
RoPE, clairement expliqué | Vers la science des données
Il existe de nombreuses bonnes ressources en ligne expliquant l’architecture du transformateur, mais Incorporation de position rotative (RoPE) est souvent mal expliqué ou entièrement ignoré.
RoPE a été introduit pour la première fois dans le document RoFormer : transformateur amélioré avec intégration de position rotativeet bien que les opérations mathématiques impliquées soient relativement simples – principalement la matrice de rotation et les multiplications matricielles – le véritable défi réside dans la compréhension de l’intuition derrière son fonctionnement. Je vais essayer de fournir un moyen de visualiser ce qu’il fait aux vecteurs et d’expliquer pourquoi cette approche est si efficace.
Je suppose que vous avez une compréhension de base des transformateurs et du mécanisme d’attention tout au long de cet article.
Intuition RoPE
Étant donné que les transformateurs manquent de compréhension inhérente de l’ordre et des distances, les chercheurs ont développé des intégrations positionnelles. Voici ce que les intégrations positionnelles devraient accomplir :
- Les jetons plus proches les uns des autres devraient avoir des poids plus élevés, tandis que les jetons éloignés devraient avoir des poids plus faibles.
- La position dans une séquence ne devrait pas avoir d’importance, c’est-à-dire que si deux mots sont proches l’un de l’autre, ils doivent s’occuper l’un de l’autre avec des poids plus élevés, qu’ils apparaissent au début ou à la fin d’une longue séquence.
- Pour atteindre ces objectifs, intégrations positionnelles relatives sont bien plus utiles que les intégrations positionnelles absolues.
Aperçu clé: Les LLM devraient se concentrer sur les positions relatives entre deux jetons, ce qui est vraiment important pour l’attention.
Si vous comprenez ces concepts, vous êtes déjà à mi-chemin.
Avant RoPE
Les intégrations positionnelles originales de l’article fondateur L’attention est tout ce dont vous avez besoin ont été définis par une équation de forme fermée puis ajoutés aux plongements sémantiques. Mélanger les signaux de position et de sémantique à l’état caché n’était pas une bonne idée. Des recherches ultérieures ont confirmé que les LLM mémorisaient (sur-ajustaient) plutôt que de généraliser les positions, provoquant une détérioration rapide lorsque la longueur des séquences dépassait les données d’entraînement. Mais utiliser une formule fermée est logique, cela nous permet de l’étendre indéfiniment, et RoPE fait quelque chose de similaire.
Une stratégie qui s’est avérée efficace au début de l’apprentissage profond était la suivante : lorsque vous ne savez pas comment calculer des fonctionnalités utiles pour un réseau neuronal, laissez le réseau les apprendre lui-même ! C’est ce qu’ont fait des modèles comme GPT-3 : ils ont appris leurs propres intégrations de position. Cependant, accorder trop de liberté augmente les risques de surajustement et, dans ce cas, crée des limites strictes sur les fenêtres contextuelles (vous ne pouvez pas l’étendre au-delà de votre fenêtre contextuelle entraînée).
Les meilleures approches se sont concentrées sur la modification du mécanisme d’attention afin que les jetons proches reçoivent des poids d’attention plus élevés tandis que les jetons distants reçoivent des poids plus faibles. En isolant les informations de position dans le mécanisme d’attention, il préserve l’état caché et le maintient concentré sur la sémantique. Ces techniques cherchaient avant tout à modifier intelligemment Q et K leurs produits scalaires refléteraient donc la proximité. De nombreux articles ont tenté différentes méthodes, mais RoPE était celle qui résolvait le mieux le problème.
Intuition rotative
RoPE modifie Q et K en leur appliquant des rotations. L’une des propriétés les plus intéressantes de la rotation est qu’elle préserve les modules vectoriels (taille), qui transportent potentiellement des informations sémantiques.
Laisser q être la projection de requête d’un jeton et k être la projection clé d’un autre. Pour les jetons proches dans le texte, une rotation minimale est appliquée, tandis que les jetons distants subissent des transformations de rotation plus importantes.
Imaginez deux vecteurs de projection identiques : toute rotation les rendrait plus éloignés l’un de l’autre. C’est exactement ce que nous voulons.

Voici une situation potentiellement déroutante : si deux vecteurs de projection sont déjà éloignés l’un de l’autre, la rotation pourrait les rapprocher. C’est pas ce qu’on veut ! Ils subissent une rotation car ils sont éloignés dans le texte, ils ne devraient donc pas recevoir une attention élevée. Pourquoi est-ce que ça marche encore ?
- En 2D, il n’y a qu’un seul plan de rotation (
xy). Vous ne pouvez tourner que dans le sens des aiguilles d’une montre ou dans le sens inverse.
- En 3D, il existe une infinité de plans de rotation, ce qui rend très improbable que la rotation rapproche deux vecteurs.
- Les modèles modernes fonctionnent dans des espaces de très grande dimension (plus de 10 000 dimensions), ce qui rend cela encore plus improbable.
N’oubliez pas : dans le deep learning, ce sont les probabilités qui comptent le plus ! Il est acceptable de se tromper occasionnellement tant que les probabilités sont faibles.
Angle de rotation
L’angle de rotation dépend de deux facteurs : m et i. Examinons chacun.
Position absolue du jeton m
La rotation augmente à mesure que la position absolue du jeton m augmente.
Je sais à quoi tu penses : « m est la position absolue, mais n’avez-vous pas dit que les positions relatives comptent le plus ? »
Voici la magie : considérons un plan 2D dans lequel vous faites pivoter un vecteur de 𝛼 et un autre de β. La différence angulaire entre eux devient 𝛼-β. Les valeurs absolues de 𝛼 et β n’ont pas d’importance, seule leur différence compte. Donc pour deux jetons aux positions m et nla rotation modifie l’angle entre eux proportionnellement à m-n.

Pour simplifier, nous pouvons penser que nous ne faisons que tourner
q(c’est mathématiquement précis puisque nous nous soucions des distances finales, pas des coordonnées).
Index d’état caché i
Au lieu d’appliquer une rotation uniforme sur toutes les dimensions de l’état caché, RoPE traite deux dimensions à la fois, en appliquant des angles de rotation différents à chaque paire. En d’autres termes, il divise le vecteur long en plusieurs paires qui peuvent pivoter en 2D selon différents angles.
Nous faisons pivoter les dimensions de l’état caché différemment : la rotation est plus élevée lorsque i est faible (début du vecteur) et inférieur lorsque i est élevé (fin du vecteur).
Comprendre cette opération est simple, mais comprendre pourquoi nous en avons besoin nécessite plus d’explications :
- Cela permet au modèle de choisir ce qui devrait avoir portées d’influence plus ou moins longues.
- Imaginez des vecteurs en 3D (
xyz).
- Le
xetyles axes représentent les premières dimensions (faiblei) qui subissent une rotation plus élevée. Des jetons projetés principalement surxetyil faut être très proche pour y assister avec une haute intensité.
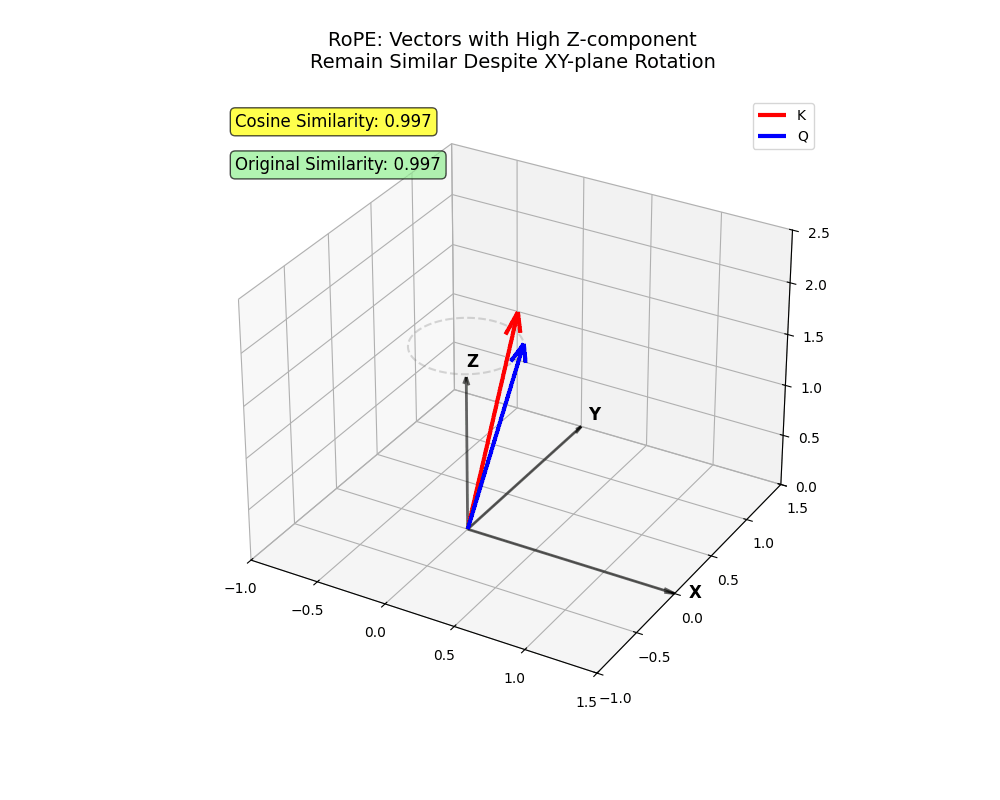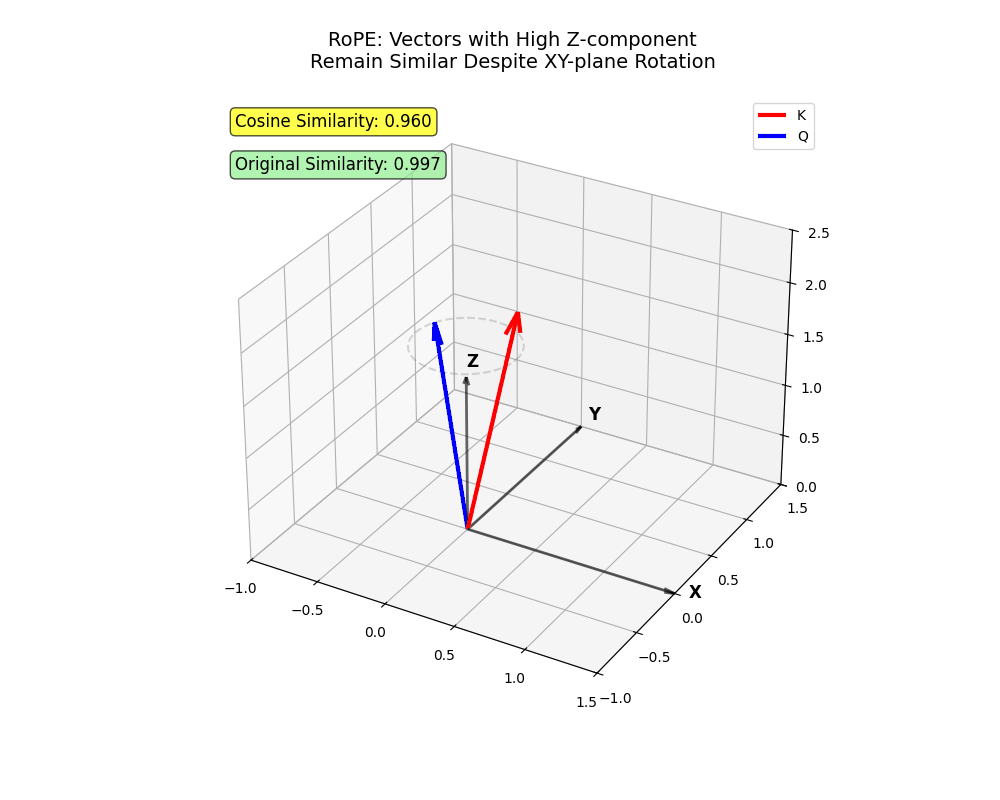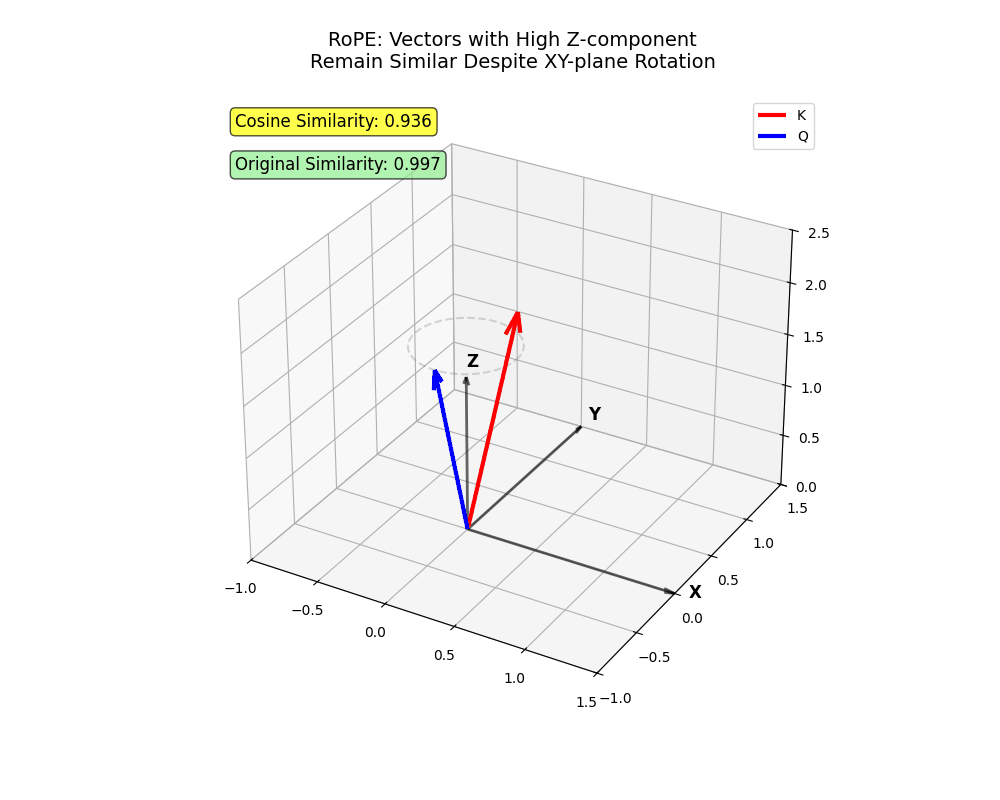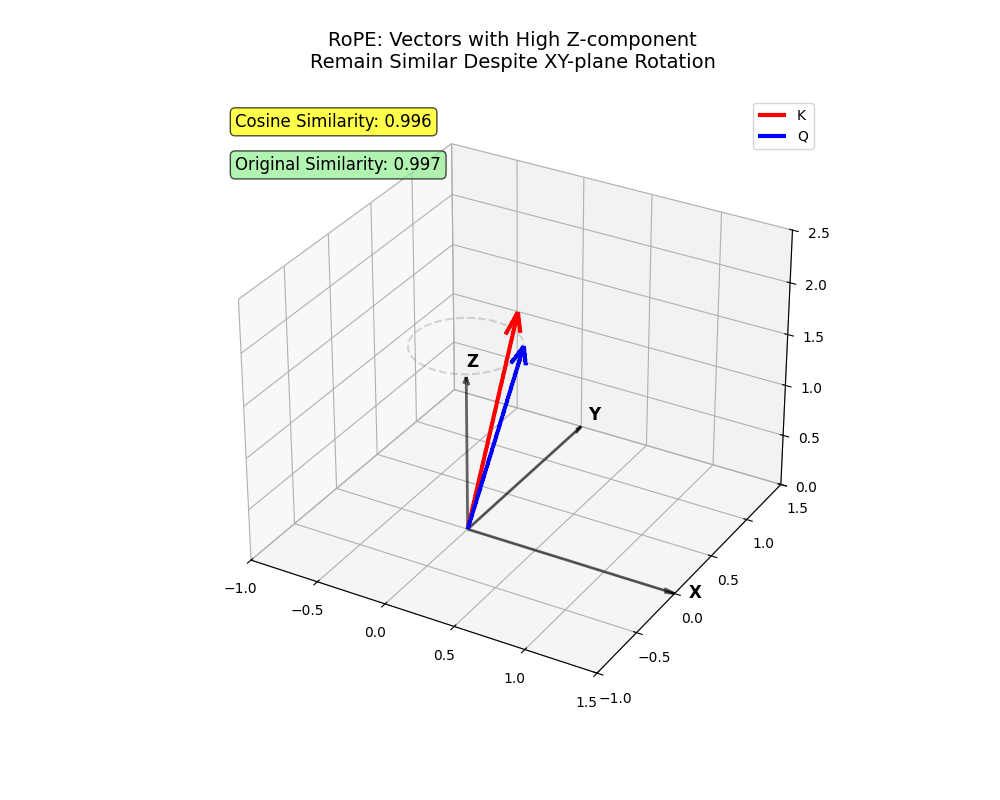
- Le
zaxe, oùiest plus haut, tourne moins. Des jetons projetés principalement surzpeut y assister même à distance.

xy avion. Deux vecteurs codant des informations principalement en z rester proches malgré la rotation (des jetons qui devraient être présents malgré des distances plus longues !)
x et y deviennent très éloignés (jetons proches où l’un ne doit pas s’occuper de l’autre).Cette structure capture les nuances complexes du langage humain – plutôt cool, non ?
Encore une fois, je sais ce que vous pensez : « après trop de rotation, ils recommencent à se rapprocher ».
C’est exact, mais voici pourquoi cela fonctionne toujours :
- Nous visualisons en 3D, mais cela se produit en réalité dans des dimensions beaucoup plus élevées.
- Bien que certaines dimensions se rapprochent, d’autres qui tournent plus lentement continuent de s’éloigner. D’où l’importance de faire pivoter les dimensions selon différents angles.
- RoPE n’est pas parfait : en raison de sa nature rotationnelle, des maxima locaux se produisent. Voir le tableau théorique des auteurs originaux :

La courbe théorique présente quelques bosses folles, mais en pratique je l’ai trouvée beaucoup plus sage :

Une idée qui m’est venue était de couper l’angle de rotation afin que la similarité diminue strictement avec l’augmentation de la distance. J’ai vu le découpage appliqué à d’autres techniques, mais pas à RoPE.
Gardez à l’esprit que la similarité cosinusoïdale a tendance à croître (bien que lentement) à mesure que la distance dépasse considérablement notre valeur de base (plus tard, vous verrez exactement quelle est cette base de la formule). Une solution simple ici consiste à augmenter la base, ou même à laisser des techniques telles que l’attention locale ou la fenêtre s’en occuper.

Conclusion : le LLM apprend à projeter une influence significative à long terme et à court terme dans différentes dimensions de q et k.
Voici quelques exemples concrets de dépendances à long et à court terme :
- Le LLM traite le code Python où une transformation initiale est appliquée à une trame de données
df. Ces informations pertinentes devraient potentiellement se propager sur une longue période et influencer l’intégration contextuelle des informations en aval.dfjetons.
- Les adjectifs caractérisent généralement proche noms. Dans « Une belle montagne s’étend au-delà de la vallée », l’adjectif beau décrit spécifiquement le montagnepas le valléecela devrait donc principalement affecter le montagne intégration.
La formule des angles
Maintenant que vous comprenez les concepts et que vous avez une forte intuition, voici les équations. L’angle de rotation est défini par :
\[\text{angle} = m \times \theta\]
\[\theta = 10,000^{-2(i-1)/d_{model}}\]
mest la position absolue du jeton
- i ∈ {1, 2, …, d/2} représentant les dimensions d’état cachées, puisque nous traitons deux dimensions à la fois, il suffit de parcourir
d/2plutôt qued.
d<sub>model</sub>est la dimension de l’état caché (par exemple, 4 096)
Notez que lorsque :
\[i=1 \Rightarrow \theta=1 \quad \text{(high rotation)} \]
\[i=d/2 \Rightarrow \theta \approx 1/10,000 \quad \text{(low rotation)}\]
Conclusion
- Nous devrions trouver des moyens intelligents d’injecter des connaissances dans les LLM plutôt que de les laisser tout apprendre de manière indépendante.
- Nous y parvenons en fournissant les opérations appropriées dont un réseau neuronal a besoin pour traiter les données – l’attention et les convolutions en sont d’excellents exemples.
- Les équations de forme fermée peuvent s’étendre indéfiniment puisque vous n’avez pas besoin d’apprendre chaque intégration de position.
- C’est pourquoi RoPE offre une excellente flexibilité en matière de longueur de séquence.
- Propriété la plus importante : le poids de l’attention diminue à mesure que les distances relatives augmentent.
- Cela suit la même intuition que l’attention locale dans les architectures d’attention alternée.


