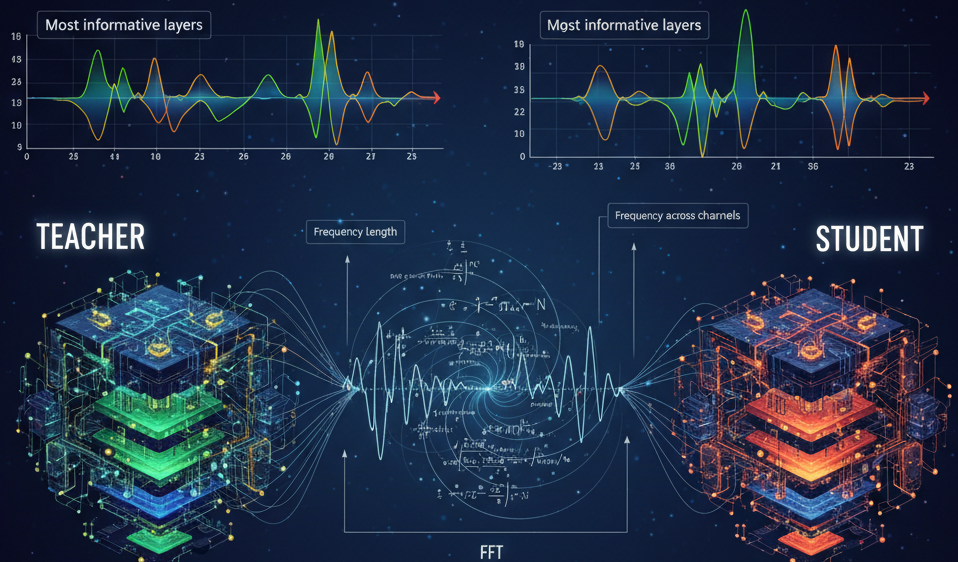
Alors que je travaillais sur mon problème de distillation des connaissances pour la classification des intentions, j’ai été confronté à un obstacle déroutant. Ma configuration impliquait un modèle d’enseignant, qui est RoBERTa-large (affiné sur ma classification d’intention), et un modèle d’étudiant, que j’essayais de former sans perdre trop de précision par rapport à l’enseignant.
J’ai expérimenté plusieurs techniques de cartographie, en connectant une couche sur deux à la couche des étudiants, en faisant la moyenne de deux couches d’enseignants en une seule et même en attribuant des poids personnalisés comme donner (0,3 à l1 et 0,7 à l2). Mais quelle que soit la combinaison que j’essayais, la précision de l’enseignant ne correspondait jamais au modèle de l’élève.
C’est à ce moment-là que j’ai commencé à explorer comment cartographier les couches les plus informatives à mon modèle étudiant afin que l’étudiant puisse maximiser ses performances. Je voulais un moyen de quantifier quelle couche du modèle d’enseignant était vraiment importante pour la distillation.
Curieux, j’ai décidé d’adapter l’idée aux données textuelles – et BOUM !!!, ça a vraiment marché !Pour la première fois, mon modèle étudiant a commencé à penser presque comme son professeur.
Source : Auteur
Voici le graphique d’intensité de couche de mon réglage RoBERTa-grand modèle. Sur la base des informations spectrales, j’ai sélectionné couches 1 à 9 et 21 à 23 pour mon modèle étudiant lors de la distillation des connaissances, ceux qui contiennent les informations les plus riches.
Je ne peux pas partager mon ensemble de données ou mon code pour des raisons de confidentialité, mais je vais vous expliquer comment l’approche basée sur l’image du papier inspiré mon adaptation basée sur du texteet comment vous pouvez envisager de faire de même.
Dans les coulisses : comment FFT révèle l’âme spectrale d’un modèle
Alors, commençons par intensité spectraleet plongez lentement dans le véritable magicien ici : le Transformée de Fourier rapide (FFT).
Dans le papier spectralKDles auteurs présentent un cadre qui nous aide à voir Vision Transformer(ViTs), non seulement ce qu’ils prédisent, mais aussi comment les informations circulent dans les couches. Au lieu de s’appuyer sur l’intuition ou la visualisation, ils utilisent l’analyse spectrale, un moyen mesurer la richesse fréquentielle des représentations internes du modèle.
Imaginez chaque couche de Transformer en tant que musicien dans un orchestre, certaines couches jouent des notes aiguës (détails fins), tandis que d’autres jouent des notes graves (caractéristiques générales). La FFT nous aide à écouter la musique de chaque joueur séparément et à filtrer celui qui possède les mélodies les plus fortes, c’est-à-dire les signaux les plus riches en informations.
Source : Auteur
Étape 1 : Cartes de fonctionnalités, La matière première
B est la taille du lot C est le nombre de canaux et, H, W est la hauteur et la largeur spatiales.
Étape 2 : Application de la transformée de Fourier
Les auteurs appliquent une FFT unidimensionnelle le long de la dimension du canal pour traduire ces activations à valeur réelle dans le domaine fréquentiel : F(X)=FFT(X)
Cela signifie: Pour chaque emplacement spatial (b, h, w), un FFT 1D est calculé sur tous les canaux. Le résultat est un tenseur à valeurs complexes (puisque FFT produit des parties réelles + imaginaires). F(X) nous indique donc quelle quantité de chaque fréquence est présente dans la représentation de cette couche.
Et si vous vous demandez, « Mais pourquoi FFT ? – retiens cette pensée. Parce que plus tard dans ce blog, nous allons découvrir exactement pourquoi FFT est l’outil parfait pour mesurer l’intensité intérieure d’un modèle.
Étape 3 : mesurer la force de la fréquence
Re(F(X)) est la vraie partie, Je suis(F(X)) est la partie imaginaire.
Étape 4 : Calculer la moyenne sur la carte
Nous voulons maintenant résumer cette intensité sur toutes les positions de la couche :
Cette étape nous indique l’intensité moyenne du canal unique
Et puis vous pouvez simplement faire la moyenne de chaque chaîne. Voilà ! Vous avez maintenant l’intensité spectrale de la couche unique du Vision Transformer.
Un aperçu du domaine des fréquences : la lentille de Fourier de SpectralKD
Examinons la transformée de Fourier rapide :
Xₖ est la séquence d’entrée (votre signal, fonctionnalité ou modèle d’activation). xₙ est la composante fréquentielle à l’indice de fréquence. N est le nombre de points dans la séquence (c’est-à-dire le nombre de canaux ou de fonctionnalités).
Chaque terme e⁻ʲ²πᵏⁿ/ᴺ agit comme un phaseur rotatifune petite onde complexe tournant à travers l’espace du signal, et ensemble, elles forment l’une des plus belles idées en matière de traitement du signal.
Source : Auteur (Ici, un phaseur en rotation e⁻ʲ²πᵏⁿ/ᴺ est multiplié par g
source : Auteur (Faites la moyenne de tous les points du plan complexe, cela vous donnera alors le centre de masse de l’entité phaseuse, et il n’atteindra son apogée qu’à une fréquence spécifique ou K (dans le cas ci-dessus, c’est 3))
.OH MON DIEU! Que s’est-il passé ici ? Laissez-moi le décomposer.
Lorsque vous multipliez vos activations cachées xₙ (par exemple, sur tous les canaux ou dimensions des fonctionnalités) par ce phaseur, vous demandez essentiellement :
« Hé, Layer, combien de k-ème type de variation contiennent-ils dans vos représentations ?
Chaque fréquence k correspond à une fréquence distincte échelle de motif à travers les dimensions des fonctionnalités.
Capture des valeurs k inférieures structures sémantiques larges et fluides (comme le contexte au niveau du sujet), tandis que les valeurs k plus élevées capturent variations rapides et fines (comme les nuances au niveau des jetons ou les signaux syntaxiques).
Voici maintenant la partie amusante : si une couche résonne avec un modèle de fréquence particulier, la multiplication de la transformée de Fourier s’aligne parfaitement et la somme dans la formule de Fourier produit un forte réponse pour ça k.
Sinon, les rotations s’annulent, ce qui signifie que la fréquence ne joue pas un grand rôle dans la représentation de cette couche.
Ainsi, la transformée de Fourier n’ajoute rien de nouveau ; il s’agit simplement de découvrir comment notre couche code les informations à différentes échelles d’abstraction.
C’est comme faire un zoom arrière et réaliser :
Certaines couches bourdonnent doucement avec des significations conceptuelles douces (basses fréquences),
D’autres bourdonnent d’interactions nettes et détaillées entre les jetons (hautes fréquences).
La FFT en gros transforme les états cachés d’une couche en une empreinte de fréquence – une carte des types d’informations sur lesquels cette couche se concentre.
Et c’est exactement ce que SpectralKD utilise pour déterminer quelles couches sont en fait, je fais le gros du travail lors de la distillation des connaissances.
De la vision au langage : comment l’intensité spectrale a guidé mon classificateur d’intention
Source : Auteur
Soit un tenseur d’activation de couche :
où:
N = nombre d’échantillons (taille du lot)
L = longueur de la séquence (nombre de jetons/pas de temps)
H = dimension cachée (nombre de canaux/fonctionnalités produits par la couche)
Chaque échantillon i a une matrice d’activation Xᵢ ∈ Rᴸ ˣ ᴴ (positions de séquence x fonctionnalités cachées)
Là encore, vous pouvez calculer la FFT de ce Xᵢ, puis mesurer la longueur de fréquence en utilisant les composantes réelles et imaginaires et faire la moyenne sur les canaux, puis pour chaque couche.
Longueur de fréquence :
Fréquence sur tous les canaux :
Fréquence sur une couche :
Ici, K est le nombre de bacs retenus.
Conclusion
Leur analyse montre deux enseignements majeurs :
Toutes les couches ne contribuent pas de la même manière. Dans les architectures de transformateurs uniformes, seuls quelques tôt et final les couches présentent une forte activité spectrale, véritables « points chauds » du flux d’informations.
Différents types de transformateurs, mélodies similaires. Malgré les variations architecturales, les transformateurs hiérarchiques et uniformes partagent des modèles spectraux étonnamment similaires, faisant allusion à une manière universelle dont ces modèles apprennent et représentent les connaissances.
S’appuyant sur ces résultats, SpectralKD introduit un Distillation de connaissances simple et sans paramètres (KD) stratégie. En alignant sélectivement le comportement spectral des couches initiales et finales entre un modèle d’enseignant et un modèle d’élève, l’élève apprend à imiter la signature spectrale de l’enseignantmême dans les couches intermédiaires qui n’ont jamais été explicitement alignées.
Les résultats sont frappants dans l’article : l’étudiant distillé (DeiT-Tiny) n’égale pas seulement les performances sur des benchmarks comme ImageNet-1K, il apprend à penser spectralement comme le professeurcapturant des informations à la fois locales et mondiales avec une remarquable allégeance.
En fin de compte, SpectralKD relie interprétabilité et distillationoffrant une nouvelle façon de visualiser ce qui se passe à l’intérieur des transformateurs pendant l’apprentissage. Cela ouvre une nouvelle ligne de recherche, appellent les auteurs « dynamique de distillation »un voyage dans la façon dont la connaissance elle-même circule, oscille et s’harmonise entre les réseaux d’enseignants et d’étudiants.