
Le « Calendrier de l’Avent » du Machine Learning Jour 3 : GNB, LDA et QDA dans Excel
en travaillant avec k-NN (régresseur k-NN et classificateur k-NN), nous savons que l’approche k-NN est très naïve. Il conserve l’intégralité de l’ensemble de données d’entraînement en mémoire, s’appuie sur des distances brutes et n’apprend aucune structure à partir des données.
Nous avons déjà commencé à améliorer le classificateur k-NN, et dans l’article d’aujourd’hui, nous allons implémenter ces différents modèles :
- GNB : Bayes naïf gaussien
- LDA : analyse discriminante linéaire
- QDA : analyse discriminante quadratique
Pour tous ces modèles, la distribution est considérée comme gaussienne. Donc à la fin, nous verrons également une approche pour obtenir une distribution plus personnalisée.
Si vous avez lu mon article précédent, voici quelques questions pour vous :
- Quelle est la relation entre LDA et QDA ?
- Quelle est la relation entre GBN et QDA ?
- Que se passe-t-il si les données ne sont pas du tout gaussiennes ?
- Quelle est la méthode pour obtenir une distribution personnalisée ?
- Qu’est-ce qui est linéaire en LDA ? Qu’est-ce que le quadratique en QDA ?
En lisant l’article, vous pouvez utiliser cette feuille Excel/Google.

Centroïdes les plus proches : ce qu’est réellement ce modèle
Faisons un bref récapitulatif de ce que nous avons déjà commencé hier.
Nous avons introduit une idée simple : lorsque nous calculons la moyenne de chaque entité continue à l’intérieur d’une classe, cette classe se réduit en un seul point représentatif.
Cela nous donne le modèle des centroïdes les plus proches.
Chaque classe est résumée par son centroïde, la moyenne de toutes ses valeurs de caractéristiques.
Maintenant, réfléchissons à cela du point de vue du Machine Learning.
Nous séparons généralement le processus en deux parties : la entraînement étape et le réglage des hyperparamètres étape.
Pour les centroïdes les plus proches, nous pouvons dessiner une petite « carte modèle » pour comprendre ce qu’est réellement ce modèle :
- Comment le modèle est-il formé ? En calculant un vecteur moyen par classe. Rien de plus.
- Gère-t-il les valeurs manquantes ? Oui. Un centroïde peut être calculé en utilisant toutes les valeurs disponibles (non vides).
- L’échelle est-elle importante ? Oui, absolument, car la distance à un centre de gravité dépend des unités de chaque entité.
- Quels sont les hyperparamètres ? Aucun.
Nous avons dit que le classificateur k-NN n’est peut-être pas un véritable modèle d’apprentissage automatique car ce n’est pas un modèle réel.
Pour les centroïdes les plus proches, on peut dire qu’il ne s’agit pas vraiment d’un modèle d’apprentissage automatique car il ne peut pas être réglé. Alors qu’en est-il du surapprentissage et du sous-apprentissage ?
Eh bien, le modèle est si simple qu’il ne peut pas mémoriser le bruit de la même manière que k-NN.
Ainsi, les centroïdes les plus proches auront seulement tendance à sous-ajustement lorsque les classes sont complexes ou mal séparées, car un seul centroïde ne peut pas capturer toute leur structure.
Comprendre la forme des classes avec une seule fonctionnalité : ajouter de la variance
Désormais, dans cette section, nous n’utiliserons qu’une seule fonctionnalité continue et 2 classes.
Jusqu’à présent, nous n’utilisions qu’une seule statistique par classe : la valeur moyenne.
Ajoutons maintenant une deuxième information : le variance (ou de manière équivalente, l’écart type).
Cela nous indique à quel point chaque classe est « répartie » autour de sa moyenne.
Une question naturelle apparaît immédiatement : quelle variance devrions-nous utiliser ?
La réponse la plus intuitive est de calculer un écart par classecar chaque classe peut avoir une répartition différente.
Mais il existe une autre possibilité : on pourrait calculer un écart commun pour les deux classesgénéralement sous forme de moyenne pondérée des variances de classe.
Cela semble un peu contre nature au début, mais nous verrons plus tard que cette idée mène directement à LDA.
Le tableau ci-dessous nous donne donc tout ce dont nous avons besoin pour ce modèle, en fait pour les deux versions (LDA et QDA) du modèle.
- le nombre d’observations dans chaque classe (pour pondérer les classes)
- la moyenne de chaque classe
- l’écart type de chaque classe
- et l’écart type commun aux deux classes
Avec ces valeurs, l’ensemble du modèle est complètement défini.

Maintenant, une fois que nous avons un écart type, nous pouvons construire une distance plus raffinée : la distance au centre de gravité. divisé par l’écart type.
Pourquoi faisons-nous cela ?
Parce que cela donne une distance qui est escaladé par la variabilité de la classe.
Si une classe a un écart type important, être loin de son centroïde n’est pas surprenant.
Si une classe présente un très petit écart type, même un petit écart devient significatif.
Cette simple normalisation transforme notre distance euclidienne en quelque chose d’un peu plus significatif, qui représente la forme de chaque classe.
Cette distance a été introduite par Mahalanobis, c’est pourquoi nous l’appelons la distance de Mahalanobis.
Nous pouvons désormais effectuer tous ces calculs directement dans le fichier Excel.

Les formules sont simples et avec la mise en forme conditionnelle, nous pouvons clairement voir comment la distance par rapport à chaque centre change et comment la mise à l’échelle affecte les résultats.

Maintenant, faisons quelques tracés, toujours dans Excel.
Le diagramme ci-dessous montre la progression complète : comment nous partons de la distance de Mahalanobis, passons à la vraisemblance sous chaque distribution de classe et obtenons enfin la prédiction de probabilité.

LDA vs QDA, que voit-on ?
Avec une seule fonctionnalité, la différence devient très facile à visualiser.
Pour LDAla séparation sur l’axe des x est toujours coupée en deux parties. C’est pourquoi la méthode est appelée Linéaire Analyse discriminante.
Pour DAQmême avec une seule fonctionnalité, le modèle produit deux points de coupe sur l’axe des x. Dans les dimensions supérieures, cela devient une frontière courbe, décrite par un fonction quadratique. D’où le nom Quadratique Analyse discriminante.

Et vous pouvez directement modifier les paramètres pour voir leur impact sur la limite de décision.
Les changements dans les moyennes ou les variances modifieront la frontière, et Excel rend ces effets très faciles à visualiser.
Au fait, la forme de la courbe de probabilité LDA vous rappelle-t-elle un modèle que vous connaissez sûrement ? Oui, c’est exactement la même chose.
Vous pouvez déjà deviner lequel, n’est-ce pas ?
Mais maintenant la vraie question est : sont-ils vraiment le même modèle ? Et sinon, en quoi diffèrent-ils ?

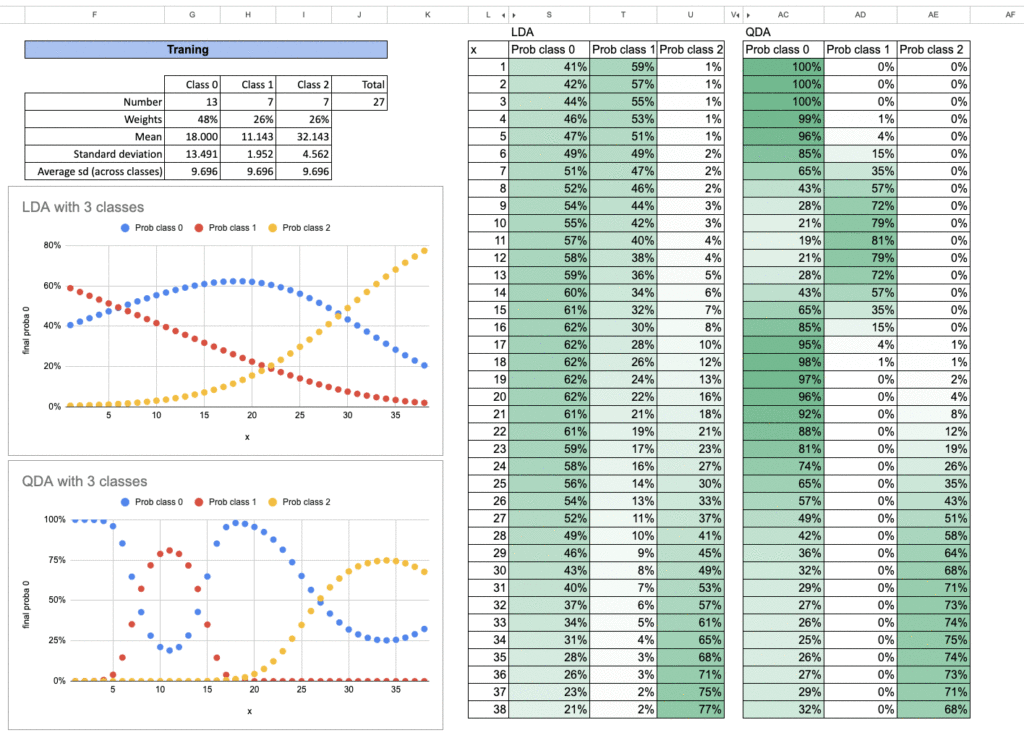
On peut également étudier le cas à trois classes. Vous pouvez l’essayer vous-même comme exercice dans Excel.
Voici les résultats. Pour chaque classe, nous répétons exactement la même procédure. Et pour la prédiction de probabilité finale, nous additionnons simplement toutes les probabilités et prenons la proportion de chacune.

Encore une fois, cette approche est également utilisée dans un autre modèle bien connu.
Savez-vous lequel ? Il est beaucoup plus familier à la plupart des gens, ce qui montre à quel point ces modèles sont étroitement liés.
Lorsque vous comprenez l’un d’eux, vous comprenez automatiquement beaucoup mieux les autres.
Forme de classe en 2D : variance uniquement ou covariance également ?
Avec une fonctionnalité, on ne parle pas de dépendance, puisqu’il n’y en a pas. Donc, dans ce cas, QDA se comporte exactement comme le Bayes naïf gaussien. Parce que nous permettons généralement à chaque classe d’avoir sa propre variance, ce qui est parfaitement naturel.
La différence apparaîtra lorsque nous passerons à deux fonctionnalités ou plus. À ce stade, nous distinguerons des cas de manière dont le modèle traite le covariance entre les fonctionnalités.
Le Bayes naïf gaussien fait une hypothèse simplificatrice très forte :
les fonctionnalités sont indépendantes. C’est la raison du mot Naïf en son nom.
LDA et QDA ne font cependant pas cette hypothèse. Ils permettent des interactions entre les entités, et c’est ce qui génère des limites linéaires ou quadratiques dans des dimensions supérieures.
Faisons l’exercice dans Excel !
Bayes naïves gaussiennes : pas de covariance
Commençons par le cas le plus simple : le Bayes naïf gaussien.
Nous n’avons donc pas besoin de calculer de covariance, car le modèle suppose que les caractéristiques sont indépendantes.
Pour illustrer cela, nous pouvons regarder un petit exemple avec trois classes.

QDA : chaque classe a sa propre covariance
Pour QDA, nous devons maintenant calculer la matrice de covariance pour chaque classe.
Et une fois que nous l’avons, nous devons également calculer son inverse, car il est utilisé directement dans la formule de la distance et de la vraisemblance.
Il y a donc quelques paramètres supplémentaires à calculer par rapport au Bayes naïf gaussien.

LDA : toutes les classes partagent la même covariance
Pour LDA, toutes les classes partagent la même matrice de covariance, ce qui réduit le nombre de paramètres et oblige la limite de décision à être linéaire.
Même si le modèle est plus simple, il reste très efficace dans de nombreuses situations, notamment lorsque la quantité de données est limitée.

Distributions de classes personnalisées : au-delà de l’hypothèse gaussienne
Jusqu’à présent, nous n’avons parlé que de distributions gaussiennes. Et c’est pour sa simplicité. Et nous pouvons également utiliser d’autres distributions. Ainsi, même dans Excel, il est très simple de modifier.
En réalité, les données ne suivent généralement pas une courbe gaussienne parfaite.
Pour explorer un ensemble de données, nous utilisons presque à chaque fois les tracés de densité empiriques. Ils donnent une idée visuelle immédiate de la manière dont les données sont distribuées.
Et le estimateur de densité de noyau (KDE) en tant que méthode non paramétrique, est souvent utilisée.
MAIS, en pratique, KDE est rarement utilisé comme modèle de classification complet. Ce n’est pas très pratique et ses prédictions sont souvent sensibles au choix de la bande passante.
Et ce qui est intéressant c’est que cette idée de noyaux reviendra lorsque l’on discutera d’autres modèles.
Ainsi, même si nous le montrons ici principalement à des fins d’exploration, il s’agit d’un élément essentiel de l’apprentissage automatique.

Conclusion
Aujourd’hui, nous avons suivi un chemin naturel qui commence par de simples moyennes et mène progressivement à des modèles probabilistes complets.
- Les centroïdes les plus proches compressent chaque classe en un seul point.
- Le Bayes naïf gaussien ajoute la notion de variance et suppose l’indépendance des caractéristiques.
- QDA donne à chaque classe sa propre variance ou covariance
- LDA simplifie la forme en partageant la covariance.
Nous avons même vu que nous pouvions sortir du monde gaussien et explorer des distributions personnalisées.
Tous ces modèles sont reliés par la même idée : une nouvelle observation appartient à la classe à laquelle elle ressemble le plus.
La différence réside dans la manière dont nous définissons la ressemblance, par distance, par variance, par covariance ou par une distribution de probabilité complète.
Pour tous ces modèles, nous pouvons effectuer les deux étapes facilement dans Excel :
- la première étape consiste à estimer les paramètres, qui peuvent être considérés comme le modèle de formation
- l’étape d’inférence qui consiste à calculer la distance et la probabilité pour chaque classe

Encore une chose
Avant de clôturer cet article, dressons une petite cartographie des modèles supervisés à distance.
Nous avons deux grandes familles :
- modèles de distance locale
- modèles de distance globale
Pour distance localeon connaît déjà les deux classiques :
- régresseur k-NN
- classificateur k-NN
Les deux prédisent en examinant les voisins et en utilisant la géométrie locale des données.
Pour distance globaletous les modèles que nous avons étudiés aujourd’hui appartiennent au monde de la classification.
Pourquoi?
Parce que la distance mondiale nécessite centres définis par classes.
Nous mesurons à quel point une nouvelle observation est proche de chaque prototype de classe ?
Mais qu’en est-il régression?
Il semble que cette notion de distance globale n’existe pas pour la régression, ou existe-t-elle vraiment ?
La réponse est oui, cela existe…



