_list) / len(metrics_list)
summary[approach] = {
'queries_processed': len(metrics_list),
'avg_token_reduction': round(avg_token_reduction, 1),
'avg_response_time': round(avg_response_time, 3),
'avg_table_count': round(avg_table_count, 1)
}
return summary
# Convenience functions for backward compatibility
def get_rag_enhanced_schema(user_query: str, db_path: str = DB_PATH, approach: str = 'keyword') -> str:
"""Get RAG-enhanced schema using specified approach."""
manager = RAGManager(db_path)
return manager.get_relevant_schema(user_query, approach)
# Global cached instance
_rag_manager_instance = None
def get_cached_rag_manager(db_path: str = DB_PATH) -> RAGManager:
"""Get cached RAG manager instance."""
global _rag_manager_instance
if _rag_manager_instance is None:
_rag_manager_instance = RAGManager(db_path)
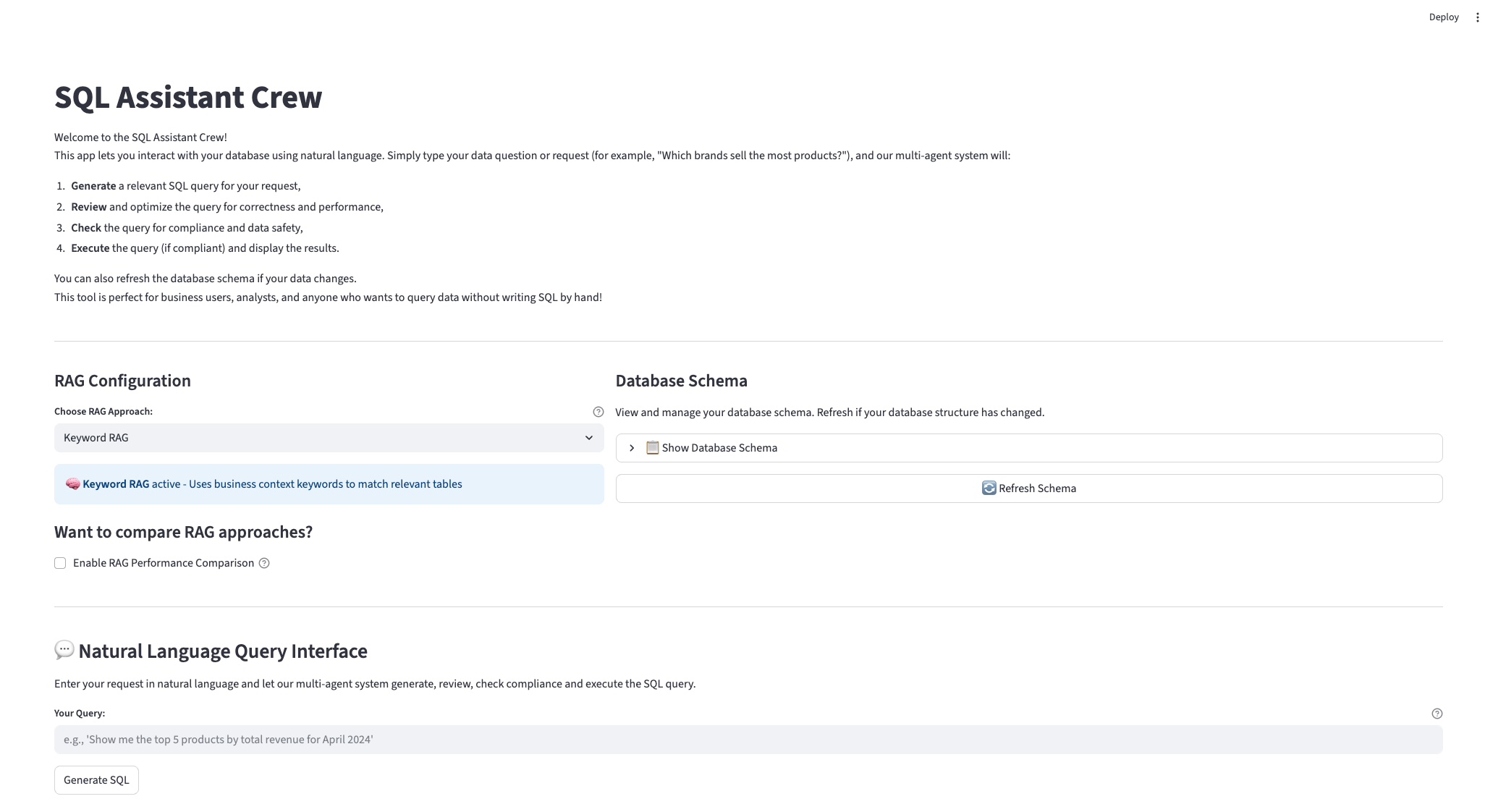
return _rag_manager_instanceL’application Streamlit est entièrement intégrée à ce gestionnaire, afin que les utilisateurs puissent choisir la stratégie de leur choix et voir les résultats en temps réel. Vous pouvez consulter le code complet sur GitHub ici. Voici une démo fonctionnelle de la nouvelle application en action :

Pensées finales
Ce n’est pas la fin ; il y a encore beaucoup à améliorer. Je dois faire des tests de résistance contre diverses attaques et renforcer les garde-fous pour réduire les hallucinations et garantir la sécurité des données. Ce serait bien de construire un système d’accès basé sur les rôles pour la gouvernance des données. Peut-être que le remplacement de Streamlit par un framework frontend comme React pourrait rendre l’application plus évolutive pour les déploiements dans le monde réel. Tout ça, pour la prochaine fois.
Avant de partir…
Suivez-moi pour ne manquer aucun nouveau message que j’écrirai à l’avenir ; vous trouverez plus de mes articles sur ma page de profil. Vous pouvez également me contacter sur LinkedIn ou X!
You may also like


