
Le « Calendrier de l’Avent » de Machine Learning Jour 12 : Régression logistique dans Excel
Le modèle d’aujourd’hui est la régression logistique.
Si vous connaissez déjà ce modèle, voici une question pour vous :
La régression logistique est-elle un régresseur ou un classificateur?
Eh bien, cette question est exactement la même : une tomate est-elle une fruit ou un légume?
Du point de vue d’un botaniste, une tomate est un fruit, car il s’intéresse à la structure : graines, fleurs, biologie végétale.
Du point de vue du cuisinier, une tomate est un légume, car il regarde le goût, la manière dont elle est utilisée dans une recette, qu’elle accompagne une salade ou un dessert.
Le même objet, deux réponses valables, car le point de vue est différent.
La régression logistique est exactement comme ça.
- Dans le Sstatistique / GLM point de vue, c’est une régression. Et de toute façon, il n’y a pas de notion de « classification » dans ce cadre. Il existe la régression gamma, la régression logistique, la régression de Poisson…
- Dans le apprentissage automatique perspective, il est utilisé pour la classification. C’est donc un classificateur.
Nous y reviendrons plus tard.
Pour l’instant, une chose est sûre :
La régression logistique est très bien adaptée lorsque le la variable cible est binaireet généralement y est codé comme 0 ou 1.
Mais…
Qu’est-ce qu’un classificateur pour un modèle basé sur le poids ?
Ainsi, y peut valoir 0 ou 1.
0 ou 1, ce sont des nombres, non ?
On peut donc simplement considérer y comme continu !
Oui, y = ax + b, avec y = 0 ou 1.
Pourquoi pas?
Maintenant, vous vous demandez peut-être : pourquoi cette question, maintenant ? Pourquoi cela n’a pas été demandé auparavant.
Eh bien, pour les modèles basés sur la distance et les arbres, un y catégorique est vraiment catégorique.
Quand y est catégorique, comme rouge, bleu, vertou simplement 0 et 1:
- Dans K-NNvous classez en regardant voisins de chaque classe.
- Dans modèles centroïdesvous comparez avec le centre de gravité de chaque classe.
- Dans un arbre de décisiontu calcules proportions de classe à chaque nœud.
Dans tous ces modèles :
Les étiquettes de classe ne sont pas des nombres.
Ce sont des catégories.
Les algorithmes ne les traitent jamais comme des valeurs.
La classification est donc naturelle et immédiate.
Mais pour les modèles basés sur le poids, les choses fonctionnent différemment.
Dans un modèle basé sur le poids, nous calculons toujours quelque chose comme :
y = hache + b
ou, plus tard, une fonction plus complexe avec des coefficients.
Cela signifie:
Le modèle fonctionne avec des chiffres partout.
Voici donc l’idée clé :
Si le modèle effectue une régression, alors ce même modèle peut être utilisé pour la classification binaire.
Oui, nous pouvons utiliser la régression linéaire pour la classification binaire !
Puisque les étiquettes binaires sont 0 et 1ils sont déjà numériques.
Et dans ce cas particulier : nous peut appliquer les moindres carrés ordinaires (OLS) directement sur y = 0 et y = 1.
Le modèle s’adaptera à une ligne et nous pouvons utiliser la même formule fermée, comme nous pouvons le voir ci-dessous.

On peut faire la même descente de pente, et cela fonctionnera parfaitement :

Et puis, pour obtenir la prédiction de classe finale, nous choisissons simplement un seuil.
Il s’agit généralement de 0,5 (ou 50 %), mais en fonction du degré de rigueur que vous souhaitez appliquer, vous pouvez choisir une autre valeur.
- Si y≥0,5 prédit, prédisez la classe 1
- Sinon, classe 0
Ceci est un classificateur.
Et comme le modèle produit une sortie numérique, nous pouvons même identifier le point où : y=0,5.
Cette valeur de x définit le frontière de décision.
Dans l’exemple précédent, cela se produit à x=9.
A ce seuil, on voyait déjà une erreur de classification.
Mais un problème apparaît dès qu’on introduit un point avec un grand valeur de x.
Par exemple, supposons que nous ajoutions un point avec : x= 50 et y = 1.
Parce que la régression linéaire tente de s’adapter à un ligne droite à travers toutes les données, cette seule grande valeur de x tire la ligne vers le haut.
La frontière de décision passe de x= à environ x=12.
Et maintenant, avec cette nouvelle frontière, nous nous retrouvons avec deux erreurs de classement.

Ceci illustre le problème principal :
Une régression linéaire utilisée comme classificateur est extrêmement sensible aux valeurs extrêmes de x. La frontière décisionnelle bouge considérablement et la classification devient instable.
C’est l’une des raisons pour lesquelles nous avons besoin d’un modèle qui ne se comporte pas éternellement de manière linéaire. Un modèle qui reste entre 0 et 1, même lorsque x devient très grand.
Et c’est exactement ce que va nous apporter la fonction logistique.
Comment fonctionne la régression logistique
On commence par : ax + b, tout comme la régression linéaire.
Ensuite, nous appliquons une fonction appelée sigmoïde ou fonction logistique.
Comme on peut le voir sur la capture d’écran ci-dessous, la valeur de p est alors comprise entre 0 et 1, c’est donc parfait.
p(x)est le probabilité prédite quey = 11 − p(x)est la probabilité prédite quey = 0
Pour la classification, on peut simplement dire :
- Si
p(x) ≥ 0.5prédire la classe1 - Sinon, prédisez la classe
0

De la probabilité à la perte de log
Désormais, la régression linéaire OLS tente de minimiser le MSE (Mean Squared Error).
La régression logistique pour une cible binaire utilise le Probabilité de Bernoulli. Pour chaque observation i:
- Si
yᵢ = 1la probabilité du point de données estpᵢ - Si
yᵢ = 0la probabilité du point de données est1 − pᵢ
Pour l’ensemble des données, la probabilité est le produit global i. En pratique, on prend le logarithme, qui transforme le produit en une somme.
Dans le Perspective GLMnous essayons de maximiser cette probabilité de journal.
Dans le point de vue de l’apprentissage automatiquenous définissons le perte comme le négatif enregistrer la vraisemblance et nous minimiser il. Cela donne l’habituel perte de journal.
Et c’est équivalent. Nous ne ferons pas la démonstration ici

Descente de gradient pour la régression logistique
Principe
Tout comme nous l’avons fait pour la régression linéaire, nous pouvons également utiliser Descente de dégradé ici. L’idée est toujours la même :
- Partons de quelques valeurs initiales de
aetb. - Calculez la perte et son pente (dérivés) en ce qui concerne
aetb. - Se déplacer
aetbun peu dans le sens où réduit la perte. - Répéter.
Rien de mystérieux.
C’est exactement le même processus mécanique qu’auparavant.
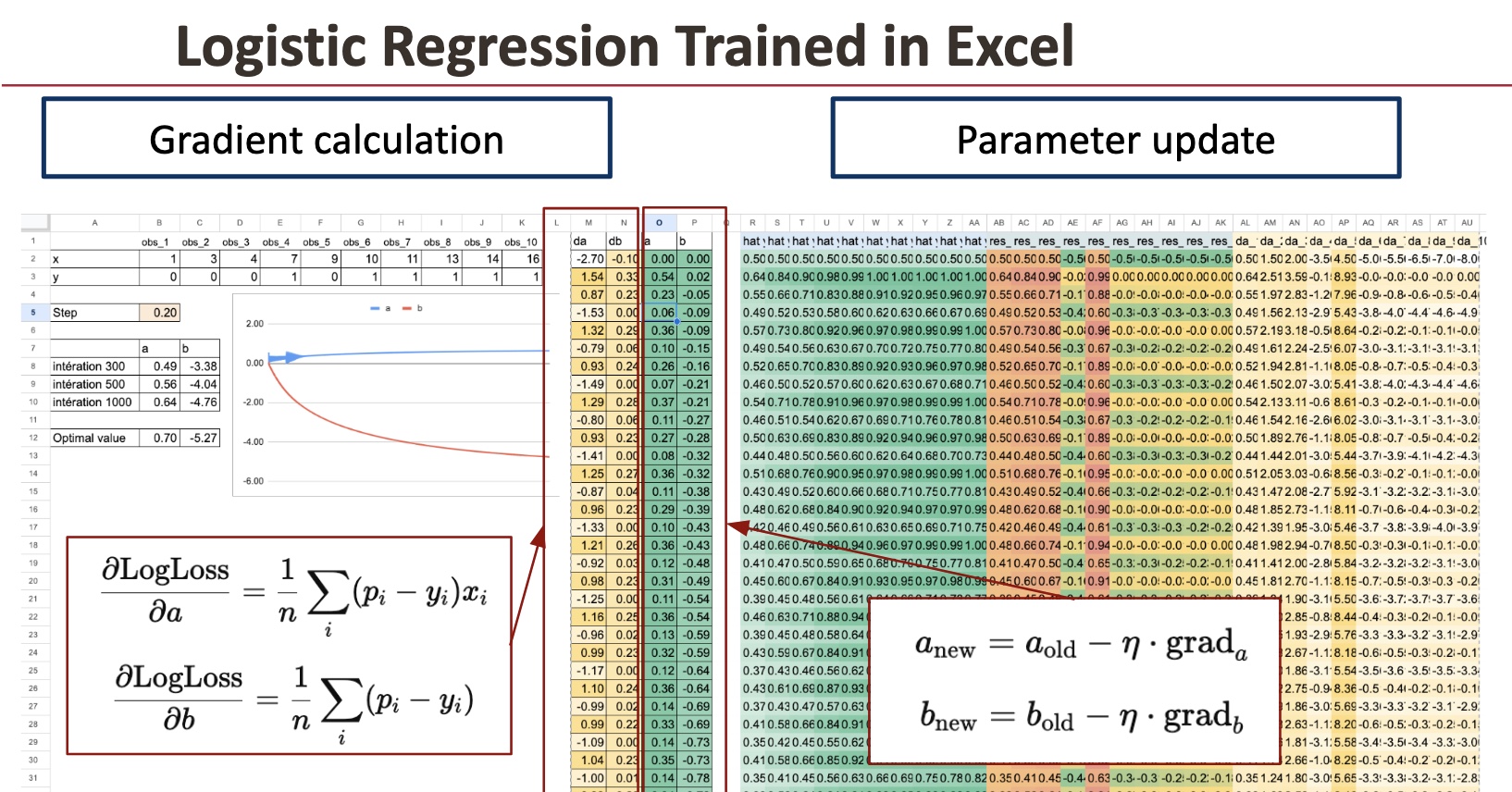
Étape 1. Calcul du dégradé
Pour la régression logistique, les gradients du perte de journal moyenne suivre une structure très simple.
C’est simplement le résiduel moyen.
Nous donnerons juste le résultat ci-dessous, pour la formule que l’on peut implémenter dans Excel. Comme vous pouvez le constater, c’est assez simple au final, même si la formule de log-perte peut être complexe à première vue.
Excel peut calculer ces deux quantités de manière simple SUMPRODUCT formules.

Étape 2. Mise à jour des paramètres
Une fois les gradients connus, nous mettons à jour les paramètres.
Cette étape de mise à jour est répétée à chaque itération.
Et itération après itération, la perte diminue et les paramètres convergent vers les valeurs optimales.

Nous avons désormais une vue d’ensemble.
Vous avez vu le modèle, la perte, les gradients et les mises à jour des paramètres.
Et avec la vue détaillée de chaque itération dans Excel, vous pouvez réellement jouer avec le modèle: changez une valeur, regardez la courbe évoluer et voyez la perte diminuer pas à pas.
Il est étonnamment satisfaisant d’observer à quel point tout s’emboîte si clairement.

Qu’en est-il de la classification multiclasse ?
Pour les modèles basés sur la distance et basés sur les arbres :
Aucun problème du tout.
Ils gèrent naturellement plusieurs classes car ils n’interprètent jamais les étiquettes comme des nombres.
Mais pour les modèles basés sur le poids ?
Ici, nous rencontrons un problème.
Si on écrit des nombres pour la classe : 1, 2, 3, etc.
Ensuite le modèle interprétera ces chiffres comme valeurs numériques réelles.
Ce qui entraîne des problèmes :
- le modèle pense que la classe 3 est « plus grande » que la classe 1
- le point médian entre la classe 1 et la classe 3 est la classe 2
- les distances entre les classes prennent du sens
Mais rien de tout cela n’est vrai en matière de classification.
Donc:
Pour les modèles basés sur le poids, nous ne pouvons pas simplement utiliser y = 1, 2, 3 pour la classification multiclasse.
Cet encodage est incorrect.
Nous verrons plus tard comment résoudre ce problème.
Conclusion
À partir d’un simple ensemble de données binaires, nous avons vu comment un modèle basé sur la pondération peut agir comme un classificateur, pourquoi la régression linéaire atteint rapidement ses limites et comment la fonction logistique résout ces problèmes en maintenant les prédictions entre 0 et 1.
Ensuite, en exprimant le modèle par la vraisemblance et la perte logarithmique, nous avons obtenu une formulation à la fois mathématiquement solide et facile à mettre en œuvre.
Et une fois le tout placé dans Excel, tout le processus d’apprentissage devient visible : les probabilités, la perte, les gradients, les mises à jour, et enfin la convergence des paramètres.
Avec la table d’itération détaillée, vous pouvez réellement voir comment le modèle s’améliore étape par étape.
Vous pouvez modifier une valeur, ajuster le taux d’apprentissage ou ajouter un point et observer instantanément comment réagissent la courbe et la perte.
C’est là le véritable intérêt du machine learning dans une feuille de calcul : rien n’est caché et chaque calcul est transparent.
En construisant une régression logistique de cette manière, vous comprenez non seulement le modèle, mais aussi pourquoi il est formé.
Et cette intuition restera avec vous à mesure que nous passerons à des modèles plus avancés plus tard dans le calendrier de l’Avent.


