
Pourquoi la sophistication de votre invite est presque parfaitement corrélée à la sophistication de la réponse, comme l’ont découvert les recherches d’Anthropic
l’idée a circulé dans le domaine de l’IA selon laquelle l’ingénierie des invites est morte, ou du moins obsolète. Ceci, d’une part parce que les modèles de langage pur sont devenus plus flexibles et plus robustes, tolérant mieux l’ambiguïté, et d’autre part parce que les modèles de raisonnement peuvent contourner des invites erronées et ainsi mieux comprendre l’utilisateur. Quelle que soit la raison exacte, l’ère des « phrases magiques » qui fonctionnaient comme des incantations et des formulations hyper-spécifiques semble s’estomper. Dans ce sens étroit, l’ingénierie rapide est considérée comme un sac à astuces (qui a été analysé scientifiquement dans des articles comme celui-ci par DeepMind, qui a dévoilé des graines d’invite suprêmes pour les modèles de langage à l’époque où GPT-4 a été rendu disponible) est vraiment en quelque sorte en train de mourir.
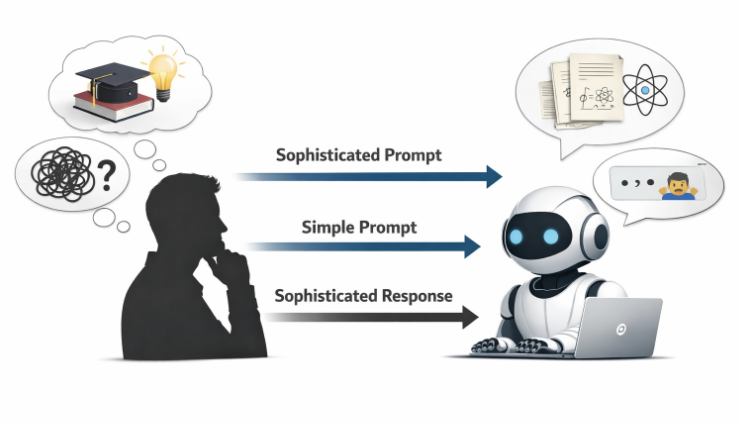
Mais Anthropic a désormais mis les chiffres derrière quelque chose de plus subtil et de plus important. Ils ont constaté que même si la formulation exacte d’une invite importe moins qu’auparavant, la « sophistication » derrière l’invite compte énormément. En fait, cela correspond presque parfaitement à la sophistication de la réponse du modèle.
Il ne s’agit pas d’une métaphore ou d’un « slogan » de motivation, mais plutôt d’un résultat empirique obtenu à partir des données collectées par Anthropic à partir de sa base d’utilisation. Poursuivez votre lecture pour en savoir plus, car tout cela est très excitant, au-delà des simples implications sur la façon dont nous utilisons les systèmes d’IA basés sur LLM.
Indice économique anthropique : rapport de janvier 2026
Dans le Indice économique anthropique : rapport de janvier 2026les auteurs principaux Ruth Appel, Maxim Massenkoff et Peter McCrory analysent comment les gens utilisent réellement Claude dans différentes régions et contextes. Pour commencer, ce qui est probablement le résultat le plus frappant, ils ont observé une forte relation quantitative entre le niveau d’éducation requis pour comprendre l’invite d’un utilisateur et le niveau d’éducation requis pour comprendre la réponse de Claude. Selon les pays, le coefficient de corrélation est r = 0,925 (p < 0,001, N = 117). Dans tous les États américains, il est r = 0,928 (p < 0,001, N = 50).
Cela signifie que plus vous êtes instruit et plus les invites que vous pouvez saisir sont claires, meilleures sont les réponses. En termes simples, la façon dont les humains incitent est la façon dont Claude répond.
Et tu sais quoi ? J’ai en quelque sorte constaté cela qualitativement moi-même en comparant la façon dont moi et d’autres collègues titulaires d’un doctorat interagissons avec les systèmes d’IA par rapport à la façon dont les utilisateurs sous-instruits le font.
Des « hacks rapides » aux « échafaudages cognitifs »
Les premières conversations sur l’ingénierie rapide se sont concentrées sur les techniques au niveau de la surface : ajouter « réfléchissons étape par étape », spécifier un rôle (« agir en tant que data scientist senior ») ou ordonner soigneusement les instructions (plus d’exemples de ceci dans l’article DeepMind que j’ai lié dans la section d’introduction). Ces techniques étaient utiles lorsque les modèles étaient fragiles et dérailleaient facilement – ce qui, soit dit en passant, était utilisé pour écraser leurs règles de sécurité, ce qui est beaucoup plus difficile à réaliser aujourd’hui.
Mais à mesure que les modèles s’amélioraient, bon nombre de ces astuces sont devenues facultatives. Le même modèle pourrait souvent parvenir à une réponse raisonnable, même sans eux.
Les découvertes d’Anthropic clarifient pourquoi cela a finalement conduit à la perception que l’ingénierie rapide était obsolète. Il s’avère que les aspects « mécaniques » de l’incitation – syntaxe, mots magiques, rituels de formatage – importent en effet moins. Ce qui n’a pas disparu, c’est l’importance de ce qu’ils appellent « l’échafaudage cognitif » : dans quelle mesure l’utilisateur comprend le problème, avec quelle précision il le formule et s’il sait à quoi ressemble une bonne réponse – en d’autres termes, la pensée critique permet de distinguer les bonnes réponses des hallucinations inutiles.
L’étude opérationnalise cette idée en utilisant l’éducation comme indicateur quantitatif de la sophistication. Les chercheurs estiment le nombre d’années d’éducation nécessaires pour comprendre à la fois les invites et les réponses, trouvant une corrélation proche de un pour un ! Cela suggère que Claude n’ « améliore » ou ne « dégrade » pas indépendamment le niveau intellectuel de l’interaction. Au lieu de cela, il reflète de manière remarquablement fidèle les entrées de l’utilisateur. C’est certainement une bonne chose lorsque vous savez ce que vous demandez, mais cela rend le système d’IA sous-performant lorsque vous n’en savez pas grand-chose vous-même ou lorsque vous tapez peut-être une demande ou une question trop rapidement et sans y prêter attention.
Si un utilisateur fournit une invite superficielle et sous-spécifiée, Claude a tendance à répondre à un niveau tout aussi superficiel. Si l’invite code une connaissance approfondie du domaine, des contraintes bien pensées et des normes implicites de rigueur, Claude répond de la même manière. Et bon sang oui, j’ai certainement vu cela sur les modèles ChatGPT et Gemini, qui sont ceux que j’utilise le plus.
Pourquoi ce n’est pas anodin
À première vue, cela peut paraître évident. Bien entendu, les meilleures questions obtiennent de meilleures réponses. Mais c’est l’ampleur de la corrélation qui rend le résultat scientifiquement intéressant. Les corrélations supérieures à 0,9 sont rares dans les données sociales et comportementales, en particulier dans des unités hétérogènes comme les pays ou les États américains. Ainsi, ce que les travaux ont découvert n’est pas une tendance faible mais une relation tout à fait structurelle.
De manière critique, cette découverte va à l’encontre de l’idée commune selon laquelle l’IA pourrait fonctionner comme un égaliseur, en permettant à chacun de récupérer des informations de niveau similaire, quels que soient sa langue, son niveau d’éducation et sa connaissance d’un sujet. Il existe un espoir largement répandu que les modèles avancés « élèveront » les utilisateurs peu qualifiés en fournissant automatiquement des résultats de niveau expert, quelle que soit la qualité des entrées. Les résultats obtenus par Anthropic suggèrent que ce n’est pas du tout le cas, et une réalité bien plus conditionnelle. Bien que Claude (et cela s’applique très probablement à tous les modèles d’IA conversationnelle) puisse potentiellement produire des réponses très sophistiquées, il a tendance à le faire uniquement lorsque l’utilisateur fournit une invite qui le justifie.
Le comportement du modèle n’est pas fixe ; il est conçu
Bien que pour moi cette partie du rapport manque de données à l’appui et, d’après mon expérience personnelle, j’aurais tendance à ne pas être d’accord, elle suggère que cet effet « miroir » n’est pas une propriété inhérente à tous les modèles de langage et que la façon dont un modèle répond dépend fortement de la façon dont il est formé, affiné et instruit. Même si, comme je l’ai dit, je ne suis pas d’accord, je vois que l’on pourrait imaginer une invite système qui oblige le modèle à toujours utiliser un langage simplifié, quelle que soit la saisie de l’utilisateur, ou, à l’inverse, une invite qui répond toujours dans une prose hautement technique. Mais il faudrait que cela soit conçu.
Claude semble occuper un terrain d’entente plus dynamique. Plutôt que d’imposer un registre fixe, il adapte son niveau de sophistication aux demandes de l’utilisateur. Ce choix de conception amplifie l’importance de la compétence de l’utilisateur. Le modèle est capable d’un raisonnement de niveau expert, mais il traite l’invite comme un signal indiquant la quantité de capacité à déployer.
Ce serait vraiment formidable de voir d’autres grands acteurs comme OpenAI et Google effectuer les mêmes types de tests et d’analyses sur leurs données d’utilisation.
L’IA comme multiplicateur, quantifiée
Le « cliché » selon lequel « l’IA est un égaliseur » est souvent répété sans preuve, et comme je l’ai dit plus haut, l’analyse d’Anthropic fournit exactement cela… mais négativement.
Si la sophistication des extrants évolue avec la sophistication des intrants, alors le modèle ne remplace pas l’expertise humaine (et n’égalise pas) ; cependant, il le multiplie. Et c’est positif pour les utilisateurs qui appliquent le système d’IA à leurs domaines d’expertise.
Une base faible multipliée par un outil puissant reste faible, et dans le meilleur des cas vous pouvez utiliser des consultations avec un système d’IA pour vous lancer dans un domaine, à condition d’en savoir suffisamment pour au moins distinguer les hallucinations des faits. En revanche, une base solide profite énormément, car on commence alors avec beaucoup et on obtient encore plus ; par exemple, je réfléchis très souvent avec ChatGPT ou mieux avec Gemini 3 dans AI studio sur des équations qui décrivent des phénomènes physiques, pour enfin obtenir du système des morceaux de code ou même des applications complètes pour, par exemple, adapter les données à des modèles mathématiques très complexes. Oui, j’aurais pu le faire, mais en rédigeant soigneusement mes invites au système d’IA, il pourrait faire le travail en un temps littéralement inférieur à celui que j’aurais eu.
Tout ce cadrage pourrait aider à réconcilier deux récits apparemment contradictoires sur l’IA. D’une part, les modèles sont indéniablement impressionnants et peuvent surpasser les humains dans de nombreuses tâches restreintes. En revanche, ils déçoivent souvent lorsqu’ils sont utilisés naïvement. La différence ne réside pas principalement dans la formulation de l’invite, mais dans la compréhension par l’utilisateur du domaine, de la structure du problème et des critères de réussite.
Implications pour l’éducation et le travail
L’une des conséquences est que les investissements dans le capital humain sont toujours importants, et beaucoup. À mesure que les modèles reflètent mieux la sophistication des utilisateurs, les disparités en matière d’expertise pourraient devenir plus visibles plutôt que réduites, comme le propose le discours sur la « péréquation ». Ceux qui peuvent formuler des invites précises et bien fondées extrairont bien plus de valeur du même modèle sous-jacent que ceux qui ne le peuvent pas.
Cela recadre également ce que « l’ingénierie rapide » devrait signifier à l’avenir. Il s’agit moins d’acquérir une nouvelle compétence technique que de cultiver des compétences traditionnelles : connaissance du domaine, pensée critique, décomposition des problèmes. Savoir quoi demander et comment reconnaître une bonne réponse s’avère être la véritable interface. Tout cela est probablement évident pour nous, lecteurs de Vers la science des donnéesmais nous sommes ici pour apprendre et ce qu’Anthropic a découvert de manière quantitative rend tout cela beaucoup plus convaincant.
Notamment, pour conclure, les données d’Anthropic font valoir leurs arguments avec une clarté inhabituelle. Et encore une fois, nous devrions appeler tous les grands acteurs comme OpenAI, Google, Meta, etc. à effectuer des analyses similaires sur leurs données d’utilisation et leur demander de présenter les résultats au public, tout comme l’a fait Anthropic.
Et tout comme nous luttons depuis longtemps pour un accès gratuit et généralisé aux systèmes d’IA conversationnelle, des directives claires pour supprimer la désinformation et les utilisations inappropriées intentionnelles, des moyens d’éliminer idéalement ou au moins de signaler les hallucinations, et bien plus encore, nous pouvons désormais ajouter des appels pour parvenir à une véritable égalisation.
Références et lectures connexes
Pour tout savoir sur le rapport d’Anthropic (qui aborde également bien d’autres points intéressants et fournit tous les détails sur les données analysées) : https://www.anthropic.com/research/anthropic-économique-index-january-2026-report
Et vous pouvez également trouver intéressant le « New Future of Work Report 2025 » de Microsoft, avec lequel l’étude d’Anthropic fait quelques comparaisons, disponible ici : https://www.microsoft.com/en-us/research/project/the-new-future-of-work/
Mon article précédent « Deux nouveaux articles de DeepMind illustrent comment l’intelligence artificielle peut aider l’intelligence humaine » : https://pub.towardsai.net/two-new-papers-by-deepmind-exemplify-how-artificial-intelligence-can-help-human-intelligence-ae5143f07d49
Mon article précédent « Le nouveau travail de DeepMind dévoile des graines d’invite suprêmes pour les modèles de langage » : https://medium.com/data-science/new-deepmind-work-unveils-supreme-prompt-seeds-for-lingual-models-e95fb7f4903c


