
Une histoire de deux variantes : pourquoi NumPy et Pandas donnent des réponses différentes
vous analysez un petit ensemble de données :
\[X = [15, 8, 13, 7, 7, 12, 15, 6, 8, 9]\]
Vous souhaitez calculer des statistiques récapitulatives pour avoir une idée de la répartition de ces données, vous utilisez donc numpy pour calculer la moyenne et la variance.
import numpy as np
X = [15, 8, 13, 7, 7, 12, 15, 6, 8, 9]
mean = np.mean(X)
var = np.var(X)
print(f"Mean={mean:.2f}, Variance={var:.2f}")Votre résultat ressemble à ceci :
Mean=10.00, Variance=10.60Super! Vous avez désormais une idée de la répartition de vos données. Cependant, votre collègue arrive et vous dit qu’il a également calculé des statistiques récapitulatives sur ce même ensemble de données en utilisant le code suivant :
import pandas as pd
X = pd.Series([15, 8, 13, 7, 7, 12, 15, 6, 8, 9])
mean = X.mean()
var = X.var()
print(f"Mean={mean:.2f}, Variance={var:.2f}")Leur sortie ressemble à ceci :
Mean=10.00, Variance=11.78Les moyennes sont les mêmes, mais les écarts sont différents ! Qu’est-ce qui donne ?
Cet écart se produit parce que numpy et pandas utilisez différentes équations par défaut pour calculer la variance d’un tableau. Cet article définira mathématiquement les deux variances, expliquera pourquoi elles diffèrent et montrera comment utiliser l’une ou l’autre équation dans différentes bibliothèques numériques.
Deux définitions
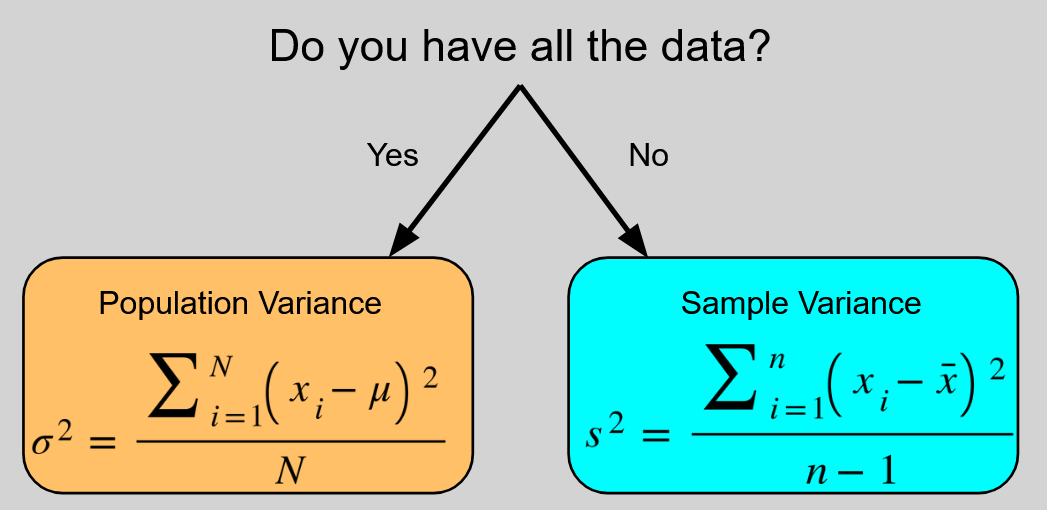
Il existe deux manières standard de calculer la variance, chacune étant destinée à un objectif différent. Il s’agit de savoir si vous calculez la variance de l’ensemble population (le groupe complet que vous étudiez) ou juste un échantillon (un sous-ensemble plus petit de cette population pour laquelle vous disposez réellement de données).
Le variance de la population, est défini comme :
\[\sigma^2 = \frac{\sum_{i=1}^N(x_i-\mu)^2}{N}\]
Alors que le variance de l’échantillon, est défini comme :
\[s^2 = \frac{\sum_{i=1}^n(x_i-\bar x)^2}{n-1}\]
(Note: représente chaque point de données individuel de votre ensemble de données. représente le nombre total de points de données dans une population, représente le nombre total de points de données dans un échantillon, et est la moyenne de l’échantillon).
Notez les deux différences clés entre ces équations :
- Dans la somme du numérateur, est calculé en utilisant la moyenne de la population, alors que est calculé en utilisant la moyenne de l’échantillon, .
- Au dénominateur, divise par la taille de la population totale alors que divise par la taille de l’échantillon moins un, .
Il convient de noter que la distinction entre ces deux définitions est particulièrement importante pour les échantillons de petite taille. Comme grandit, la distinction entre et devient de moins en moins important.
Pourquoi sont-ils différents ?
Lors du calcul de la variance de la population, on suppose que vous disposez de toutes les données. Vous connaissez le centre exact (la population moyenne ) et à quelle distance exacte chaque point se trouve de ce centre. Diviser par le nombre total de points de données donne la moyenne vraie et exacte de ces carrés des différences.
Cependant, lors du calcul de la variance de l’échantillon, on ne suppose pas que vous disposez de toutes les données, vous ne disposez donc pas de la véritable moyenne de la population. . Au lieu de cela, vous disposez uniquement d’une estimation de qui est la moyenne de l’échantillon . Cependant, il s’avère que l’utilisation de la moyenne de l’échantillon au lieu de la moyenne réelle de la population a tendance à sous-estimer en moyenne la variance réelle de la population.
Cela se produit parce que la moyenne de l’échantillon est calculée directement à partir des données de l’échantillon, ce qui signifie qu’elle se situe exactement au centre mathématique de cet échantillon spécifique. En conséquence, les points de données de votre échantillon seront toujours plus proches de la moyenne de leur propre échantillon que de la moyenne réelle de la population, ce qui entraînera une somme artificiellement plus petite des carrés des différences.
Pour corriger cette sous-estimation, on applique ce qu’on appelle Correction de Bessel (du nom du mathématicien allemand Friedrich Wilhelm Bessel), où nous divisons non pas par mais légèrement plus petit pour corriger ce biais, car la division par un nombre plus petit rend la variance finale légèrement plus grande.
Degrés de liberté
Alors pourquoi diviser par et non ou ou toute autre correction qui augmente également la variance finale ? Cela revient à un concept appelé le Degrés de liberté.
Les degrés de liberté font référence au nombre de valeurs indépendantes dans un calcul qui sont libres de varier. Par exemple, imaginez que vous ayez un ensemble de 3 nombres, . Vous ne savez pas quelles sont leurs valeurs mais vous savez que leur échantillon signifie .
- Le premier numéro ça pourrait être n’importe quoi (disons 8)
- Le deuxième numéro ça pourrait aussi être n’importe quoi (disons 15)
- Parce que la moyenne doit être de 10, n’est pas libre de varier et doit être le seul nombre tel que qui dans ce cas est 7.
Ainsi, dans cet exemple, même s’il y a 3 nombres, il n’y a que deux degrés de liberté, car le fait d’appliquer la moyenne de l’échantillon supprime la capacité de l’un d’eux d’être libre de varier.
Dans le contexte de la variance, avant de faire tout calcul, on commence par degrés de liberté (correspondant à notre points de données). Le calcul de la moyenne de l’échantillon utilise essentiellement un degré de liberté, donc au moment où la variance de l’échantillon est calculée, il y a degrés de liberté restants pour travailler, c’est pourquoi est ce qui apparaît au dénominateur.
Valeurs par défaut de la bibliothèque et comment les aligner
Maintenant que nous comprenons le calcul, nous pouvons enfin résoudre le mystère du début de l’article ! numpy et pandas ont donné des résultats différents car ils utilisent par défaut des formules de variance différentes.
De nombreuses bibliothèques numériques contrôlent cela à l’aide d’un paramètre appelé ddofqui représente Degrés de liberté Delta. Cela représente la valeur soustraite du nombre total d’observations dans le dénominateur.
- Paramètre
ddof=0divise l’équation par en calculant le variance de la population. - Paramètre
ddof=1divise l’équation par en calculant le variance de l’échantillon.
Ceux-ci peuvent également être appliqués lors du calcul de l’écart type, qui n’est que la racine carrée de la variance.
Voici un aperçu de la façon dont les différentes bibliothèques populaires gèrent ces valeurs par défaut et comment vous pouvez les remplacer :
numpy
Par défaut, numpy suppose que vous calculez la variance de la population (ddof=0). Si vous travaillez avec un échantillon et devez appliquer la correction de Bessel, vous devez explicitement passer ddof=1.
import numpy as np
X = [15, 8, 13, 7, 7, 12, 15, 6, 8, 9]
# Sample variance and standard deviation
np.var(X, ddof=1)
np.std(X, ddof=1)
# Population variance and standard deviation (Default)
np.var(X)
np.std(X)pandas
Par défaut, pandas adopte la démarche inverse. Il suppose que vos données sont un échantillon et calcule la variance de l’échantillon (ddof=1). Pour calculer la variance de la population, vous devez plutôt passer ddof=0.
import pandas as pd
X = pd.Series([15, 8, 13, 7, 7, 12, 15, 6, 8, 9])
# Sample variance and standard deviation (Default)
X.var()
X.std()
# Population variance and standard deviation
X.var(ddof=0)
X.std(ddof=0)Python intégré statistics Module
La bibliothèque standard de Python n’utilise pas de ddof paramètre. Au lieu de cela, il fournit des fonctions explicitement nommées afin qu’il n’y ait aucune ambiguïté quant à la formule utilisée.
import statistics
X = [15, 8, 13, 7, 7, 12, 15, 6, 8, 9]
# Sample variance and standard deviation
statistics.variance(X)
statistics.stdev(X)
# Population variance and standard deviation
statistics.pvariance(X)
statistics.pstdev(X)R.
Dans R, la norme var() et sd() les fonctions calculent la variance de l’échantillon et l’écart type de l’échantillon par défaut. Contrairement aux bibliothèques Python, R n’a pas d’argument intégré pour passer facilement à la formule de population. Pour calculer la variance de la population, vous devez multiplier manuellement la variance de l’échantillon par .
X <- c(15, 8, 13, 7, 7, 12, 15, 6, 8, 9)
n <- length(X)
# Sample variance and standard deviation (Default)
var(X)
sd(X)
# Population variance and standard deviation
var(X) * ((n - 1) / n)
sd(X) * sqrt((n - 1) / n)Conclusion
Cet article a exploré un trait frustrant mais souvent inaperçu des différents langages et bibliothèques de programmation statistique : ils choisissent d’utiliser différentes définitions par défaut de la variance et de l’écart type. Un exemple a été donné où, pour le même tableau d’entrée, numpy et pandas renvoie des valeurs différentes pour la variance par défaut.
Cela se résumait à la différence entre la façon dont la variance devrait être calculée pour l’ensemble de la population statistique étudiée et la façon dont la variance devrait être calculée sur la base d’un seul échantillon de cette population, différentes bibliothèques faisant des choix différents concernant la valeur par défaut. Enfin, il a été montré que bien que chaque bibliothèque ait sa valeur par défaut, elles peuvent toutes être utilisées pour calculer les deux types de variance en utilisant soit un ddof argument, une fonction légèrement différente, ou via une simple transformation mathématique.
Merci d’avoir lu!
You may also like


