
Le « Calendrier de l’Avent » de Machine Learning Jour 10 : DBSCAN dans Excel
de mon « Calendrier de l’Avent » de Machine Learning. Je tiens à vous remercier pour votre soutien.
Je crée ces fichiers Google Sheet depuis des années. Ils ont évolué petit à petit. Mais quand vient le temps de les publier, il me faut toujours des heures pour tout réorganiser, nettoyer la mise en page et les rendre agréables à lire.
Aujourd’hui, nous passons à DBSCAN.
DBSCAN n’apprend pas un modèle paramétrique
Tout comme LOF, DBSCAN est pas un modèle paramétrique. Il n’y a pas de formule à stocker, pas de règles, pas de centroïdes et rien de compact à réutiliser plus tard.
Nous devons garder le ensemble de données complet car la structure de densité dépend de tous les points.
Son nom complet est Clustering spatial basé sur la densité d’applications avec bruit.
Mais attention : cette « densité » n’est pas une densité gaussienne.
C’est un basé sur le nombre notion de densité. Juste « combien de voisins habitent près de chez moi ».
Pourquoi DBSCAN est spécial
Comme son nom l’indique, DBSCAN fait deux choses en même temps:
- il trouve des clusters
- il marque les anomalies (les points qui n’appartiennent à aucun cluster)
C’est exactement pourquoi je présente les algorithmes dans cet ordre :
- k-moyens et GMM sont modèles de clustering. Ils génèrent un objet compact : centroïdes pour les k-moyennes, moyennes et variances pour GMM.
- Forêt d’isolement et LOF sont modèles de détection d’anomalies pures. Leur seul objectif est de trouver des points inhabituels.
- DBSCAN se trouve entre les deux. ça fait les deux clustering et détection d’anomaliesbasée uniquement sur la notion de densité de quartier.
Un petit ensemble de données pour garder les choses intuitives
Nous restons avec le même petit ensemble de données que nous avons utilisé pour LOF : 1, 2, 3, 7, 8, 12
Si vous regardez ces chiffres, vous voyez déjà deux groupes compacts :
un autour 1-2-3un autre autour 7-8et 12 vivre seul.
DBSCAN capture exactement cette intuition.
Résumé en 3 étapes
DBSCAN demande trois questions simples pour chaque point :
- Combien de voisins avez-vous dans un petit rayon (eps) ?
- Avez-vous suffisamment de voisins pour devenir un point central (minPts) ?
- Une fois que nous connaissons les points essentiels, à quel groupe connecté appartenez-vous ?
Voici le résumé de l’algorithme DBSCAN dans 3 étapes:

Commençons étape par étape.
DBSCAN en 3 étapes
Maintenant que nous comprenons la notion de densité et de quartiers, DBSCAN devient très facile à décrire.
Tout ce que fait l’algorithme s’intègre trois étapes simples.
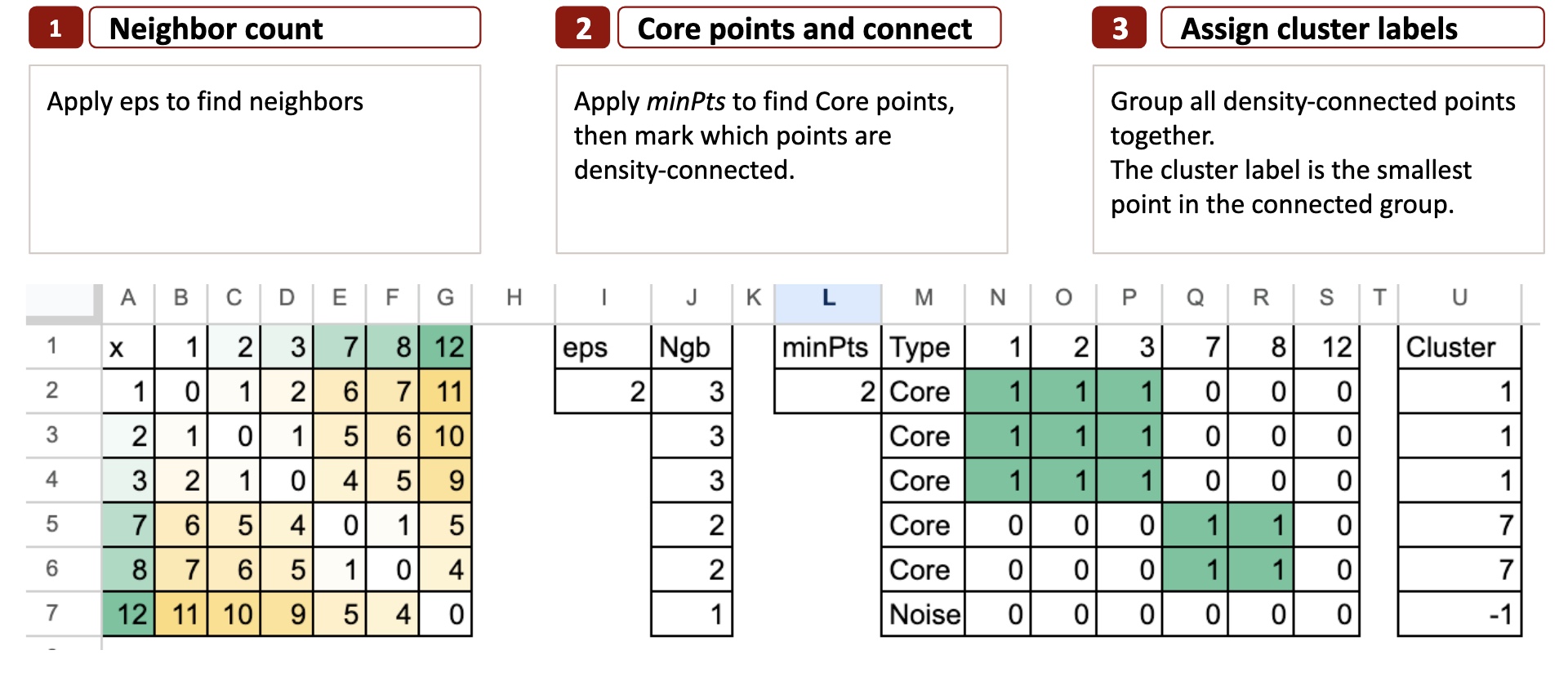
Étape 1 – Comptez les voisins
Le but est de vérifier combien de voisins possède chaque point.
On prend un petit rayon appelé eps.
Pour chaque point, nous regardons tous les autres points et marquons ceux dont la distance est inférieure à eps.
Ce sont les voisins.
Cela nous donne une première idée de densité :
un point avec de nombreux voisins se trouve dans une région dense,
un point avec peu de voisins vit dans une région clairsemée.
Pour un exemple de jouet unidimensionnel comme le nôtre, un choix courant est :
eps = 2
Nous dessinons un petit intervalle de rayon 2 autour de chaque point.
Pourquoi s’appelle-t-il eps?
Le nom eps vient de la lettre grecque ε (epsilon)qui est traditionnellement utilisé en mathématiques pour représenter un petite quantité ou un petit rayon autour d’un point.
Donc dans DBSCAN, eps est littéralement « le petit rayon du quartier ».
Il répond à la question :
Jusqu’où regardons-nous autour de chaque point ?
Ainsi, dans Excel, la première étape consiste à calculer le matrice de distance par pairepuis comptez le nombre de voisins que chaque point a dans eps.

Étape 2 – Points centraux et connectivité de densité
Maintenant que nous connaissons les voisins de l’étape 1, nous appliquons minPts pour décider quels points sont Cœur.
minPts signifie ici le nombre minimum de points.
C’est le plus petit nombre de voisins qu’un point doit avoir (à l’intérieur du rayon eps) pour être considéré comme un Cœur indiquer.
Un point est Core s’il possède au moins minPts voisins à l’intérieur eps.
Sinon, cela pourrait devenir Frontière ou Bruit.
Avec eps = 2 et minPts = 2nous en avons 12 qui ne sont pas Core.
Une fois les points Core connus, nous vérifions simplement quels points sont densité-atteignable d’eux. Si un point peut être atteint en passant d’un point Core à un autre au sein d’eps, il appartient au même groupe.
Dans Excel, nous pouvons représenter cela comme un simple tableau de connectivité qui montre quels points sont liés via les voisins principaux.
Cette connectivité est ce que DBSCAN utilise pour former des clusters à l’étape 3.

Étape 3 – Attribuer des étiquettes de cluster
L’objectif est de transformer la connectivité en véritables clusters.
Une fois la matrice de connectivité prête, les clusters apparaissent naturellement.
DBSCAN regroupe simplement tous les points connectés.
Pour donner à chaque groupe un nom simple et reproductible, nous utilisons une règle très intuitive :
L’étiquette du cluster est le plus petit point du groupe connecté.
Par exemple:
- Le groupe {1, 2, 3} devient un cluster 1
- Le groupe {7, 8} devient le cluster 7
- Un point comme 12 sans voisins principaux devient Bruit
C’est exactement ce que nous afficherons dans Excel à l’aide de formules.

Réflexions finales
DBSCAN est parfait pour enseigner la notion de densité locale.
Il n’y a aucune probabilité, aucune formule gaussienne, aucune étape d’estimation.
Juste des distances, des voisins et un petit rayon.
Mais cette simplicité le limite aussi.
Étant donné que DBSCAN utilise un rayon fixe pour tout le monde, il ne peut pas s’adapter lorsque l’ensemble de données contient des clusters d’échelles différentes.
HDBSCAN garde la même intuition, mais regarde tous rayons et maintient ce qui reste stable.
Il est beaucoup plus robuste et beaucoup plus proche de la façon dont les humains perçoivent naturellement les clusters.


