
Pourquoi les installations de packages sont lentes (et comment y remédier)
connaît l’attente. Vous tapez une commande d’installation et regardez le curseur clignoter. Le gestionnaire de packages parcourt son index. Les secondes s’étirent. Vous vous demandez si quelque chose s’est cassé.
Ce retard a une cause spécifique : le gonflement des métadonnées. De nombreux gestionnaires de packages maintiennent un index monolithique de chaque package, version et dépendance disponible. À mesure que les écosystèmes se développent, ces indices évoluent avec eux. Conda-forge dépasse les 31 000 packages sur plusieurs plates-formes et architectures. D’autres écosystèmes sont confrontés à des défis à une échelle similaire avec des centaines de milliers de packages.
Lorsque les gestionnaires de packages utilisent des index monolithiques, votre client télécharge et analyse le tout pour chaque opération. Vous récupérez les métadonnées des packages que vous n’utiliserez jamais. Le problème s’aggrave : plus de packages signifient des index plus volumineux, des téléchargements plus lents, une consommation de mémoire plus élevée et des temps de construction imprévisibles.
Ceci n’est pas propre à un seul gestionnaire de packages. Il s’agit d’un problème d’échelle qui affecte tout écosystème de packages proposant des milliers de packages à des millions d’utilisateurs.
L’architecture des index de packages
Conda-forge, comme certains gestionnaires de packages, distribue son index sous forme de fichier unique. Cette conception présente des avantages : le solveur obtient toutes les informations dont il a besoin dès le départ en une seule requête, ce qui permet une résolution efficace des dépendances sans délais aller-retour. Lorsque les écosystèmes étaient petits, un index de 5 Mo était téléchargé en quelques secondes et analysé avec un minimum de mémoire.
À grande échelle, la conception s’effondre.
Pensez à conda-forge, l’une des plus grandes chaînes de packages communautaires pour Python scientifique. Son fichier repodata.json, qui contient les métadonnées de tous les packages disponibles, dépasse 47 Mo compressés (363 Mo non compressés). Chaque opération d’environnement nécessite l’analyse de ce fichier. Lorsqu’un package de la chaîne change – ce qui arrive fréquemment avec les nouvelles versions – l’intégralité du fichier doit être retéléchargé. Une seule nouvelle version du package invalide l’intégralité de votre cache. Les utilisateurs téléchargent à nouveau plus de 47 Mo pour accéder à une mise à jour.
Les conséquences sont mesurables : des temps de récupération de plusieurs secondes sur des connexions rapides, des minutes sur des réseaux plus lents, des pics de mémoire lors de l’analyse du fichier JSON de 363 Mo et des pipelines CI qui consacrent plus de temps à la résolution des dépendances qu’aux builds réels.
Sharding : une approche différente
La solution emprunte à l’architecture de base de données. Au lieu d’un index monolithique, vous divisez les métadonnées en plusieurs petits morceaux. Chaque package obtient son propre « fragment » contenant uniquement ses métadonnées. Les clients récupèrent les fragments dont ils ont besoin et ignorent le reste.
Ce modèle apparaît dans les systèmes distribués. Le partitionnement de la base de données partitionne les données sur les serveurs. Les réseaux de diffusion de contenu mettent en cache les actifs par région. Les moteurs de recherche distribuent les index entre les clusters. Le principe est cohérent : lorsqu’une seule structure de données devient trop volumineuse, divisez-la.
Appliqué à la gestion des packages, le sharding transforme la récupération des métadonnées de « tout télécharger, utiliser peu » à « télécharger ce dont vous avez besoin, utiliser tout ».
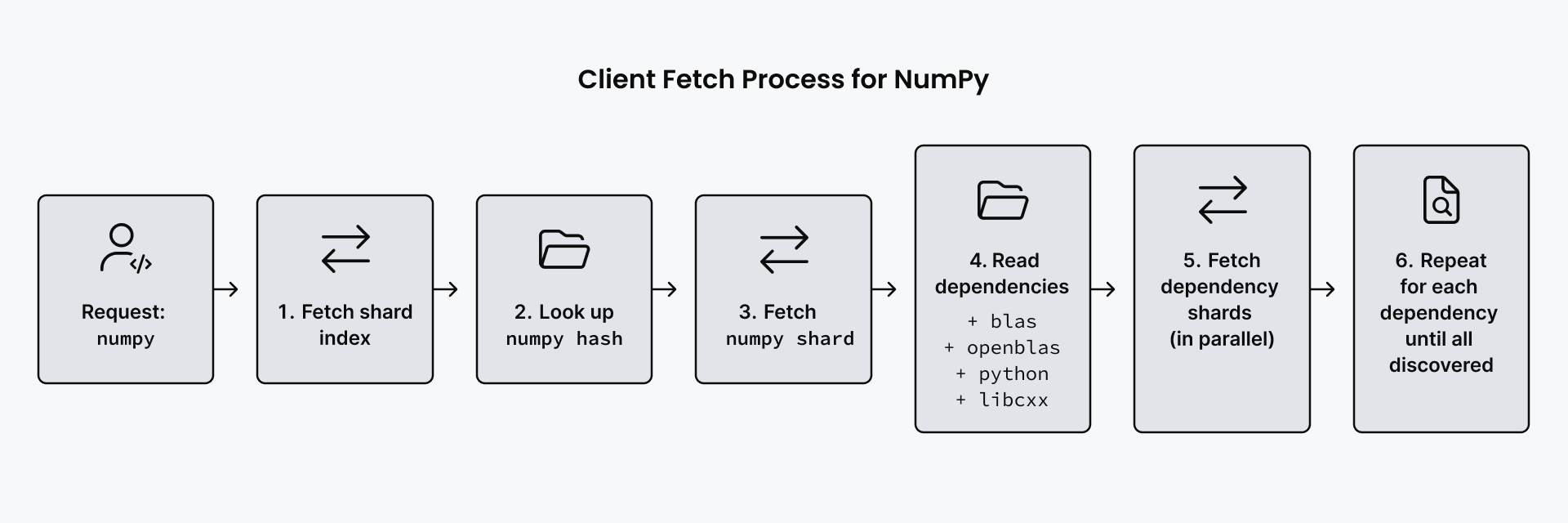
La mise en œuvre fonctionne à travers un système en deux parties décrit dans le diagramme ci-dessous. Tout d’abord, un fichier manifeste léger, appelé index de partition, répertorie tous les packages disponibles et mappe chaque nom de package à un hachage. Considérez un hachage comme une empreinte digitale unique générée à partir du contenu du fichier. Si vous modifiez ne serait-ce qu’un octet du fichier, vous obtenez un hachage complètement différent.

Ce hachage est calculé à partir du contenu du fichier de partition compressé, de sorte que chaque fichier de partition est identifié de manière unique par son hachage. Ce manifeste est petit, environ 500 Ko pour le sous-répertoire linux-64 de conda-forge qui contient plus de 12 000 noms de packages. Il n’a besoin d’être mis à jour que lorsque des packages sont ajoutés ou supprimés. Deuxièmement, les fichiers de partition individuels contiennent les métadonnées réelles du package. Chaque fragment contient toutes les versions d’un seul nom de package, stockées sous forme de fichier compressé distinct.
L’idée clé est le stockage adressé par contenu. Chaque fichier de partition porte le nom du hachage de son contenu compressé. Si un package n’a pas changé, son contenu de partition reste le même, donc le hachage reste le même. Cela signifie que les clients peuvent mettre en cache les fragments indéfiniment sans rechercher les mises à jour. Aucun aller-retour vers le serveur n’est requis.
Lorsque vous demandez un package, le client effectue une traversée des dépendances reflétant le diagramme ci-dessous. Il récupère l’index de partition pour rechercher le nom du package et trouver son hachage correspondant, puis utilise ce hachage pour récupérer le fichier de partition spécifique. Le fragment contient des informations de dépendance, que le client utilise pour récupérer ensuite le prochain lot de fragments supplémentaires en parallèle.

Ce processus découvre uniquement les packages éventuellement nécessaires, généralement 35 à 678 packages pour les installations courantes, plutôt que de télécharger les métadonnées de tous les packages sur toutes les plates-formes du canal. Votre client conda télécharge uniquement les métadonnées dont il a besoin pour mettre à jour votre environnement.
Mesurer l’impact
L’écosystème conda a récemment implémenté des repodata fragmentés via CEP-16, une spécification communautaire développée en collaboration par les ingénieurs de prefix.dev, Anaconda et Quansight, un canal géré par des bénévoles qui héberge plus de 31 000 packages créés par la communauté indépendamment de toute entreprise. Cela en fait un terrain d’essai idéal pour des changements d’infrastructure qui profitent à l’écosystème dans son ensemble.
Les critères racontent une histoire claire.
Pour la récupération et l’analyse des métadonnées, les repodata fragmentées offrent une vitesse améliorée de 10 fois. Les opérations de cache froid qui prenaient auparavant 18 secondes se terminent en moins de 2 secondes. Le transfert réseau est divisé par 35. L’installation de Python nécessitait auparavant le téléchargement de plus de 47 Mo de métadonnées. Avec le partitionnement, vous téléchargez environ 2 Mo. L’utilisation maximale de la mémoire est divisée par 15 à 17, passant de plus de 1,4 Go à moins de 100 Mo.
Le comportement du cache change également. Avec les index monolithiques, toute mise à jour de canal invalide l’intégralité de votre cache. Avec le partitionnement, seule la partition du package concerné doit être actualisée. Cela signifie plus d’accès au cache et moins de téléchargements redondants au fil du temps.
Compromis de conception
Le partage introduit de la complexité. Les clients ont besoin de logique pour déterminer les fragments à récupérer. Les serveurs ont besoin d’une infrastructure pour générer et servir des milliers de petits fichiers au lieu d’un seul gros fichier. L’invalidation du cache devient plus granulaire mais aussi plus complexe.
La spécification CEP-16 aborde ces compromis avec une approche à deux niveaux. Un fichier manifeste léger répertorie tous les fragments disponibles et leurs sommes de contrôle. Les clients téléchargent d’abord ce manifeste, puis récupèrent uniquement les fragments des packages qu’ils doivent résoudre. La mise en cache HTTP gère le reste. Les fragments inchangés renvoient 304 réponses. Les fragments modifiés sont téléchargés à nouveau.
Cette conception simplifie la logique client tout en déplaçant la complexité vers le serveur, où elle peut être optimisée une fois et profiter à tous les utilisateurs. Pour conda-forge, l’équipe d’infrastructure d’Anaconda a géré ce travail côté serveur, ce qui signifie que plus de 31 000 responsables de packages et des millions d’utilisateurs en bénéficient sans modifier leurs flux de travail.
Applications plus larges
Le modèle s’étend au-delà de conda-forge. Tout gestionnaire de packages utilisant des index monolithiques est confronté à des défis de mise à l’échelle similaires. L’idée clé consiste à séparer la couche de découverte (quels packages existent) de la couche de résolution (de quelles métadonnées ai-je besoin pour mes dépendances spécifiques).
Différents écosystèmes ont adopté différentes approches face à ce problème. Certains utilisent des API par package où les métadonnées de chaque package sont récupérées séparément – cela évite de tout télécharger, mais peut entraîner de nombreuses requêtes HTTP séquentielles lors de la résolution des dépendances. Les repodata fragmentés offrent un juste milieu : vous récupérez uniquement les packages dont vous avez besoin, mais vous pouvez récupérer par lots les dépendances associées en parallèle, réduisant ainsi à la fois la bande passante et la surcharge des requêtes.
Pour les équipes qui créent des référentiels de packages internes, la leçon est architecturale : concevez votre couche de métadonnées pour qu’elle évolue indépendamment du nombre de packages. Que vous choisissiez des API par package, des index fragmentés ou une autre approche, l’alternative consiste à voir vos temps de construction augmenter avec chaque package que vous ajoutez.
Essayez-le vous-même
Pixi prend déjà en charge les repodata fragmentés avec le canal conda-forge, qui est inclus par défaut. Utilisez simplement Pixi normalement et vous en bénéficiez déjà.
Si vous utilisez conda avec conda-forge, vous pouvez activer la prise en charge des repodata fragmentés :
conda install --name base 'conda-libmamba-solver>=25.11.0'
conda config --set plugins.use_sharded_repodata trueLa fonctionnalité est en version bêta pour conda et les responsables de conda collectent des commentaires avant la disponibilité générale. Si vous rencontrez des problèmes, le référentiel conda-libmamba-solver sur GitHub est l’endroit idéal pour les signaler.
Pour tous les autres, la solution est plus simple : lorsque vos outils semblent lents, examinez la couche de métadonnées. Les colis eux-mêmes ne constituent peut-être pas le goulot d’étranglement. L’indice l’est souvent.
Le propriétaire de Towards Data Science, Insight Partners, investit également dans Anaconda. En conséquence, Anaconda est privilégiée en tant que contributeur.


