
Le « Calendrier de l’Avent » de Machine Learning Jour 16 : Astuce du noyau dans Excel
article sur SVM, la prochaine étape naturelle est Kernel SVM.
À première vue, cela ressemble à un modèle complètement différent. L’entraînement se déroule sous la forme dual, on arrête de parler de pente et d’interception, et du coup tout tourne autour d’un « noyau ».
Dans l’article d’aujourd’hui, je ferai le mot noyau concret en visualisant ce qu’il fait réellement.
Il existe de nombreuses bonnes façons d’introduire le Kernel SVM. Si vous avez lu mes articles précédents, vous savez que j’aime partir de quelque chose de simple que vous connaissez déjà.
Une manière classique de présenter le Kernel SVM est la suivante : SVM est un modèle linéaire. Si la relation entre les entités et la cible est non linéaire, une ligne droite ne séparera pas bien les classes. Nous créons donc de nouvelles fonctionnalités. La régression polynomiale est toujours un modèle linéaire, on ajoute simplement des caractéristiques polynomiales (x, x², x³, …). De ce point de vue, un noyau polynomial effectue implicitement une régression polynomiale, et un Noyau RBF peut être considéré comme utilisant une série infinie de caractéristiques polynomiales…
Peut-être qu’un autre jour nous suivrons ce chemin, mais aujourd’hui nous en prendrons un autre : nous commençons par KDE.
Oui, Estimation de la densité du noyau.
Commençons.
Et vous pouvez utiliser ce lien pour obtenir la feuille Google

1. KDE comme somme de densités individuelles
J’ai présenté KDE dans l’article sur LDA et QDA, et à ce moment-là j’ai dit que nous le réutiliserions plus tard. C’est le moment.
Nous voyons le mot noyau dans KDE, et nous le voyons également dans SVM du noyau. Ce n’est pas un hasard, il existe un vrai lien.
L’idée de KDE est simple :
autour de chaque point de données, nous plaçons une petite distribution (un noyau).
Ensuite, nous additionner toutes ces densités individuelles ensemble pour obtenir une distribution mondiale.
Gardez cette idée à l’esprit. Ce sera la clé pour comprendre le Kernel SVM.

Nous pouvons également ajuster un paramètre pour contrôler la fluidité de la densité globale, de très locale à très fluide, comme illustré dans le GIF ci-dessous.

Comme vous le savez, KDE est un modèle basé sur la distance ou la densité, nous allons donc ici créer un lien entre deux modèles de deux familles différentes.
2. Transformer KDE en modèle
Maintenant, nous réutilisons exactement la même idée pour construire une fonction autour de chaque point, et cette fonction peut ensuite être utilisée pour la classification.
Vous souvenez-vous que la tâche de classification avec les modèles basés sur les poids est d’abord une tâche de régression, car la valeur y est toujours considérée comme continue ? Nous effectuons la partie classification uniquement après avoir obtenu la fonction de décision ou f(x).
2.1. (Toujours) en utilisant un simple ensemble de données
Quelqu’un m’a demandé un jour pourquoi j’utilisais toujours environ 10 points de données pour expliquer l’apprentissage automatique, affirmant que cela n’avait aucun sens.
Je suis fortement en désaccord.
Si quelqu’un ne peut pas expliquer comment fonctionne un modèle de Machine Learning avec 10 points (ou moins) et une seule fonctionnalité, alors il ne comprend pas vraiment comment fonctionne ce modèle.
Ce ne sera donc pas une surprise pour vous. Oui, j’utiliserai toujours cet ensemble de données très simple, que j’ai déjà utilisé pour la régression logistique et le SVM. Je sais que cet ensemble de données est linéairement séparable, mais il est intéressant de comparer les résultats des modèles.
Et j’ai également généré un autre ensemble de données avec des points de données qui ne sont pas linéairement séparables et visualisé le fonctionnement du modèle kernelisé.

2.2. Noyau RBF centré sur les points
Appliquons maintenant l’idée de KDE à notre ensemble de données.
Pour chaque point de données, nous plaçons un courbe en forme de cloche centré sur sa valeur x. A ce stade, nous ne nous soucions pas encore de la classification. Nous ne faisons qu’une chose simple : créer une cloche locale autour de chaque point.
Cette cloche a une forme gaussienne, mais elle porte ici un nom précis : FBRpour Fonction de base radiale.
Sur cette figure, on peut voir le Noyau RBF (gaussien) centré sur ce point x₇

Le nom semble technique, mais l’idée est en réalité très simple.
Une fois que vous considérez les RBF comme des « cloches basées sur la distance », le nom cesse d’être mystérieux.
Comment lire ceci intuitivement
- x est n’importe quelle position sur l’axe des x
- x₇ est le centre de la cloche (le 7ème point)
- γ (gamma) contrôle la largeur de la cloche
La cloche atteint donc son maximum exactement à ce moment-là.
À mesure que x s’éloigne de x₇, la valeur diminue progressivement vers 0.
Rôle de γ (gamma)
- Petit γ signifie cloche large (influence douce et globale)
- Grand γ signifie cloche étroite (influence très locale)
Donc γ joue le même rôle que bande passante dans KDE.
A ce stade, rien n’est encore combiné. Nous construisons simplement les blocs élémentaires.
2.3. Combiner des cloches avec des étiquettes de classe
Sur les figures ci-dessous, vous voyez d’abord les cloches individuelles, chacune centrée sur un point de données.
Une fois que cela est clair, nous passons à l’étape suivante : combiner les cloches.
Cette fois, chaque cloche est multipliée par son étiquette yi.
En conséquence, certaines cloches sont ajoutées et d’autres sont soustraites, créant des influences dans deux directions opposées.
C’est la première étape vers une fonction de classification.

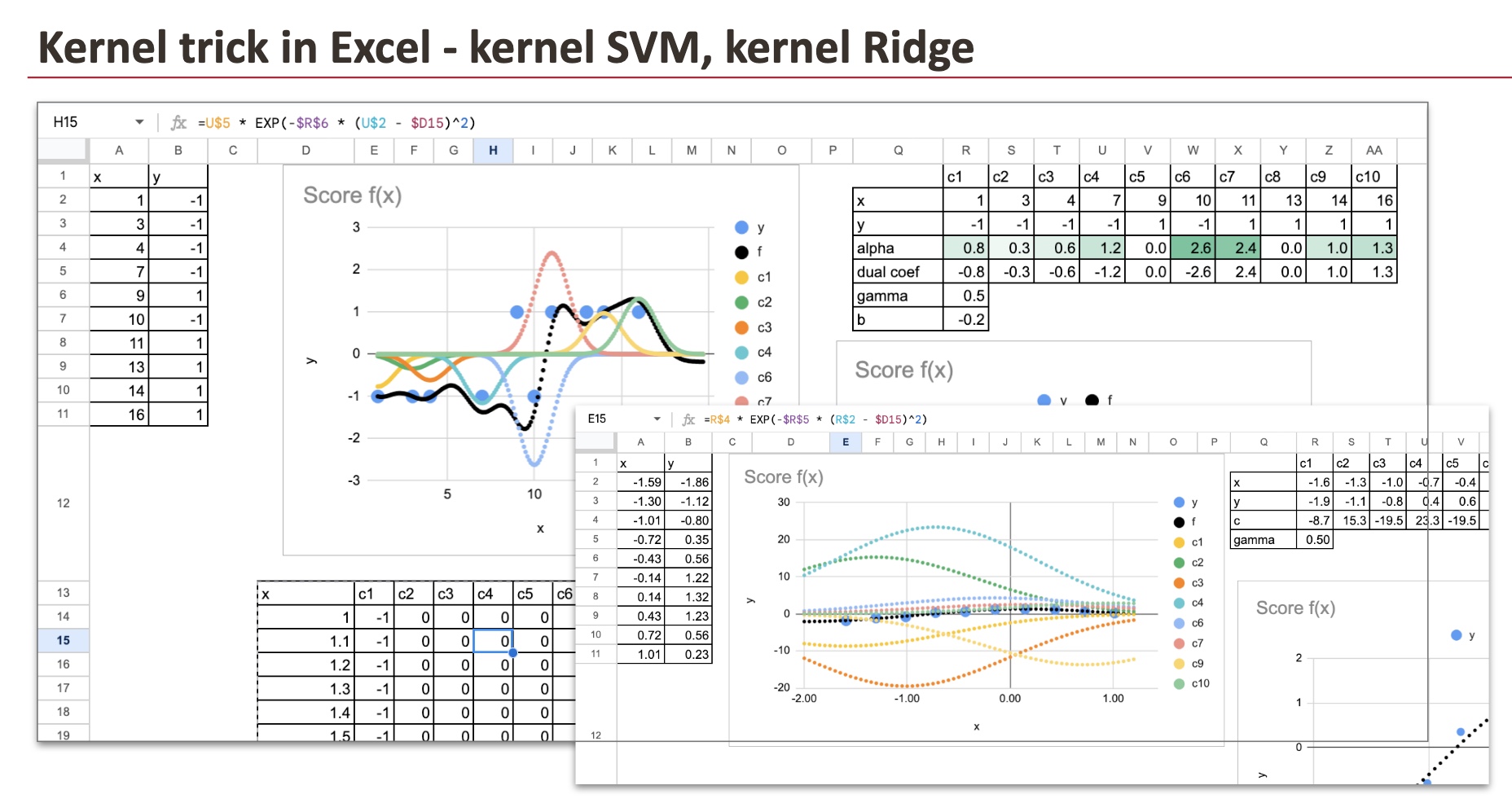
Et nous pouvons voir tous les composants de chaque point de données qui s’additionnent dans Excel pour obtenir le score final.

Cela ressemble déjà extrêmement à KDE.
Mais nous n’avons pas encore fini.
2.4. Des cloches égales aux cloches pondérées
Nous avons dit plus haut que SVM appartient au groupe famille basée sur le poids de modèles. La prochaine étape naturelle consiste donc à introduire poids.
Dans les modèles basés sur la distance, une limitation majeure est que toutes les caractéristiques sont traitées comme étant d’égale importance lors du calcul des distances. Bien sûr, nous pouvons redimensionner les fonctionnalités, mais il s’agit souvent d’une solution manuelle et imparfaite.
Ici, nous adoptons une approche différente.
Au lieu de simplement additionner toutes les cloches, nous attribuer un poids à chaque point de données et multipliez chaque cloche par ce poids.

À ce stade, le modèle est toujours linéairemais linéaire dans le espace des noyauxpas dans l’espace d’entrée d’origine.
Pour rendre cela concret, on peut supposer que les coefficients αi sont déjà connus et tracer directement la fonction résultante dans Excel. Chaque point de données apporte sa propre cloche pondérée, et le score final n’est que la somme de toutes ces contributions.

Si nous appliquons cela à un ensemble de données avec une frontière non linéairement séparable, nous voyons clairement ce que fait Kernel SVM : il s’adapte aux données en combinant les influences locales, au lieu d’essayer de tracer une seule ligne droite.

3. Fonction de perte : là où commence réellement le SVM
Jusqu’à présent, nous n’avons parlé que du noyau partie du modèle. Nous avons construit des cloches, les avons pesées et combinées.
Mais notre modèle s’appelle SVM du noyaupas seulement un « modèle de noyau ».
Le Partie SVM vient du fonction de perte.
Et comme vous le savez peut-être déjà, SVM est défini par le perte de charnière.
3.1 Perte de charnière et vecteurs de support
La perte charnière possède une propriété très importante.
Si un point est :
- correctement classé, et
- suffisamment loin de la limite de décision,
alors sa perte est zéro.
En conséquence directe, son coefficient αi devient zéro.
Seuls quelques points de données restent actifs.
Ces points sont appelés vecteurs de soutien.
Donc même si nous avons commencé avec une cloche par point de donnéesdans le modèle final, seules quelques cloches survivent.
Dans l’exemple ci-dessous, vous pouvez voir que pour certains points (par exemple les points 5 et 8), le coefficient αi est nul. Ces points ne sont pas des vecteurs supports et ne contribuent pas à la fonction de décision.
Selon la force avec laquelle nous pénalisons les violations (via le paramètre C), le nombre de vecteurs de support peut augmenter ou diminuer.
Il s’agit d’un avantage pratique crucial du SVM.
Lorsque l’ensemble de données est volumineux, le stockage d’un paramètre par point de données peut s’avérer coûteux. Grâce à la perte de charnière, SVM produit un modèle clairseméoù seul un petit sous-ensemble de points est conservé.

3.2 Régression des crêtes de noyau : mêmes noyaux, pertes différentes
Si nous gardons les mêmes noyaux mais remplaçons la perte charnière par une perte au carré, nous obtenons régression de crête de noyau:
Mêmes noyaux.
Mêmes cloches.
Perte différente.
Cela nous amène à une conclusion très importante :
Les noyaux définissent la représentation.
La fonction de perte définit le modèle.
Avec la régression kernel ridge, le modèle doit stocker tous les points de données d’entraînement.
Étant donné que la perte au carré ne force aucun coefficient à zéro, chaque point de données conserve un poids non nul et contribue à la prédiction.
En revanche, Kernel SVM produit une solution clairsemée : seuls les vecteurs supports sont stockés, tous les autres points disparaissent du modèle.

3.3 Un lien rapide avec LASSO
Il existe un parallèle intéressant avec LASSO.
En régression linéaire, LASSO utilise un Pénalité de L1 sur les coefficients primaux. Cette pénalité encourage la parcimonie et certains coefficients deviennent exactement nuls.
En SVM, la perte de charnière joue un rôle similaire, mais dans un espace différent.
- LASSO crée de la rareté dans le coefficients primordiaux
- SVM crée une rareté dans le coefficients doubles ai
Différents mécanismes, même effet : seuls les paramètres importants survivent.
Conclusion
Kernel SVM ne concerne pas seulement les noyaux.
- Les noyaux créent une représentation riche et non linéaire.
- La perte de charnière sélectionne uniquement les points de données essentiels.
Le résultat est un modèle à la fois flexible et clairseméc’est pourquoi SVM reste un outil puissant et élégant.
Demain, nous examinerons un autre modèle qui traite de la non-linéarité. Restez à l’écoute.


