
Pourquoi mon code est-il si lent ? Un guide du profilage Py-Spy Python
Les problèmes frustrants à déboguer dans le code de science des données ne sont pas des erreurs de syntaxe ou des erreurs logiques. Au contraire, ils proviennent d’un code qui fait exactement ce qu’il est censé faire, mais prend son temps pour le faire.
Un code fonctionnel mais inefficace peut constituer un énorme goulot d’étranglement dans un flux de travail de science des données. Dans cet article, je fournirai une brève introduction et une présentation pas à pas de py-spyun outil puissant conçu pour profiler votre code Python. Il peut identifier exactement où votre programme passe le plus de temps afin que les inefficacités puissent être identifiées et corrigées.
Exemple de problème
Définissons une question de recherche simple pour écrire du code pour :
« Pour tous les vols à destination des États et territoires américains, quel aéroport de départ propose en moyenne les vols les plus longs ? »
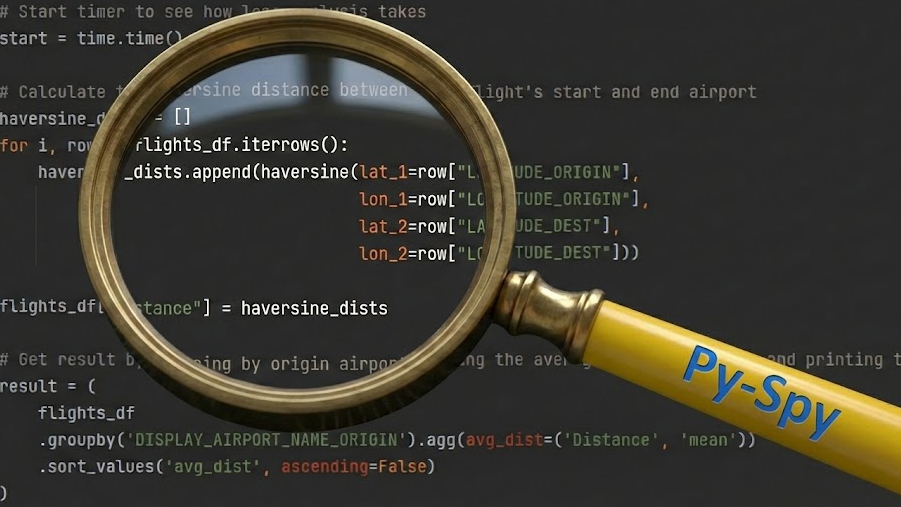
Vous trouverez ci-dessous un simple script Python pour répondre à cette question de recherche, en utilisant les données extraites du Bureau des statistiques des transports (BTS). L’ensemble de données comprend des données sur chaque vol dans les États et territoires américains entre janvier et juin 2025, avec des informations sur les aéroports d’origine et de destination. Il s’agit d’environ 3,5 millions de lignes.
Il calcule le Distance d’Haversine — la distance la plus courte entre deux points sur une sphère — pour chaque vol. Ensuite, il regroupe les résultats par aéroport de départ pour trouver la distance moyenne et présente les cinq premiers.
import pandas as pd
import math
import time
def haversine(lat_1, lon_1, lat_2, lon_2):
"""Calculate the Haversine Distance between two latitude and longitude points"""
lat_1_rad = math.radians(lat_1)
lon_1_rad = math.radians(lon_1)
lat_2_rad = math.radians(lat_2)
lon_2_rad = math.radians(lon_2)
delta_lat = lat_2_rad - lat_1_rad
delta_lon = lon_2_rad - lon_1_rad
R = 6371 # Radius of the earth in km
return 2*R*math.asin(math.sqrt(math.sin(delta_lat/2)**2 + math.cos(lat_1_rad)*math.cos(lat_2_rad)*(math.sin(delta_lon/2))**2))
if __name__ == '__main__':
# Load in flight data to a dataframe
flight_data_file = r"./data/2025_flight_data.csv"
flights_df = pd.read_csv(flight_data_file)
# Start timer to see how long analysis takes
start = time.time()
# Calculate the haversine distance between each flight's start and end airport
haversine_dists = []
for i, row in flights_df.iterrows():
haversine_dists.append(haversine(lat_1=row["LATITUDE_ORIGIN"],
lon_1=row["LONGITUDE_ORIGIN"],
lat_2=row["LATITUDE_DEST"],
lon_2=row["LONGITUDE_DEST"]))
flights_df["Distance"] = haversine_dists
# Get result by grouping by origin airport, taking the average flight distance and printing the top 5
result = (
flights_df
.groupby('DISPLAY_AIRPORT_NAME_ORIGIN').agg(avg_dist=('Distance', 'mean'))
.sort_values('avg_dist', ascending=False)
)
print(result.head(5))
# End timer and print analysis time
end = time.time()
print(f"Took {end - start} s")L’exécution de ce code donne le résultat suivant :
avg_dist
DISPLAY_AIRPORT_NAME_ORIGIN
Pago Pago International 4202.493567
Guam International 3142.363005
Luis Munoz Marin International 2386.141780
Ted Stevens Anchorage International 2246.530036
Daniel K Inouye International 2211.857407
Took 169.8935534954071 sCes résultats sont logiques, car les aéroports répertoriés se trouvent respectivement aux Samoa américaines, à Guam, à Porto Rico, en Alaska et à Hawaï. Ce sont tous des endroits en dehors des États-Unis contigus où l’on pourrait s’attendre à de longues distances de vol moyennes.
Le problème ici ne vient pas des résultats — qui sont valides — mais du temps d’exécution : presque trois minutes! Même si trois minutes peuvent être tolérables pour une exécution ponctuelle, cela nuit à la productivité pendant le développement. Imaginez cela dans le cadre d’un pipeline de données plus long. Chaque fois qu’un paramètre est modifié, qu’un bug est corrigé ou qu’une cellule est réexécutée, vous êtes obligé de rester inactif pendant l’exécution du programme. Ces frictions interrompent votre flux et transforment une analyse rapide en une affaire qui dure tout l’après-midi.
Voyons maintenant comment py-spy peut nous aider à diagnostiquer exactement quelles lignes prennent autant de temps.
Qu’est-ce que Py-Spy ?
Pour comprendre ce que py-spy ce que fait et les avantages de son utilisation, il est utile de comparer py-spy au profileur Python intégré cProfile.
cProfile: C’est un Profileur de traçagefonctionnant comme un chronomètre à chaque appel de fonction. Le temps entre chaque appel de fonction et son retour est mesuré et signalé. Bien que très précis, cela ajoute une surcharge importante, car le profileur doit constamment mettre en pause et enregistrer des données, ce qui peut ralentir considérablement le script.py-spy: C’est un Profileur d’échantillonnagefonctionnant de la même manière qu’une caméra à grande vitesse observant l’ensemble du programme en même temps.py-spyse trouve complètement en dehors du script Python en cours d’exécution et prend des instantanés à haute fréquence de l’état du programme. Il examine l’ensemble de la « pile d’appels » pour voir exactement quelle ligne de code est exécutée et quelle fonction l’a appelée, jusqu’au niveau supérieur.
Exécuter Py-spy
Afin de courir py-spy sur un script Python, le py-spy La bibliothèque doit être installée dans l’environnement Python.
pip install py-spyUne fois le py-spy bibliothèque est installée, notre script peut être profilé en exécutant la commande suivante dans le terminal :
py-spy record -o profile.svg -r 100 -- python main.pyVoici ce que fait réellement chaque partie de cette commande :
py-spy: Appelle l’outil.record: Cela racontepy-spypour utiliser son mode « enregistrement », qui surveillera en permanence le programme pendant son exécution et enregistrera les données.-o profile.svg: Ceci spécifie le nom et le format du fichier de sortie, lui indiquant d’afficher les résultats sous forme de fichier SVG appeléprofile.svg.-r 100: Ceci spécifie le taux d’échantillonnage, en le réglant à 100 fois par seconde. Cela signifie quepy-spyvérifiera ce que fait le programme 100 fois par seconde.--: Cela sépare lepy-spycommande à partir de la commande de script Python. Ça racontepy-spyque tout ce qui suit ce drapeau est la commande à exécuter, pas des arguments pourpy-spylui-même.python main.py: Il s’agit de la commande permettant d’exécuter le script Python avec lequel le profil sera effectué.py-spydans ce cas en cours d’exécutionmain.py.
Note: Si vous utilisez Linux, sudo les privilèges sont souvent requis pour exécuter py-spypour des raisons de sécurité.
Une fois l’exécution de cette commande terminée, un fichier de sortie profile.svg apparaîtra, ce qui nous permettra d’approfondir quelles parties du code prennent le plus de temps.
Sortie Py-spy

Ouverture de la sortie profile.svg révèle la visualisation qui py-spy a créé le temps que notre programme a passé dans différentes parties du code. C’est ce qu’on appelle un Graphique de glaçons (ou parfois un Graphique de flamme si l’axe des y est inversé) et est interprété comme suit :
- Barres: Chaque barre colorée représente une fonction particulière qui a été appelée lors de l’exécution du programme.
- Axe X (Population): L’axe horizontal représente la collecte de tous les échantillons prélevés lors du profilage. Ils sont regroupés de manière à ce que la largeur d’une barre particulière représente la proportion du total d’échantillons dans laquelle le programme se trouvait dans la fonction représentée par cette barre. Note: C’est pas un calendrier ; l’ordre ne représente pas le moment où la fonction a été appelée, seulement le volume total de temps passé.
- Axe Y (profondeur de la pile): L’axe vertical représente la pile d’appels. La barre supérieure intitulée « tout » représente l’ensemble du programme et les barres situées en dessous représentent les fonctions appelées depuis « tout ». Cela continue de manière récursive, chaque barre étant décomposée en fonctions appelées lors de son exécution. La barre tout en bas montre la fonction qui était réellement en cours d’exécution sur le processeur lorsque l’échantillon a été prélevé.
Interagir avec le graphique
Bien que l’image ci-dessus soit statique, la réalité .svg fichier généré par py-spy est entièrement interactif. Lorsque vous l’ouvrez dans un navigateur Web, vous pouvez :
- Rechercher (Ctrl+F): Mettez en surbrillance des fonctions spécifiques pour voir où elles apparaissent dans la pile.
- Zoom: cliquez sur n’importe quelle barre pour zoomer sur cette fonction spécifique et ses enfants, vous permettant ainsi d’isoler les parties complexes de la pile d’appels.
- Flotter: Le survol d’une barre affiche le nom de la fonction spécifique, le chemin du fichier, le numéro de ligne et le pourcentage exact de temps consommé.
La règle la plus critique pour lire le graphique de glaçon est simplement : Plus la barre est large, plus la fonction est fréquente. Si une barre de fonction s’étend sur 50 % de la largeur du graphique, cela signifie que le programme travaillait à l’exécution de cette fonction pendant 50 % de la durée d’exécution totale.
Diagnostic
À partir du graphique de glaçon ci-dessus, nous pouvons voir que la barre représentant les Pandas iterrows() la fonction est sensiblement large. En survolant cette barre lors de l’affichage du profile.svg Le fichier révèle que la véritable proportion de cette fonction était 68,36%. Ainsi, plus des 2/3 du temps d’exécution ont été consacrés au iterrows() fonction. Intuitivement, ce goulot d’étranglement est logique, car iterrows() crée un objet Pandas Series pour chaque ligne de la boucle, ce qui entraîne une surcharge massive. Cela révèle un objectif clair pour essayer d’optimiser le temps d’exécution du script.
Optimiser le script
Le chemin le plus clair pour optimiser ce script en fonction de ce qui a été appris py-spy est d’arrêter d’utiliser iterrows() faire une boucle sur chaque ligne pour calculer cette distance haversine. Au lieu de cela, il doit être remplacé par un calcul vectorisé utilisant NumPy qui effectuera le calcul pour chaque ligne avec un seul appel de fonction. Les modifications à apporter sont donc :
- Réécrire le
haversine()fonction pour utiliser des opérations NumPy de niveau C vectorisées et efficaces qui permettent de transmettre des tableaux entiers plutôt qu’un ensemble de coordonnées à la fois. - Remplacez le
iterrows()boucle avec un seul appel à ce nouveau vectoriséhaversine()fonction.
import pandas as pd
import numpy as np
import time
def haversine(lat_1, lon_1, lat_2, lon_2):
"""Calculate the Haversine Distance between two latitude and longitude points"""
lat_1_rad = np.radians(lat_1)
lon_1_rad = np.radians(lon_1)
lat_2_rad = np.radians(lat_2)
lon_2_rad = np.radians(lon_2)
delta_lat = lat_2_rad - lat_1_rad
delta_lon = lon_2_rad - lon_1_rad
R = 6371 # Radius of the earth in km
return 2*R*np.asin(np.sqrt(np.sin(delta_lat/2)**2 + np.cos(lat_1_rad)*np.cos(lat_2_rad)*(np.sin(delta_lon/2))**2))
if __name__ == '__main__':
# Load in flight data to a dataframe
flight_data_file = r"./data/2025_flight_data.csv"
flights_df = pd.read_csv(flight_data_file)
# Start timer to see how long analysis takes
start = time.time()
# Calculate the haversine distance between each flight's start and end airport
flights_df["Distance"] = haversine(lat_1=flights_df["LATITUDE_ORIGIN"],
lon_1=flights_df["LONGITUDE_ORIGIN"],
lat_2=flights_df["LATITUDE_DEST"],
lon_2=flights_df["LONGITUDE_DEST"])
# Get result by grouping by origin airport, taking the average flight distance and printing the top 5
result = (
flights_df
.groupby('DISPLAY_AIRPORT_NAME_ORIGIN').agg(avg_dist=('Distance', 'mean'))
.sort_values('avg_dist', ascending=False)
)
print(result.head(5))
# End timer and print analysis time
end = time.time()
print(f"Took {end - start} s")L’exécution de ce code donne le résultat suivant :
avg_dist
DISPLAY_AIRPORT_NAME_ORIGIN
Pago Pago International 4202.493567
Guam International 3142.363005
Luis Munoz Marin International 2386.141780
Ted Stevens Anchorage International 2246.530036
Daniel K Inouye International 2211.857407
Took 0.5649983882904053 sCes résultats sont identiques à ceux d’avant l’optimisation du code, mais au lieu de prendre près de trois minutes à traiter, cela a pris un peu plus d’une demi-seconde !
Regarder vers l’avenir
Si vous lisez ceci depuis le futur (fin 2026 ou au-delà), vérifiez si vous utilisez Python 3.15 ou une version plus récente. Python 3.15 devrait introduire un profileur d’échantillonnage natif dans la bibliothèque standard, offrant des fonctionnalités similaires à py-spy sans nécessiter d’installation externe. Pour toute personne utilisant Python 3.14 ou version antérieure py-spy reste l’étalon-or.
Cet article a exploré un outil pour lutter contre une frustration courante dans la science des données : un script qui fonctionne comme prévu, mais est écrit de manière inefficace et prend beaucoup de temps à s’exécuter. Un exemple de script a été fourni pour savoir quels aéroports de départ américains ont la distance de vol moyenne la plus longue en fonction de la distance Haversine. Ce script a fonctionné comme prévu, mais son exécution a pris près de trois minutes.
En utilisant le py-spy Profileur Python, nous avons pu apprendre que la cause de l’inefficacité était l’utilisation du iterrows() fonction. En remplaçant iterrows() grâce à un calcul vectoriel plus efficace de la distance Haversine, la durée d’exécution a été optimisée de trois minutes à un peu plus d’une demi-seconde.
Voir mon Dépôt GitHub pour le code de cet article, y compris le prétraitement des données brutes de BTS.
Merci d’avoir lu!
Sources de données
Les données du Bureau of Transportation Statistics (BTS) sont une œuvre du gouvernement fédéral américain et sont dans le domaine public sous 17 USC § 105. Son utilisation, son partage et son adaptation sont gratuits, sans restriction de droit d’auteur.


