
Le « Calendrier de l’Avent » du Machine Learning Jour 5 : GMM dans Excel
Dans l’article précédent, nous avons exploré le clustering basé sur la distance avec K-Means.
plus loin : pour améliorer la façon dont la distance peut être mesurée, nous ajoutons de la variance, afin d’obtenir la distance de Mahalanobis.
Donc, si k-Means est la version non supervisée du Classificateur centroïde le plus prochealors la question naturelle est :
Qu’est-ce que la version non supervisée de QDA ?
Cela signifie que, comme QDA, chaque cluster doit désormais être décrit non seulement par son signifiermais aussi par son variance (et il faut aussi ajouter de la covariance si le nombre de fonctionnalités est supérieur à 2). Mais ici tout s’apprend sans étiquettes.
Alors vous voyez l’idée, non ?
Et bien, le nom de ce modèle est le Modèle de mélange gaussien (GMM)…
GMM et les noms de ces modèles…
Comme c’est souvent le cas, les noms des modèles proviennent de raisons historiques. Ils ne sont pas toujours conçus pour mettre en évidence les connexions entre les modèles, s’ils ne se retrouvent pas ensemble.
Différents chercheurs, différentes périodes, différents cas d’usage… et on se retrouve avec des noms qui cachent parfois la véritable structure derrière les idées.
Ici, le nom « Modèle de mélange gaussien » signifie simplement que les données sont représentées sous la forme d’un mélange de plusieurs distributions gaussiennes.
Si nous suivons la même logique de dénomination que k-Moyennesil aurait été plus clair de l’appeler quelque chose comme Mélange k-gaussien
Car, en pratique, au lieu d’utiliser uniquement les moyennes, on ajoute la variance. Et nous pourrions simplement utiliser la distance de Mahalanobis, ou une autre distance pondérée utilisant à la fois la moyenne et la variance. Mais la distribution gaussienne nous donne des probabilités plus faciles à interpréter.
Nous choisissons donc un numéro k de composantes gaussiennes.
Et d’ailleurs, GMM n’est pas le seul.
En fait, l’ensemble cadre d’apprentissage automatique est en réalité beaucoup plus récent que la plupart des modèles qu’il contient. La plupart de ces techniques ont été développées à l’origine dans les domaines de la statistique, du traitement du signal, de l’économétrie ou de la reconnaissance de formes.
Puis, bien plus tard, le domaine que nous appelons aujourd’hui « l’apprentissage automatique » a émergé et a regroupé tous ces modèles sous un même toit. Mais les noms n’ont pas changé.
Nous utilisons donc aujourd’hui un mélange de vocabulaires provenant de différentes époques, de différentes communautés et d’intentions différentes.
C’est pourquoi les relations entre les modèles ne sont pas toujours évidentes lorsqu’on regarde uniquement les noms.
Si nous devions tout renommer avec un nom moderne et unifié style d’apprentissage automatiquele paysage serait en réalité beaucoup plus clair :
- GMM deviendrait Clustering k-gaussien
- DAQ deviendrait Classificateur gaussien le plus proche
- LDA, eh bien, Classificateur gaussien le plus proche avec la même variance entre les classes.
Et du coup, tous les liens apparaissent :
- k-Means ↔ Centroïde le plus proche
- GMM ↔ Gaussienne la plus proche (QDA)
C’est pourquoi GMM est si naturel après K-Means. Si K-Means regroupe les points par leur centroïde le plus proche, alors GMM les regroupe par leur centroïde le plus proche. Forme gaussienne.
Pourquoi toute cette section pour discuter des noms ?
Eh bien, la vérité est que, puisque nous avons déjà couvert l’algorithme k-means et que nous avons déjà fait la transition du classificateur de centroïdes le plus proche vers QDA, nous savons déjà tout sur cet algorithme, et l’algorithme d’entraînement ne changera pas…
Et quel est le NOM de cet algorithme d’entraînement ?
Oh, l’algorithme de Lloyd.
En fait, avant que k-means ne soit appelé ainsi, il était simplement connu sous le nom d’algorithme de Lloyd, publié par Stuart Lloyd dans 1957. Ce n’est que plus tard que la communauté du machine learning l’a changé en « k-means ».
Et cet algorithme ne manipulait que les moyens, donc il nous faut un autre nom, non ?
Vous voyez où cela nous mène : l’algorithme de maximisation des attentes !
L’EM est simplement la forme générale de l’idée de Lloyd. Lloyd met à jour les moyens, EM met à jour tout: moyennes, variances, poids et probabilités.
Alors, vous savez déjà tout sur GMM !
Mais comme mon article s’intitule « GMM dans Excel », je ne peux pas terminer mon article ici…
GMM en 1 Dimension
Commençons par cet ensemble de données simple, le même que celui que nous avons utilisé pour les k-means : 1, 2, 3, 11, 12, 13
Hmm, les deux Gaussiennes auront les mêmes écarts. Pensez donc à jouer avec d’autres nombres dans Excel !
Et nous voulons naturellement 2 grappes.
Voici les différentes étapes.
Initialisation
Nous commençons par des suppositions sur les moyennes, les variances et les poids.

Étape d’attente (étape E)
Pour chaque point, nous calculons la probabilité qu’il appartienne à chaque gaussienne.

Étape de maximisation (étape M)
À l’aide de ces probabilités, nous mettons à jour les moyennes, les variances et les poids.

Itération
Nous répétons les étapes E et M jusqu’à ce que les paramètres se stabilisent.

Chaque étape est extrêmement simple une fois les formules visibles.
Vous verrez que l’EM n’est rien d’autre que la mise à jour des moyennes, des variances et des probabilités.
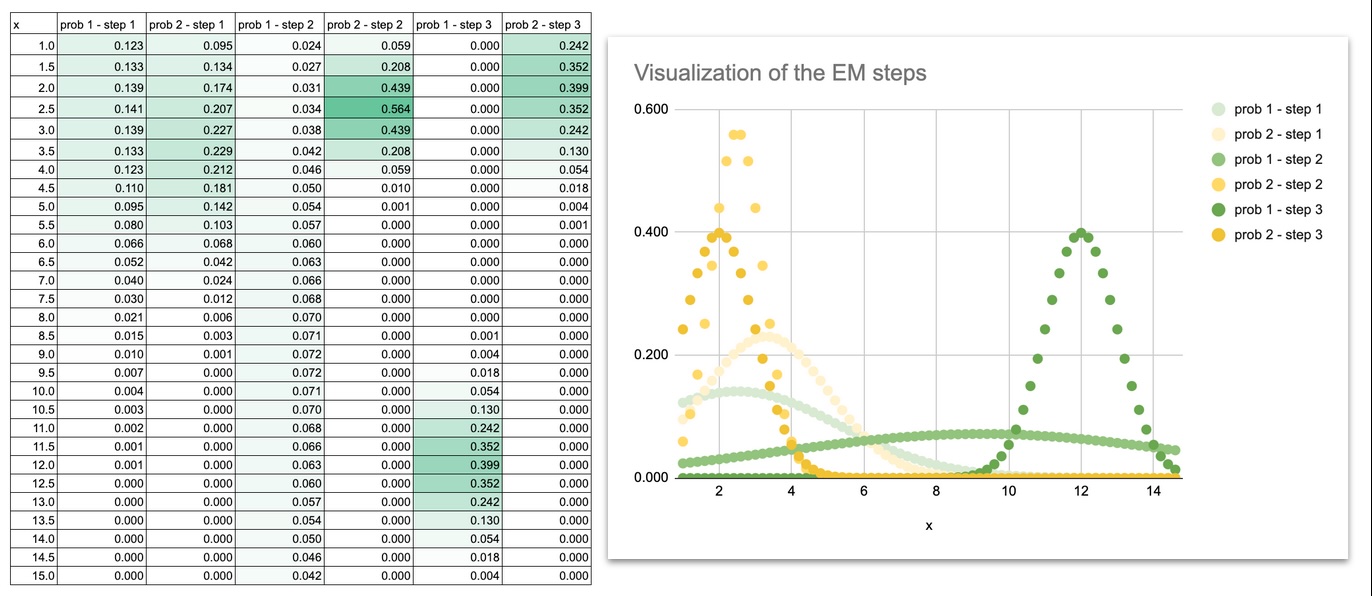
Nous pouvons également faire une visualisation pour voir comment les courbes gaussiennes se déplacent au cours des itérations.
Au début, les deux courbes de Gauss se chevauchent fortement car les moyennes et variances initiales ne sont que des suppositions.
Les courbes se séparent lentement, ajustent leurs largeurs et finalement se fixent exactement sur les deux groupes de points.
En traçant les courbes de Gauss à chaque itération, vous pouvez littéralement montre le modèle apprend :
- les moyens glissent vers les centres des données
- les écarts diminuent pour correspondre à la répartition de chaque groupe
- le chevauchement disparaît
- les formes finales correspondent à la structure de l’ensemble de données
Cette évolution visuelle est extrêmement utile pour l’intuition. Une fois que vous voyez les courbes bouger, l’EM n’est plus un algorithme abstrait. Cela devient un processus dynamique que vous pouvez suivre étape par étape.

GMM en 2 dimensions
La logique est exactement la même qu’en 1D. Rien de nouveau sur le plan conceptuel. On étend simplement les formules…
Au lieu d’avoir une fonctionnalité par point, nous avons maintenant deux.
Chaque Gaussien doit maintenant apprendre :
- une moyenne pour x1
- une moyenne pour x2
- un écart pour x1
- un écart pour x2
- ET un terme de covariance entre les deux caractéristiques.
Une fois que vous aurez écrit les formules dans Excel, vous verrez que le processus reste exactement le même :
Eh bien, la vérité est que si vous regardez la capture d’écran, vous pourriez penser : « Wow, la formule est tellement longue !» Et ce n’est pas tout.

Mais ne vous y trompez pas. La formule est longue uniquement parce que nous écrivons le Densité gaussienne bidimensionnelle explicitement :
- une partie pour la distance en x1
- une partie pour la distance en x2
- le terme de covariance
- la constante de normalisation
Rien de plus.
Il s’agit simplement de la formule de densité développée cellule par cellule.
Long à taper, mais parfaitement compréhensible une fois qu’on voit la structure : une distance pondérée, à l’intérieur d’une exponentielle, divisée par le déterminant.
Alors oui, la formule paraît grande… mais l’idée derrière est extrêmement simple.
Conclusion
K-Means donne des limites strictes.
GMM donne des probabilités.
Une fois les formules EM écrites dans Excel, le modèle devient simple à suivre : les moyennes bougent, les variances s’ajustent et les gaussiennes s’installent naturellement autour des données.
GMM n’est que la prochaine étape logique après k-Means, offrant une manière plus flexible de représenter les clusters et leurs formes.


