Le « Calendrier de l’Avent » du Machine Learning Jour 19 : Ensachage dans Excel
nous avons exploré la plupart des modèles de base d’apprentissage automatique, organisés en trois grandes familles : les modèles basés sur la distance et la densité, les modèles basés sur des arbres ou des règles et les modèles basés sur le poids.
Jusqu’à présent, chaque article se concentrait sur un seul modèle, formé de manière autonome. L’apprentissage d’ensemble change complètement cette perspective. Ce n’est pas un modèle autonome. C’est plutôt une manière de combinant ces modèles de base pour construire quelque chose de nouveau.
Comme l’illustre le diagramme ci-dessous, un ensemble est un méta-modèle. Il s’ajoute aux modèles individuels et regroupe leurs prédictions.

Voter : l’idée d’ensemble la plus simple
La forme la plus simple d’apprentissage d’ensemble est vote.
L’idée est presque triviale : entraîner plusieurs modèles, prendre leurs prédictions et calculer la moyenne. Si un modèle est faux dans un sens et qu’un autre est faux dans le sens opposé, les erreurs devraient s’annuler. Du moins, c’est l’intuition.
Sur le papier, cela semble raisonnable. En pratique, les choses sont très différentes.
Dès que vous essayez de voter sur de vrais modèles, un fait devient évident : voter n’est pas magique. La simple moyenne des prévisions ne garantit pas de meilleures performances. Dans de nombreux cas, cela ne fait qu’empirer les choses.
La raison est simple. Lorsque vous combinez des modèles qui se comportent très différemment, vous combinez également leurs faiblesses. Si les modèles ne commettent pas d’erreurs complémentaires, la moyenne peut diluer la structure utile au lieu de la renforcer.
Pour y voir clair, prenons un exemple très simple. Prenez un arbre de décision et une régression linéaire entraînée sur le même ensemble de données. L’arbre de décision capture des modèles locaux non linéaires. La régression linéaire capture une tendance linéaire globale. Lorsque vous faites la moyenne de leurs prédictions, vous n’obtenez pas un meilleur modèle. Vous obtenez un compromis souvent moins bon que chaque modèle pris individuellement.

Cela illustre un point important : l’apprentissage d’ensemble nécessite plus qu’une moyenne. Cela nécessite une stratégie. Une façon de combiner des modèles qui améliore réellement la stabilité ou la généralisation.
De plus, si l’on considère l’ensemble comme un modèle unique, alors il doit être formé comme tel. La moyenne simple n’offre aucun paramètre à ajuster. Il n’y a rien à apprendre, rien à optimiser.
Une amélioration possible du vote consiste à attribuer des pondérations différentes aux modèles. Au lieu de donner à chaque modèle la même importance, nous pourrions essayer de déterminer lesquels devraient avoir le plus d’importance. Mais dès que l’on introduit les poids, une nouvelle question apparaît : comment les entraîner ? L’ensemble lui-même devient alors un modèle qu’il faut adapter.
Cette observation conduit naturellement à des méthodes d’ensemble plus structurées.
Dans cet article, nous commençons par une approche statistique pour rééchantillonner l’ensemble de données d’entraînement avant de faire la moyenne : Ensachage.
L’intuition derrière l’ensachage
Qu’est-ce que l’ensachage ?
La réponse est en fait cachée dans le nom lui-même.
Ensachage = Bootstrap + Agrégation.
Vous pouvez immédiatement dire que c’est un mathématicien ou un statisticien qui l’a nommé. 🙂
Derrière ce mot un peu intimidant, l’idée est extrêmement simple. Le bagging consiste à faire deux choses : premièrement, créer de nombreuses versions de l’ensemble de données à l’aide du bootstrap, et deuxièmement, agréger les résultats obtenus à partir de ces ensembles de données.
L’idée centrale n’est donc pas de changer de modèle. Il s’agit de changer le données.
Amorcer l’ensemble de données
L’amorçage signifie échantillonner l’ensemble de données avec remplacement. Chaque échantillon bootstrap a la même taille que l’ensemble de données d’origine, mais pas les mêmes observations. Certaines lignes apparaissent plusieurs fois. D’autres disparaissent.
Dans Excel, c’est très simple à mettre en œuvre et, surtout, très facile à voir.
Vous commencez par ajouter une colonne ID à votre ensemble de données, un identifiant unique par ligne. Ensuite, en utilisant le RANDBETWEEN fonction, vous dessinez au hasard des indices de ligne. Chaque tirage correspond à une ligne de l’échantillon bootstrap. En répétant ce processus, vous générez un ensemble de données complet qui semble familier, mais qui est légèrement différent de l’original.
Cette étape à elle seule fait déjà naître l’idée d’ensacher le béton. Vous pouvez littéralement voir les doublons. Vous pouvez voir quelles observations manquent. Rien n’est abstrait.
Ci-dessous, vous pouvez voir des exemples d’échantillons bootstrap générés à partir du même ensemble de données d’origine. Chaque échantillon raconte une histoire légèrement différente, même si tous proviennent des mêmes données.
Ces ensembles de données alternatifs constituent la base du bagging.

Régression linéaire Bagging : comprendre le principe
Processus d’ensachage
Oui, c’est probablement la première fois que vous entendez parler régression linéaire d’ensachage.
En théorie, il n’y a rien de mal à cela. Comme nous l’avons dit plus tôt, l’ensachage est une méthode d’ensemble qui peut être appliquée à n’importe quel modèle de base. La régression linéaire est un modèle, donc techniquement, elle est admissible.
En pratique cependant, vous verrez vite que cela n’est pas très utile.
Mais rien ne nous empêche de le faire. Et précisément parce que ce n’est pas très utile, cela constitue un excellent exemple d’apprentissage. Alors faisons-le.
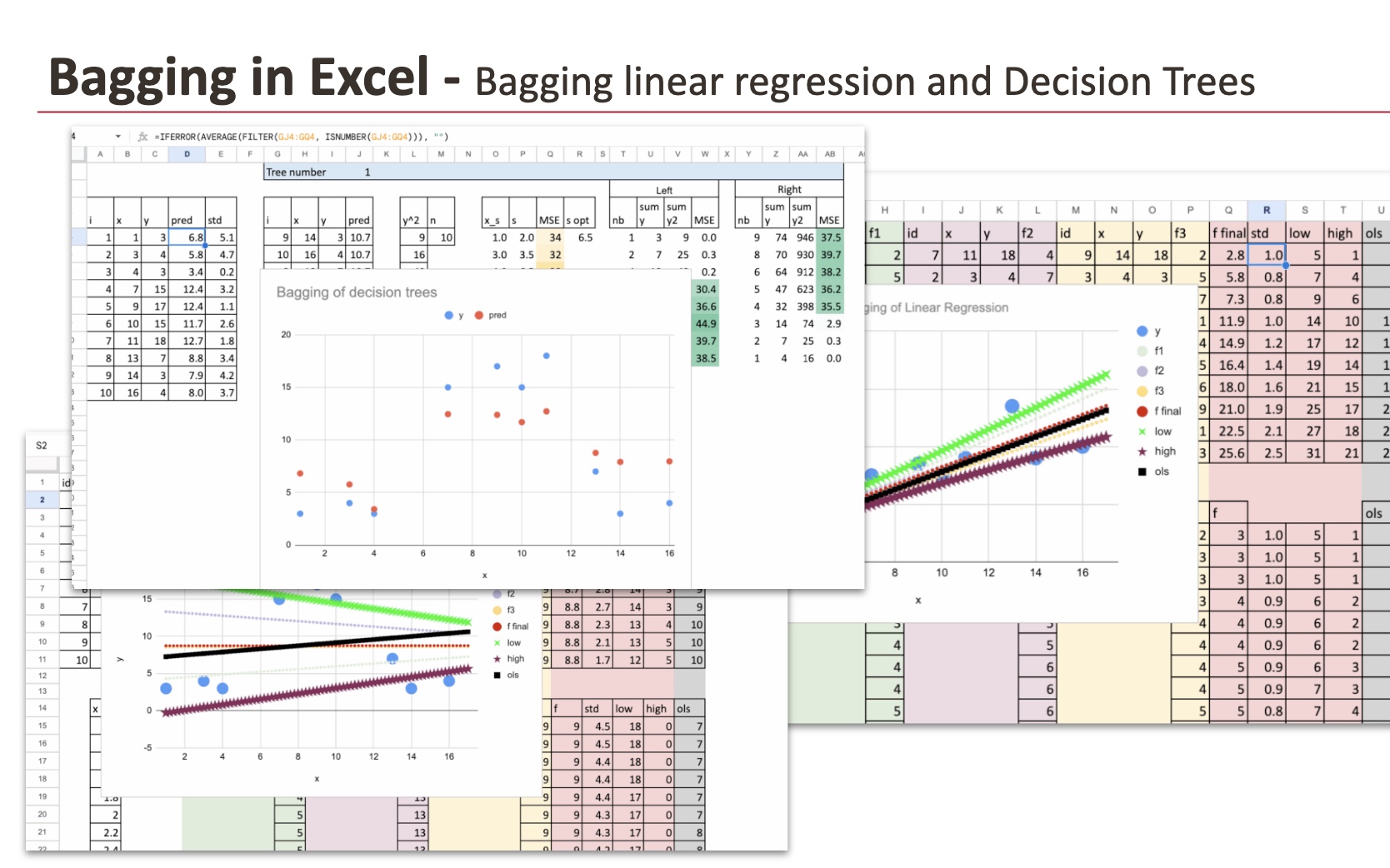
Pour chaque échantillon bootstrap, nous effectuons une régression linéaire. Dans Excel, c’est simple. On peut utiliser directement le LINEST fonction pour estimer les coefficients. Chaque couleur du graphique correspond à un échantillon bootstrap et à sa droite de régression associée.
Jusqu’à présent, tout se comporte exactement comme prévu. Les lignes sont proches les unes des autres, mais pas identiques. Chaque échantillon bootstrap modifie légèrement les coefficients, et donc la droite ajustée.

Vient maintenant l’observation clé.
Vous remarquerez peut-être qu’un modèle supplémentaire est tracé en noir. Celle-ci correspond à la régression linéaire standard ajustée sur le ensemble de données d’originesans bootstrap.
Que se passe-t-il lorsque nous le comparons aux modèles en sac ?
Lorsque nous faisons la moyenne des prédictions de toutes ces régressions linéaires, le résultat final est toujours une régression linéaire. La forme de la prédiction ne change pas. La relation entre les variables reste linéaire. Nous n’avons pas créé de modèle plus expressif.
Et plus important encore, le modèle en sac finit par être très proche de la régression linéaire standard entraînée sur les données d’origine.
On peut même pousser l’exemple plus loin en utilisant un jeu de données avec une structure clairement non linéaire. Dans ce cas, chaque régression linéaire ajustée sur un échantillon bootstrap rencontre des difficultés à sa manière. Certaines lignes s’inclinent légèrement vers le haut, d’autres vers le bas, selon les observations dupliquées ou manquantes dans l’échantillon.

Intervalles de confiance bootstrap
Du point de vue des performances de prédiction, la régression linéaire par bagging n’est pas très utile.
Cependant, le bootstrapping reste extrêmement utile pour une notion statistique importante: estimation du intervalle de confiance des prédictions.
Au lieu de regarder uniquement la prévision moyenne, nous pouvons examiner la distribution de prédictions produites par tous les modèles bootstrapés. Pour chaque valeur d’entrée, nous disposons désormais de plusieurs valeurs prédites, une pour chaque échantillon bootstrap.
Un moyen simple et intuitif de quantifier l’incertitude consiste à calculer la écart type de ces prédictions. Cet écart type nous indique à quel point la prédiction est sensible aux changements dans les données. Une petite valeur signifie que la prédiction est stable. Une valeur élevée signifie qu’elle est incertaine.
Cette idée fonctionne naturellement dans Excel. Une fois que vous disposez de toutes les prédictions des modèles bootstrapés, le calcul de leur écart type est simple. Le résultat peut être interprété comme une bande de confiance autour de la prédiction.
Ceci est clairement visible dans l’intrigue ci-dessous. L’interprétation est simple : dans les régions où les données d’entraînement sont rares ou très dispersées, l’intervalle de confiance devient large, car les prédictions varient considérablement selon les échantillons bootstrap.
À l’inverse, lorsque les données sont denses, les prédictions sont plus stables et l’intervalle de confiance se rétrécit.

Maintenant, lorsque nous appliquons cela à des données non linéaires, quelque chose devient très clair. Dans les régions où le modèle linéaire a du mal à s’adapter aux données, les prédictions des différents échantillons bootstrap s’étalent beaucoup plus. L’intervalle de confiance devient plus large.
C’est une idée importante. Même lorsque l’ensachage n’améliore pas la précision des prévisions, il fournit des informations précieuses sur incertitude. Cela nous indique où le modèle est fiable et où il ne l’est pas.
Voir ces intervalles de confiance émerger directement des échantillons bootstrap dans Excel rend ce concept statistique très concret et intuitif.

Arbres de décision ensachés : des apprenants faibles à un modèle fort
Passons maintenant aux arbres de décision.
Le principe de l’ensachage reste exactement le même. Nous générons plusieurs échantillons bootstrap, formons un modèle sur chacun d’eux, puis regroupons leurs prédictions.
J’ai amélioré l’implémentation d’Excel pour rendre le processus de fractionnement plus automatique. Pour que les choses restent gérables dans Excel, nous limitons les arbres à une seule division. Construire des arbres plus profonds est possible, mais cela devient vite fastidieux dans un tableur.
Ci-dessous, vous pouvez voir deux des arbres bootstrapés. Au total, j’en ai construit huit en copiant et collant simplement des formules, ce qui rend le processus simple et facile à reproduire.

Étant donné que les arbres de décision sont des modèles hautement non linéaires et que leurs prédictions sont constantes par morceaux, la moyenne de leurs résultats a un effet de lissage.
En conséquence, l’ensachage lisse naturellement les prédictions. Au lieu de sauts brusques créés par des arbres individuels, le modèle agrégé produit des transitions plus graduelles.
Dans Excel, cet effet est très facile à observer. Les prédictions en sac sont clairement plus fluides que les prédictions de n’importe quel arbre.

Certains d’entre vous en ont peut-être déjà entendu parler souches de décisionqui sont des arbres de décision d’une profondeur maximale de un. C’est exactement ce que nous utilisons ici. Chaque modèle est extrêmement simple. En soi, une souche est un apprenant faible.
La question ici est :
une collection de souches de décision est-elle suffisante lorsqu’elle est combinée avec un bagging ?
Nous y reviendrons plus tard dans mon « Calendrier de l’Avent » de Machine Learning.
Random Forest : extension de l’ensachage
Et la forêt aléatoire ?
C’est probablement l’un des modèles préférés des data scientists.
Alors pourquoi ne pas en parler ici, même sous Excel ?
En fait, ce que nous venons de construire est déjà très proche d’une Random Forest !
Pour comprendre pourquoi, rappelons que Random Forest introduit deux sources d’aléatoire.
- Le premier est le bootstrap de l’ensemble de données. C’est exactement ce que nous avons déjà fait avec l’ensachage.
- Le deuxième est le caractère aléatoire du processus de division. À chaque division, seul un sous-ensemble aléatoire de fonctionnalités est pris en compte.
Cependant, dans notre cas, nous n’avons qu’une seule fonctionnalité. Cela signifie qu’il n’y a rien parmi lequel choisir. Le caractère aléatoire des fonctionnalités ne s’applique tout simplement pas.
En conséquence, ce que nous obtenons ici peut être considéré comme une forêt aléatoire simplifiée.
Une fois ce concept clair, étendre l’idée à plusieurs fonctionnalités n’est qu’une couche supplémentaire de hasard, pas un nouveau concept.
Et vous vous demanderez peut-être même si nous pouvons appliquer ce principe à la régression linéaire et effectuer une analyse aléatoire.
Conclusion
L’apprentissage d’ensemble concerne moins les modèles complexes que la gestion de l’instabilité.
Le simple vote est rarement efficace. La régression linéaire Bagging change peu et reste surtout pédagogique, même si elle est utile pour estimer l’incertitude. Cependant, avec les arbres de décision, le regroupement est vraiment important : la moyenne des modèles instables conduit à des prédictions plus fluides et plus robustes.
Random Forest étend naturellement cette idée en ajoutant du caractère aléatoire supplémentaire, sans changer le principe de base. Vu dans Excel, les méthodes d’ensemble cessent d’être des boîtes noires et deviennent une prochaine étape logique.
Merci pour votre soutien à mon « Calendrier de l’Avent » de Machine Learning.
On parle généralement beaucoup de l’apprentissage supervisé, mais l’apprentissage non supervisé est parfois négligé, même s’il peut révéler une structure qu’aucune étiquette ne pourrait jamais montrer.
Si vous souhaitez approfondir ces idées, voici trois articles qui plongent dans de puissants modèles non supervisés.
Modèle de mélange gaussien
Une version améliorée et plus flexible de k-means.
Contrairement aux k-means, GMM permet aux clusters de s’étirer, de pivoter et de s’adapter à la véritable forme des données.
Mais quand les k-means et GMM produisent-ils réellement des résultats différents ?
Jetez un œil à cet article pour voir des exemples concrets et des comparaisons visuelles.
Facteur de valeur aberrante locale (LOF)
Une méthode astucieuse qui compare la densité locale de chaque point à celle de ses voisins pour détecter les anomalies.
Tous les fichiers Excel sont disponibles via ce Lien Kofi. Votre soutien compte beaucoup pour moi. Le prix augmentera au cours du mois, afin que les premiers supporters bénéficient du meilleur rapport qualité-prix.