
Pourquoi je ne fais pas confiance aux LLM pour décider quand le temps change
J’ai un problème simple : ils vous montrent les prévisions, mais ils ne vous disent pas quand elles ont réellement changé.
Cela peut paraître anodin. Ce n’est pas le cas.
Les systèmes modernes de prévision numérique du temps (PNT), comme l’IFS du CEPMMT, produisent des prévisions remarquablement précises à une résolution d’environ 9 km, mises à jour toutes les quelques heures. Les données sont déjà très bonnes.
Le problème ne vient pas des prévisions.
Le problème est attention: savoir quand un changement dans ces données est réellement significatif.
Je n’ai pas appris cela du génie logiciel. Je l’ai appris des années plus tôt, en étudiant la théorie du chaos à l’Instituto Balseiro. C’est là, en travaillant à travers des systèmes dynamiques, que j’ai rencontré pour la première fois une idée un peu troublante :
Un système peut être complètement déterministe tout en étant pratiquement imprévisible.
Cette idée m’est restée. Et des années plus tard, lorsque j’ai commencé à construire des systèmes d’IA, j’ai réalisé que beaucoup d’entre eux l’ignoraient.
Le problème des deltas « basés sur les vibrations »
Lorsque j’ai commencé à voir comment les développeurs construisaient des agents météorologiques, j’ai remarqué une tendance :
- Récupérer les données de prévision
- Introduisez-le dans un LLM
- Demandez : « Le temps a-t-il changé de manière significative ? »
À première vue, cela semble raisonnable. D’un point de vue physique, cela pose problème – du moins pour les problèmes où la limite de décision est déjà bien définie – car cela remplace un seuil bien défini par une interprétation probabiliste.
Dans un système chaotique, la signification n’est pas un jugement linguistique : c’est un seuil défini en fonction de variables telles que la température, les précipitations ou la vitesse du vent. Cela dépend de l’ampleur, du contexte et des horizons temporels.
Un LLM est un processus stochastique. Il est très efficace pour générer du langage, mais il n’est pas conçu pour imposer des limites déterministes aux systèmes physiques.
Lorsque vous demandez à un LLM si une prévision a « changé de manière significative », vous demandez à un modèle probabiliste de se rapprocher d’une règle déterministe que vous auriez pu définir explicitement. Cela introduit de la variabilité exactement là où vous souhaitez de la cohérence.
Les modes de défaillance sont subtils :
- Tendances déduites de la formulation plutôt que des données
- Décisions incohérentes sur des entrées similaires
- Résultats qui ne peuvent pas être testés ou reproduits
Dans de nombreuses applications, cela pourrait être acceptable. Dans l’agriculture, l’énergie et la logistique – où une baisse de 3°C constitue une transition de phase pour une culture, une hausse non linéaire de la demande énergétique ou une perturbation opérationnelle – ce n’est pas le cas. Ces décisions doivent être stables et explicables.
Ce qui m’a amené à une règle simple :
Si vous pouvez écrire une instruction assert pour cela, vous ne devriez probablement pas utiliser d’invite.
Mon chemin vers ce problème
Ma carrière ressemble moins à une ligne droite qu’à une trajectoire dans l’espace des phases. Docteur Marie Curie en dynamique climatique, cinq ans à diriger la R&D à l’Institut national de météorologie de l’Uruguay — prévention des incendies de forêt, prévisions saisonnières, adaptation climatique — puis passage au ML de production chez Microsoft et Mercado Libre.
Cet arc m’a apporté quelque chose de spécifique : j’ai déjà compris la physique des données, les horizons de compétences des modèles et ce que signifie réellement « changement significatif » dans un système physique. Pas comme une abstraction logicielle – comme un delta mesurable sur une variable avec des limites d’incertitude connues.
Lorsque j’ai commencé à construire des systèmes d’IA, l’instinct a été immédiat : il s’agit d’un problème de seuil. Les seuils appartiennent au code et non aux invites.
Skygent est une expression de cette perspective : un agent conçu non pas pour afficher des prévisions, mais pour y détecter des changements significatifs.
Le système fonctionne en continu sur des données de prévision réelles pour des événements définis par l’utilisateur, évaluant les changements toutes les quelques heures et déclenchant des alertes uniquement lorsque des conditions prédéfinies sont remplies. En pratique, la plupart des cycles d’évaluation ne donnent lieu à aucune alerte : seule une petite fraction des changements dépasse le seuil de signification. C’est le point : un signal, pas du bruit.
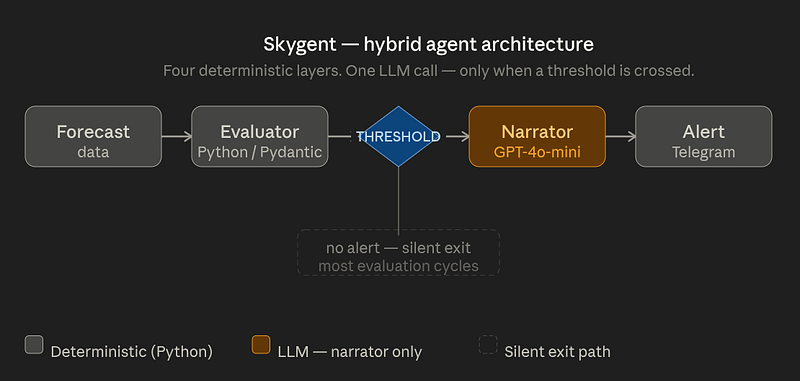
L’architecture
Skygent suit une séparation nette sur cinq couches :

Une seule couche appelle le LLM.
Le gardien déterministe
Au cœur se trouve un évaluateur Python. Il n’interprète pas, il calcule. Il:
- Compare les instantanés de prévisions consécutifs validés par Pydantic
- Évalue les deltas par rapport à des seuils configurables
- Intègre le contexte : type d’événement, sensibilité variable
- Tient compte de l’horizon de prévision en utilisant les limites de compétence établies en matière de prévision numérique du temps : un changement dans une prévision sur 24 heures n’a pas la même fiabilité qu’un changement dans une prévision sur 10 jours.
C’est ici que les décisions sont prises. Chaque alerte a un chemin traçable : quelle variable a changé, de combien, quel seuil a été franchi. Dans un environnement d’entreprise ou gouvernemental, être capable d’expliquer pourquoi une alerte déclenchée – sans dire « le modèle en avait envie » – n’est pas facultative.
Le déclencheur
Une alerte se déclenche uniquement si un seuil est franchi. Si le delta ne franchit pas la frontière, rien ne se passe. Il s’agit d’une condition binaire et testable – et non d’un jugement.
Le Narrateur
Ce n’est qu’une fois la décision prise que le LLM entre dans le pipeline. Son rôle est strictement limité : prendre des données JSON structurées, les traduire en langage naturel.
# Structured payload sent to GPT-4o-mini
{
"event_name": "Ana's Wedding",
"variable": "precipitation_probability_max",
"from_value": 10.0,
"to_value": 50.0,
"delta": 40.0,
"horizon_days": 5.2,
"confidence": "medium"
}Sortir:
« La probabilité de pluie est passée de 10 % à 50 % pour la fenêtre de votre événement. La confiance est moyenne en raison de l’horizon de prévision de 5 jours. »
Le LLM ne décide rien. C’est expliquer.
Pourquoi cette architecture est testable
Il est pratiquement impossible d’atteindre une couverture de test de 100 % sur un agent LLM pur : vous ne pouvez pas écrire d’assertions déterministes sur des sorties probabilistes.
L’approche hybride change cela. La logique de décision est du pur Python avec des entrées validées par Pydantic : 204 tests unitaires, zéro dépendance LLM dans la suite de tests. Le LLM ne gère que le ton narratif – la seule chose qui bénéficie véritablement de la génération de langage naturel.
Il ne s’agit pas seulement d’une simple commodité de test. Cela signifie que chaque décision
Les marques du système peuvent être expliquées, reproduites et vérifiées indépendamment du LLM.
Invocation LLM basée sur les événements
Un agent naïf appelle le LLM à chaque cycle d’interrogation. Celui-ci ne le fait pas.
Skygent évalue toutes les 6 heures. Il n’appelle le modèle que lorsqu’un seuil est franchi – environ une à deux fois par semaine et par événement surveillé, contre environ 28 appels pour un agent de sondage naïf.
Au prix gpt-4o-mini (~ 0,0001 $ par récit), le coût est négligeable. Plus important encore, le coût est proportionnel aux informations réelles : vous payez pour un appel LLM uniquement lorsque quelque chose qui mérite d’être communiqué s’est produit.
Un exemple concret
Instantané précédent : Probabilité de pluie 10%, Température max 22°C, Vent 15 km/h
Instantané actuel : Probabilité de pluie 50%, Température max 21,4°C, Vent 18 km/h
Seuil: Alerte si probabilité de pluie Δ > 20pp
Fréquence d’évaluation : Toutes les 6 heures
Résultat: Alerte déclenchée → GPT-4o-mini génère un récit → Livraison de télégramme

Quand ce modèle se brise
Cette approche ne s’applique pas partout. Il tombe en panne quand :
- Les entrées sont non structurées ou ambiguës
- Les limites de décision ne peuvent pas être codifiées sous forme de seuils
- Le raisonnement est ouvert
Dans ces cas, les architectures LLM-first – ReAct, Plan-and-Execute – ont plus de sens.
Une mise en garde honnête : les seuils de Skygent sont des valeurs par défaut configurables – des points de départ raisonnables éclairés par la pratique météorologique, mais non calibrés par rapport aux erreurs de prévision historiques pour des cas d’utilisation spécifiques. L’étalonnage par rapport aux résultats réels constitue la prochaine étape naturelle de tout déploiement vertical. Le modèle est solide ; les paramètres sont un point de départ.
Clôture
La décision la plus importante que j’ai prise en construisant ce système a été de ne pas choisir un modèle ou un cadre.
Il s’agissait de décider où pas utiliser un LLM.
Il y a actuellement une tendance à déléguer de plus en plus aux modèles de langage – pour les laisser comprendre les choses. Mais certains problèmes ont déjà une structure. Certaines décisions ont déjà des limites.
Lorsqu’ils le font, se rapprocher d’eux avec le langage n’est pas une bonne idée. Il est préférable de les coder explicitement.
En pratique, cela se résume souvent à une distinction simple : utiliser les LLM pour expliquer des décisions, et non pour remplacer des décisions bien définies.
La mise en œuvre complète – évaluateur de signification, pipeline LangGraph, bot Telegram – est disponible sur : github.com/ferariz/skygent
Fernando Arizmendi construit des systèmes d’IA de production à l’intersection d’une méthode scientifique rigoureuse et d’une ingénierie d’IA appliquée. Il est physicien (B.Sc. et M.Sc.) de l’Instituto Balseiro, ancien boursier Marie Curie (doctorat sur la dynamique climatique et les systèmes complexes) et a précédemment dirigé la R&D à l’institut national de météorologie de l’Uruguay.
Toutes les images de l’auteur. Diagramme de pipeline généré avec Claude (Anthropic).
You may also like


