
Le score de santé du produit : comment j’ai réduit les incidents critiques de 35 % grâce à la surveillance unifiée et à l’automatisation n8n
Pour les entreprises SaaS (software as a service), la surveillance et la gestion de leurs données produits sont cruciales. Pour ceux qui ne comprennent pas cela, au moment où ils constatent un incident. Le mal est déjà fait. Pour les entreprises en difficulté, cela peut être fatal.
Pour éviter cela, j’ai construit un workflow n8n lié à leur base de données qui analysera les données quotidiennement, repérera s’il y a un incident. Dans ce cas, un système de journalisation et de notification commencera à enquêter dès que possible. J’ai également construit un tableau de bord afin que l’équipe puisse voir les résultats en temps réel.

Contexte
Une plateforme SaaS B2B spécialisée dans la visualisation de données et le reporting automatisé dessert environ 4 500 clients, répartis en trois segments :
- Petite entreprise
- Marché intermédiaire
- Entreprise
L’utilisation hebdomadaire du produit dépasse les 30 000 comptes actifs avec de fortes dépendances aux données en temps réel (pipelines, API, tableaux de bord, tâches en arrière-plan).
L’équipe produit travaille en étroite collaboration avec :
- Croissance (acquisition, activation, intégration)
- Revenus (tarification, ARPU, désabonnement)
- SRE/Infrastructure (fiabilité, disponibilité)
- Data Engineering (pipelines, fraîcheur des données)
- Assistance et réussite client

L’année dernière, l’entreprise a observé une augmentation du nombre d’incidents. Entre octobre et décembre, le total des incidents est passé de 250 à 450, un Augmentation de 80 %. Avec cette augmentation, plus de 45 incidents élevés et critiques ont touché des milliers d’utilisateurs. Les métriques les plus affectées étaient :
- api_error_rate
- checkout_success_rate
- net_mrr_delta
- data_freshness_lag_minutes
- taux de désabonnement

Lorsque des incidents surviennent, un l’entreprise est jugée par ses clients en fonction de la manière dont il les gère et réagit. Alors que le l’équipe produit est appréciée pour la façon dont ils ont géré cela et ont veillé à ce que cela ne se reproduise plus.
Avoir un incident une fois peut arriver, mais avoir le même incident deux fois est une faute.
Impact commercial
- Plus de volatilité dans les revenus nets récurrents
- Un notable baisse des comptes actifs sur plusieurs semaines consécutives
- Plusieurs entreprises clientes signalent et se plaignent du tableau de bord obsolète (jusqu’à 45 minutes de retard)

Au total, entre 30 000 et 60 000 utilisateurs ont été concernés. La confiance des clients dans la fiabilité des produits a également souffert. Parmi les non-renouvellements, 45 % ont souligné que c’était leur principale raison.
Pourquoi ce problème est-il critique ?
En tant que plateforme de données, l’entreprise ne peut pas se permettre d’avoir :
- données lentes ou obsolètes
- Erreur API
- Pannes de pipelines
- Synchronisations manquées ou retardées
- Tableau de bord inexact
- Désabonnements (déclassements, annulations)

En interne, les incidents se sont répartis sur plusieurs systèmes :
- Notions de suivi des produits
- Slack pour les alertes
- PostgreSQL pour le stockage
- Même sur Google Sheets pour le support client

Il n’y avait pas une seule source de vérité. L’équipe produit doit croiser et revérifier manuellement toutes les données, rechercher des tendances et les rassembler. Il s’agissait d’une enquête et d’une résolution d’énigme, leur faisant perdre tant d’heures par semaine.
Solution: Automatisation d’une alerte système d’incident avec N8N et construction d’un tableau de bord de données. Ainsi, les incidents sont détectés, suivis, résolus et compris.
Pourquoi n8n ?
Actuellement, il existe plusieurs plateformes et solutions d’automatisation. Mais tous ne correspondent pas aux besoins et aux exigences. Choisir le bon en fonction du besoin est essentiel.
Les exigences spécifiques étaient d’avoir accès à une base de données sans API nécessaire (n8n prend en charge l’Api), d’avoir des flux de travail et des nœuds visuels à comprendre par une personne non technique, des nœuds codés personnalisés, des options auto-hébergées et rentables à grande échelle. Ainsi, parmi les plateformes existantes comme Zapier, Make ou n8n, le choix s’est porté sur la dernière.
Conception du score de santé du produit

Tout d’abord, les indicateurs clés doivent être déterminés et calculés.
Score d’impact: fonction simple de gravité + delta + échelle d’utilisateurs
impact_score = (
severity_weights[severity] * 10
+ abs(delta_pct) * 0.8
+ np.log1p(affected_users)
)
impact_score = round(float(impact_score), 2)Priorité: dérivé de la gravité + impact
if severity == "critical" or impact_score > 60:
priority = "P1"
elif severity == "high" or impact_score > 40:
priority = "P2"
elif severity == "medium":
priority = "P3"
else:
priority = "P4"Score de santé du produit
def compute_product_health_score(incidents, metrics):
"""
Score = 100 - sum(penalties)
Production version handles 15+ factors
"""
# Key insight: penalties have different max weights
penalties = {
'volume': min(40, incident_rate * 13), # 40% max
'severity': calculate_severity_sum(incidents), # 25% max
'users': min(15, log(users) / log(50000) * 15), # 15% max
'trends': calculate_business_trends(metrics) # 20% max
}
score = 100 - sum(penalties.values())
if score >= 80: return score, "🟢 Stable"
elif score >= 60: return score, "🟡 Under watch"
else: return score, "🔴 At risk"Conception du système de détection automatisé avec n8n

Ce système est composé de 4 flux:
- Volet 1: récupère les mesures de revenus récentes, identifie les pics inhabituels de taux de désabonnement MRR et crée des incidents si nécessaire.

const rows = items.map(item => item.json);
if (rows.length < 8) {
return [];
}
rows.sort((a, b) => new Date(a.date) - new Date(b.date));
const values = rows.map(r => parseFloat(r.churn_mrr || 0));
const lastIndex = rows.length - 1;
const lastRow = rows[lastIndex];
const lastValue = values[lastIndex];
const window = 7;
const baselineValues = values.slice(lastIndex - window, lastIndex);
const mean = baselineValues.reduce((s, v) => s + v, 0) / baselineValues.length;
const variance = baselineValues
.map(v => Math.pow(v - mean, 2))
.reduce((s, v) => s + v, 0) / baselineValues.length;
const std = Math.sqrt(variance);
if (std === 0) {
return [];
}
const z = (lastValue - mean) / std;
const deltaPct = mean === 0 ? null : ((lastValue - mean) / mean) * 100;
if (z > 2) {
const anomaly = {
date: lastRow.date,
metric_name: 'churn_mrr',
baseline_value: mean,
actual_value: lastValue,
z_score: z,
delta_pct: deltaPct,
severity:
deltaPct !== null && deltaPct > 50 ? 'high'
: deltaPct !== null && deltaPct > 25 ? 'medium'
: 'low',
};
return [{ json: anomaly }];
}
return [];- Flux 2: surveille les mesures d’utilisation des fonctionnalités pour détecter les baisses soudaines d’adoption ou d’engagement.
Les incidents sont enregistrés avec leur gravité, leur contexte et des alertes à l’équipe produit.

- Flux 3: Pour chaque incident ouvert, collecte un contexte supplémentaire à partir de la base de données (par exemple, taux de désabonnement par pays ou plan), utilise l’IA pour générer une hypothèse claire sur la cause profonde et les prochaines étapes suggérées, envoie un rapport résumé à Slack et par courrier électronique et met à jour l’incident.

- Flux 4: Chaque matin, le workflow compile tous les incidents de la veille, crée une page Notion pour la documentation et envoie un rapport à l’équipe de direction

Nous avons déployé des nœuds de détection similaires pour 8 métriques différentes, en ajustant la direction du z-score selon que les augmentations ou les diminutions posaient problème.
Le L’agent IA reçoit un contexte supplémentaire via des requêtes SQL (churn par pays, par plan, par segment) pour générer des hypothèses de causes profondes plus précises. Et toutes ces données sont collectées et envoyées dans un e-mail quotidien.
Le workflow génère des rapports de synthèse quotidiens regroupant tous les incidents par mesure et gravité, distribués par e-mail et Slack aux parties prenantes.
Le tableau de bord
Le tableau de bord regroupe tous les signaux en un seul endroit. Un score de santé automatique du produit avec une base 0-100 est calculé avec :
- volume d’incidents
- pondération de la gravité
- statut ouvert ou résolu
- nombre d’utilisateurs concernés
- tendances commerciales (MRR)
- tendances d’utilisation (comptes actifs)
Une répartition par segments pour identifier les groupes de clients les plus concernés :

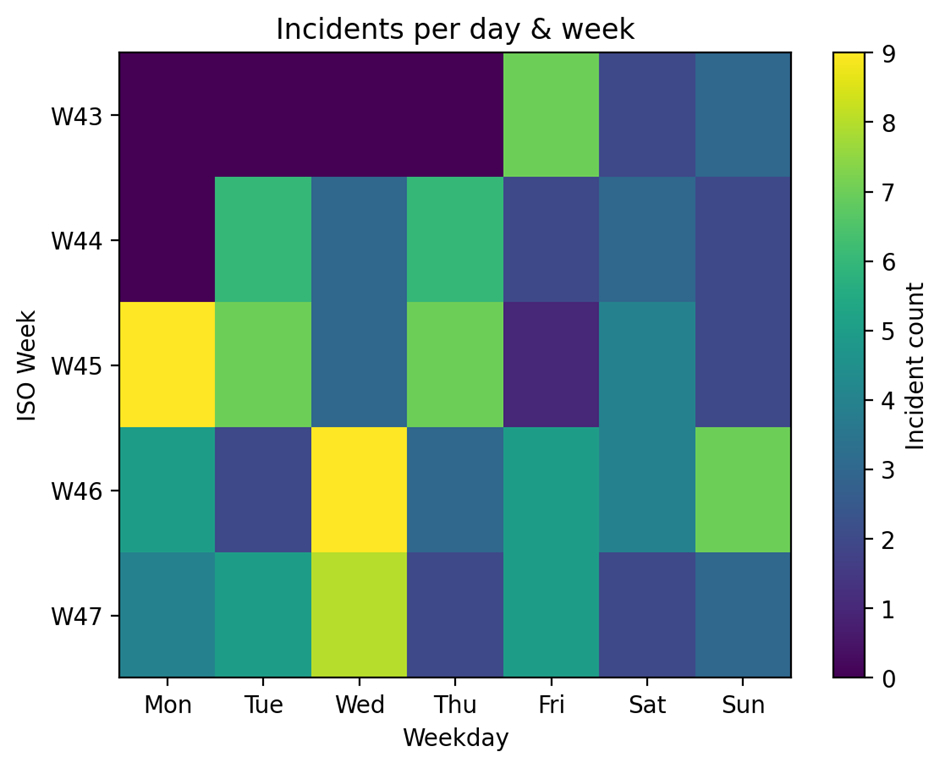
Une carte thermique hebdomadaire et des graphiques de tendances de séries chronologiques pour identifier les modèles récurrents :

Et une vue détaillée des incidents composée de :
- Contexte commercial
- Dimensions et segments
- Hypothèse de cause profonde
- Type d’incident
- Un résumé de l’IA pour accélérer la communication et les diagnostics provenant du workflow n8n

Diagnostic:
Le score de santé du produit indique le produit réel 24/100 avec le statut « à risque » avec:
- 45 Incidents élevés et critiques
- 36 incidents au cours des 7 derniers jours
- 33 385 estimations des utilisateurs concernésTendance négative du taux de désabonnement et des DAU
- Plusieurs pics dans api_error_rate et baisses dans checkout_success_rate

Plus grand impact par segments :
- Entreprise → problèmes critiques de fraîcheur des données
- Marché intermédiaire → incidents récurrents sur l’adoption des fonctionnalités
- PME → fluctuations dans l’intégration et l’activation

Impact
L’objectif de ce tableau de bord n’est pas seulement d’analyser les incidents et d’identifier des modèles, mais aussi de permettre à l’organisation de réagir plus rapidement avec une vue d’ensemble détaillée.

Nous avons remarqué un Réduction de 35 % des incidents critiques après 2 mois. Les équipes SRE & DATA ont identifié la cause profonde récurrente de certains problèmes majeurs, grâce aux données unifiées, et ont pu y remédier et suivre la maintenance. Le temps de réponse aux incidents s’est considérablement amélioré grâce aux résumés de l’IA et à toutes les mesures, leur permettant de savoir où enquêter.
Une analyse des causes profondes basée sur l’IA

Utiliser l’IA peut faire gagner beaucoup de temps. Surtout lorsqu’une enquête est nécessaire dans différentes bases de données et que vous ne savez pas par où commencer. L’ajout d’un agent IA dans la boucle peut vous fait gagner un temps considérable grâce à sa rapidité de traitement des données. Pour l’obtenir, un invite détaillée est nécessaire car l’agent remplacera un humain. Ainsi, pour obtenir les résultats les plus précis, même l’IA doit comprendre le contexte et recevoir des conseils. Autrement, il pourrait enquêter et tirer des conclusions non pertinentes. N’oubliez pas de assurez-vous de bien comprendre la cause du problème.
You are a Product Data & Revenue Analyst.
We detected an incident:
{{ $json.incident }}
Here is churn MRR by country (top offenders first):
{{ $json.churn_by_country }}
Here is churn MRR by plan:
{{ $json.churn_by_plan }}
1. Summarize what happened in simple business language.
2. Identify the most impacted segments (country, plan).
3. Propose 3-5 plausible hypotheses (product issues, price changes, bugs, market events).
4. Propose 3 concrete next steps for the Product team.Il est essentiel de noter qu’une fois les résultats obtenus, une dernière vérification est nécessaire pour s’assurer que l’analyse a été correctement effectuée. L’IA est un outil, mais cela peut aussi mal tourner, alors ne vous contentez pas de cela ; c’est un outil utile. Pour ce système, l’IA proposera le les trois principales causes probables de chaque incident.

Un meilleur alignement avec l’équipe de direction et un reporting basé sur les données. Tout est devenu davantage axé sur les données avec des analyses plus approfondies, et non sur l’intuition ou les rapports par segmentation. Cela a également conduit à une amélioration du processus.
Conclusion et points à retenir
En conclusion, créer un tableau de bord sur la santé des produits présente plusieurs avantages :
- Détecter les tendances négatives (MRR, DAU, engagement) plus tôt
- Réduisez les incidents critiques en identifiant les modèles de causes profondes
- Comprendre l’impact réel sur l’entreprise (utilisateurs concernés, risque de désabonnement)
- Hiérarchiser la feuille de route du produit en fonction du risque et de l’impact
- Alignez les produits, les données, le SRE et les revenus autour d’une seule source de vérité
C’est exactement ce qui manque à de nombreuses entreprises : une approche unifiée des données.

L’utilisation du workflow n8n a aidé de deux manières : être capable de résoudre les problèmes le plus rapidement possible et de rassembler les données en un seul endroit. L’outil d’automatisation a permis de réduire le temps consacré à cette tâche puisque l’entreprise était toujours en activité.
Leçons pour les équipes Produit

- Commencez simplement: la construction d’un système d’automatisation et d’un tableau de bord doit être clairement définie. Vous ne construisez pas un produit pour les clients, vous construisez un produit pour vos collaborateurs. Il est essentiel que vous compreniez les besoins de chaque équipe puisqu’elles sont vos principaux utilisateurs. Dans cette optique, ayez le produit qui sera votre MVP et répondra en premier à tous vos besoins. Ensuite, vous pouvez l’améliorer en ajoutant des fonctionnalités ou des métriques.
- Les métriques unifiées sont plus importantes qu’une détection parfaite : il faut garder à l’esprit que c’est grâce à eux que nous gagnerons du temps, ainsi que de la compréhension. Avoir une bonne détection est essentiel, mais si les métriques sont inexactes, le temps gagné sera perdu par les équipes qui recherchent les métriques dispersées dans différents environnements.
- L’automatisation permet de gagner 10 heures par semaine d’enquête manuelle : en automatisant certaines tâches manuelles et récurrentes, vous gagnerez des heures d’enquête, car avec le workflow d’alerte d’incident, nous savons directement où enquêter en premier et l’hypothèse de la cause et même certaines actions à entreprendre.
- Documentez tout: une documentation appropriée et détaillée est indispensable et permettra à toutes les parties impliquées d’avoir une compréhension et une vision claires de ce qui se passe. La documentation est également une donnée.
Qui suis-je ?
Je m’appelle Yassin, un chef de projet qui s’est développé dans la science des données pour combler le fossé entre les décisions commerciales et les systèmes techniques. L’apprentissage de Python, SQL et de l’analyse m’a permis de concevoir des informations sur les produits et des flux de travail d’automatisation qui relient les besoins des équipes au comportement des données. Connectons-nous sur Linkedin


