
Machine Learning à grande échelle : gérer plusieurs modèles en production
vous-même, comment les vrais produits d’apprentissage automatique fonctionnent réellement dans les grandes entreprises ou départements technologiques ? Si oui, cet article est pour vous 🙂
Avant de parler d’évolutivité, n’hésitez pas à lire mon premier article sur les bases du machine learning en production.
Dans ce dernier article, je vous disais que j’ai passé 10 ans à travailler comme ingénieur en IA dans l’industrie. Au début de ma carrière, j’ai appris qu’un modèle dans un cahier n’est qu’une hypothèse mathématique. Cela ne devient utile que lorsque sa sortie atteint un utilisateur, un produit ou génère de l’argent.
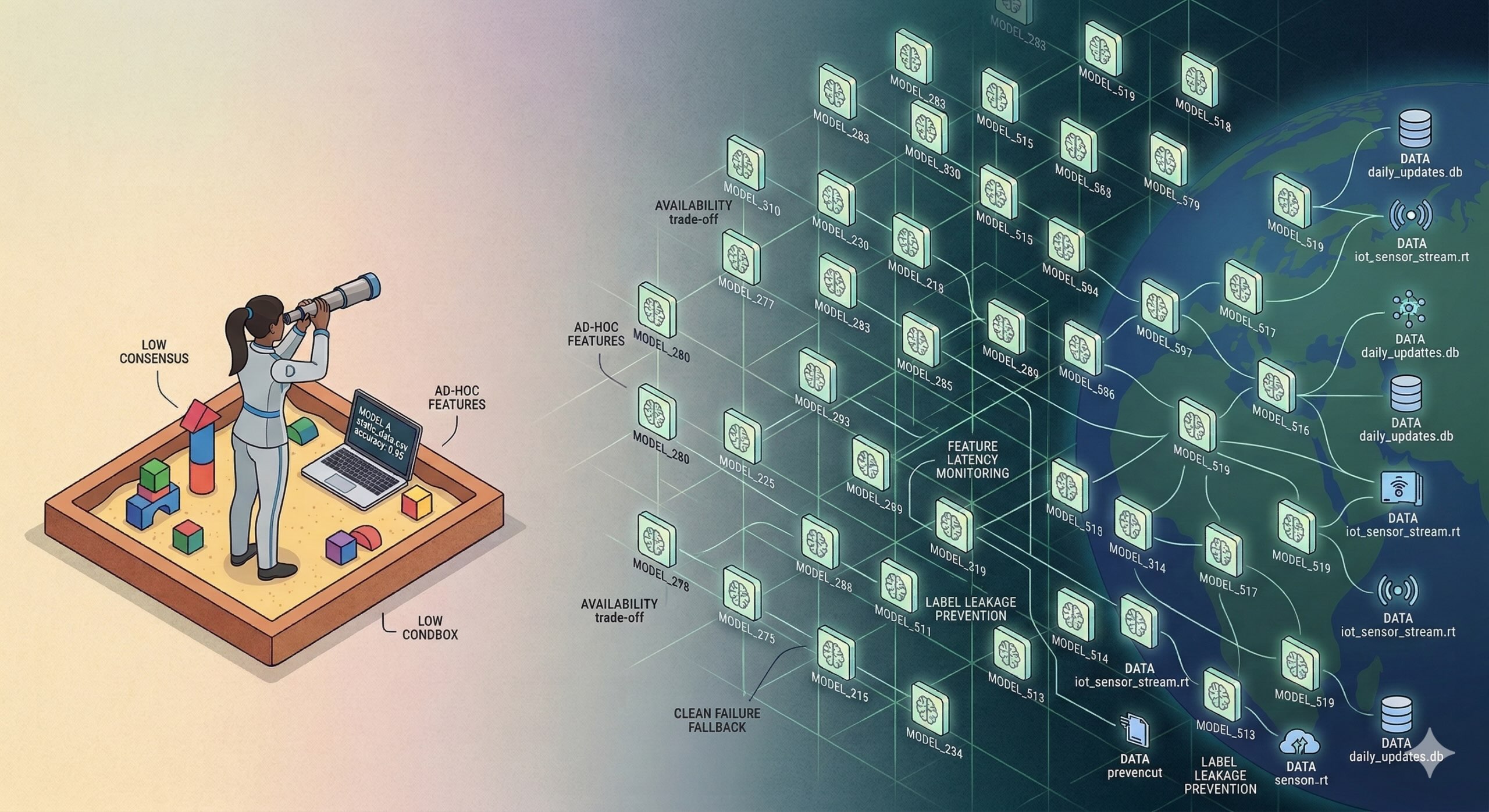
Je vous ai déjà montré à quoi ressemble le « Machine Learning en production » pour un seul projet. Mais aujourd’hui, la conversation porte sur Échelle: gérer des dizaines, voire des centaines, de projets ML simultanément. Ces dernières années, nous sommes passés du L’ère du bac à sable dans le L’ère des infrastructures. « Déployer un modèle » est désormais une compétence non négociable ; le véritable défi consiste à garantir qu’un vaste portefeuille de modèles fonctionne de manière fiable et sûre.
1. Quitter le bac à sable : la stratégie de disponibilité
Pour comprendre le ML à grande échelle, vous devez d’abord laisser derrière vous l’état d’esprit « bac à sable ». Dans un bac à sable, vous disposez de données statiques et d’un modèle. S’il dérive, vous le voyez, vous l’arrêtez, vous le réparez.
Mais une fois que vous passez en mode Scale, vous ne gérez plus un modèle, vous gérez un portefeuille. C’est là que le théorème CAP (cohérence, disponibilité et tolérance de partition) devient votre réalité. Dans une configuration à modèle unique, vous pouvez essayer d’équilibrer les compromis, mais à grande échelle, il est impossible d’être parfait sur les 3 métriques. Vous devez choisir vos batailles et, le plus souvent, la disponibilité devient la priorité absolue.
Pourquoi? Parce que quand vous avez 100 modèles en marche, quelque chose ne va pas toujours rupture. Si vous arrêtiez le service à chaque fois qu’un modèle dérive, votre produit serait hors ligne 50 % du temps.
Puisque nous ne pouvons pas arrêter le service, nous concevons des modèles qui échouent « proprement ». Prenons l’exemple d’un système de recommandation : si son modèle obtient des données corrompues, il ne devrait pas planter ni afficher une « erreur 404 ». Il devrait revenir à un paramètre par défaut sûr (comme afficher les éléments « Top 10 les plus populaires »). L’utilisateur reste satisfait, le système reste disponible, même si le résultat n’est pas optimal. Mais pour ce faire, il faut savoir quand pour déclencher ce repli. Et cela nous amène à notre plus grand défi à grande échelle… « La surveillance ».
2. Le défi de la surveillance et pourquoi les métriques traditionnelles meurent à grande échelle
En disant qu’à grande échelle, il est important que notre système échoue « proprement », vous pourriez penser que c’est facile et qu’il nous suffit de vérifier ou de surveiller l’exactitude. Mais à grande échelle, la « précision » ne suffit pas et je vais vous expliquer exactement pourquoi :
- Le manque de consensus humain : En Computer Vision, par exemple, la surveillance est facile car les humains sont d’accord sur la vérité (c’est un chien ou ce n’est pas le cas). Mais dans un système de recommandation ou un modèle de classement des annonces, il n’y a pas de « Gold Standard ». Si un utilisateur ne clique pas, le modèle est-il mauvais ? Ou l’utilisateur n’est-il tout simplement pas d’humeur ?
- Le piège de l’ingénierie des fonctionnalités : Parce que nous ne pouvons pas facilement mesurer la « vérité » à l’aide d’une simple mesure, nous surcompensons. Nous ajoutons des centaines de fonctionnalités au modèle, en espérant que « davantage de données » résoudront l’incertitude.
- Le plafond théorique : Nous nous battons pour des gains de précision de 0,1 % sans savoir si les données sont tout simplement trop bruitées pour en donner davantage. Nous courons après un « plafond » que nous ne pouvons pas voir.
Relions donc tout cela pour comprendre où nous allons et pourquoi c’est important : parce que la surveillance de la « vérité » est presque impossible à grande échelle (zones mortes), nous ne pouvons pas compter sur de simples alertes pour nous dire d’arrêter. C’est exactement pourquoi nous accordons la priorité Disponibilité et Solutions de repli sûresnous supposons que le modèle pourrait échouer sans que les métriques nous le disent, nous construisons donc un système qui peut survivre à cet échec « flou ».
3. Qu’en est-il du mur d’ingénierie
Maintenant que nous avons discuté des défis liés à la stratégie et au suivi, nous ne sommes pas encore prêts à passer à l’échelle, car nous n’avons pas encore abordé l’aspect infrastructurel. La mise à l’échelle nécessite autant de compétences en ingénierie que de compétences en science des données.
Nous ne pouvons pas parler d’évolutivité si nous ne disposons pas d’une infrastructure solide et sécurisée. Parce que les modèles sont complexes, et parce que Disponibilité est notre priorité numéro un, nous devons réfléchir sérieusement à l’architecture que nous mettons en place.
À ce stade, mon honnête conseil est de s’entourer d’une équipe ou de personnes habituées à construire de grandes infrastructures. Vous n’avez pas nécessairement besoin d’un cluster massif ou d’un superordinateur, mais vous devez penser à ces trois bases d’exécution :
- Cloud ou appareil : Un serveur vous donne de l’énergie et est facile à surveiller, mais il coûte cher. Votre choix dépend entièrement du coût par rapport au contrôle.
- Le matériel : Vous ne pouvez tout simplement pas placer tous les modèles sur un GPU ; tu ferais faillite. Vous avez besoin d’une stratégie à plusieurs niveaux : exécutez vos modèles simples de « secours » sur des processeurs bon marché et réservez les GPU coûteux aux modèles lourds « générateurs d’argent ».
- Optimisation: À grande échelle, un décalage d’une seconde dans votre mécanisme de secours est un échec. Vous n’écrivez plus simplement Python ; vous devez apprendre à compiler et à optimiser votre code pour des puces spécifiques afin que le commutateur « Fail Cleanly » se produise en millisecondes.
4. Faites attention aux fuites d’étiquettes
Vous avez donc anticipé les pannes, travaillé sur la disponibilité, réglé la surveillance et construit l’infrastructure. Vous pensez probablement que vous êtes enfin prêt à maîtriser l’évolutivité. En fait, pas encore. Il existe un problème que vous ne pouvez tout simplement pas anticiper si vous n’avez jamais travaillé dans un environnement réel.
Même si votre ingénierie est parfaite, les fuites d’étiquettes peuvent ruiner votre stratégie et vos systèmes qui exécutent plusieurs modèles.
Dans un seul projet, vous pourriez détecter des fuites dans un bloc-notes. Mais à grande échelle, où les données proviennent de 50 pipelines différents, les fuites deviennent presque invisibles.
L’exemple de désabonnement : Imaginez que vous prédisez quels utilisateurs annuleront leur abonnement. Vos données d’entraînement ont une fonctionnalité appelée Last_Login_Date. Le modèle semble parfait avec un score F1 de 99%.
Mais voici ce qui s’est réellement passé : l’équipe de la base de données a mis en place un déclencheur qui « efface » le champ de date de connexion au moment où un utilisateur clique sur le bouton « Annuler ». Votre modèle voit une date de connexion « Nul » et se rend compte : « Aha ! Ils ont annulé ! »
Dans le monde réel, à la milliseconde exacte, le modèle a besoin de faire une prédiction avant l’utilisateur annule, ce champ n’est pas encore nul. Le modèle examine la réponse du futur.
Ceci est un exemple de base juste pour que vous puissiez comprendre le concept. Mais croyez-moi, si vous disposez d’un système complexe avec des prédictions en temps réel (ce qui arrive souvent avec l’IoT), cela est incroyablement difficile à détecter. Vous ne pouvez l’éviter que si vous êtes conscient du problème dès le départ.
Mes conseils :
- Surveillance de la latence des fonctionnalités : Ne vous contentez pas de surveiller valeur des données, surveiller quand il a été écrit par rapport au moment où l’événement s’est réellement produit.
- Le test de la milliseconde : Demandez toujours : « Au moment exact de la prédiction, cette ligne spécifique de la base de données contient-elle déjà cette valeur ? »
Bien sûr, ce sont des questions simples, mais le meilleur moment pour évaluer cela est pendant la phase de conception, avant même d’écrire une ligne de code de production.
5. Enfin, la boucle humaine
La dernière pièce du puzzle est Responsabilité. À grande échelle, nos mesures sont floues, notre infrastructure est complexe et nos données fuient, nous avons donc besoin d’un « filet de sécurité ».
- Déploiement de l’ombre : Ceci est obligatoire pour l’échelle. Vous déployez le « Modèle B » mais ne montrez pas ses résultats aux utilisateurs. Vous le laissez fonctionner « dans l’ombre » pendant une semaine, en comparant ses prédictions à la « Vérité » qui finit par arriver. S’il est stable, alors seulement vous le promouvez en « Live ».
- Humain dans la boucle : Pour les modèles à enjeux élevés, vous avez besoin d’une petite équipe pour auditer les « valeurs par défaut sûres ». Si votre système est revenu aux « Articles les plus populaires » pendant trois jours, un humain doit demander pourquoi le modèle principal n’a pas récupéré.
Et un bref récapitulatif avant de commencer à travailler avec le ML à grande échelle :
- Comme nous ne pouvons pas être parfaits, nous choisissons de rester en ligne (disponibilité) et d’échouer en toute sécurité.
- La disponibilité est notre mesure numéro 1, car la surveillance à grande échelle est « floue » et les mesures traditionnelles ne sont pas fiables.
- Nous construisons l’infrastructure (Cloud/Hardware) pour accélérer ces pannes sûres.
- Nous faisons attention aux données « trompeuses » (fuites) qui donnent l’impression que nos mesures floues sont trop belles pour être vraies.
- Nous utilisons Shadow Deploys pour prouver que le modèle est sûr avant qu’il ne touche un client.
Et n’oubliez pas que votre balance ne vaut que par votre filet de sécurité. Ne laissez pas votre travail figurer parmi les 87 % de projets échoués.
👉 LinkedIn : Sabreiné Bendimérad
👉 Moyen: https://medium.com/@sabrine.bfinimérad1
👉 Instagram: https://tinyurl.com/datailearn
You may also like


