
Le « calendrier de l’Avent » d’apprentissage automatique Jour 6 : régresseur de l’arbre de décision
Pendant 5 jours de ce « Calendrier de l’Avent » de Machine Learning, nous avons exploré 5 modèles (ou algorithmes) tous basés sur des distances (distance euclidienne locale, ou distance globale de Mahalanobis).
Il est donc temps de changer d’approche, n’est-ce pas ? Nous reviendrons plus tard sur la notion de distance.
Pour aujourd’hui, nous verrons quelque chose de totalement différent : les arbres de décision !

Introduction avec un ensemble de données simple
Utilisons un ensemble de données simple avec une seule entité continue.
Comme toujours, l’idée est que vous puissiez visualiser vous-même les résultats. Ensuite, vous devez réfléchir à la manière de faire en sorte que l’ordinateur le fasse.

On devine visuellement que pour le premier split, il y a deux valeurs possibles, l’une autour de 5,5 et l’autre autour de 12.
Maintenant la question est : laquelle choisir ?
C’est exactement ce que nous allons découvrir : comment déterminer la valeur du premier fractionnement avec une implémentation dans Excel ?
Une fois que nous avons déterminé la valeur du premier fractionnement, nous pouvons appliquer le même processus pour les fractionnements suivants.
C’est pourquoi nous n’implémenterons que la première division dans Excel.
Le principe algorithmique des régresseurs d’arbre de décision
j’ai écrit un article pour toujours distinguer trois étapes du machine learning pour l’apprendre efficacementet appliquons le principe aux régresseurs d’arbre de décision.
Ainsi, pour la première fois, nous disposons d’un « véritable » modèle d’apprentissage automatique, avec des étapes non triviales pour les trois.
Quel est le modèle ?
Le modèle ici est un ensemble de règles, pour partitionner l’ensemble de données, et pour chaque partition, nous allons attribuer une valeur. Lequel? La valeur moyenne y de toutes les observations du même groupe.
Ainsi, alors que k-NN prédit avec la valeur moyenne des voisins les plus proches (observations similaires en termes de variables de caractéristiques), le régresseur de l’arbre de décision prédit avec la valeur moyenne d’un groupe d’observations (similaires en termes de variable de caractéristiques).
Processus d’ajustement ou de formation du modèle
Pour un arbre de décision, nous appelons également ce processus la croissance complète d’un arbre. Dans le cas d’un régresseur d’arbre de décision, les feuilles ne contiendront qu’une seule observation, avec donc un MSE de zéro.
Faire croître un arbre consiste à partitionner de manière récursive les données d’entrée en morceaux ou régions de plus en plus petits. Pour chaque région, une prédiction peut être calculée.
Dans le cas d’une régression, la prédiction est la moyenne de la variable cible pour la région.
À chaque étape du processus de construction, l’algorithme sélectionne la caractéristique et la valeur divisée qui maximisent le critère, et dans le cas d’un régresseur, il s’agit souvent de l’erreur quadratique moyenne (MSE) entre la valeur réelle et la prédiction.
Ajustement ou élagage du modèle
Pour un arbre de décision, le terme général de réglage du modèle est également appelé élagage, car cela peut être considéré comme la suppression de nœuds et de feuilles d’un arbre adulte.
Cela équivaut également à dire que le processus de construction s’arrête lorsqu’un critère est rempli, comme une profondeur maximale ou un nombre minimum d’échantillons dans chaque nœud feuille. Et ce sont les hyperparamètres qui peuvent être optimisés grâce au processus de réglage.
Processus d’inférence
Une fois le régresseur d’arbre de décision construit, il peut être utilisé pour prédire la variable cible pour les nouvelles instances d’entrée en appliquant les règles et en parcourant l’arbre du nœud racine à un nœud feuille qui correspond aux valeurs des caractéristiques de l’entrée.
La valeur cible prédite pour l’instance d’entrée est alors la moyenne des valeurs cibles des échantillons d’apprentissage qui tombent dans le même nœud feuille.
Divisé avec une seule fonctionnalité continue
Voici les étapes que nous suivrons :
- Répertoriez toutes les divisions possibles
- Pour chaque fractionnement, nous calculerons le MSE (Mean Squared Error)
- Nous sélectionnerons la division qui minimise le MSE comme prochaine division optimale
Toutes les divisions possibles
Tout d’abord, nous devons lister toutes les divisions possibles qui sont les valeurs moyennes de deux valeurs consécutives. Il n’est pas nécessaire de tester davantage de valeurs.

Calcul MSE pour chaque division possible
Comme point de départ, nous pouvons calculer le MSE avant toute scission. Cela signifie également que la prédiction correspond uniquement à la valeur moyenne de y. Et le MSE équivaut à l’écart type de y.
Maintenant, l’idée est de trouver une répartition afin que le MSE avec une répartition soit plus faible qu’auparavant. Il est possible que la division n’améliore pas significativement les performances (ou ne diminue pas le MSE), alors l’arbre final serait trivial, c’est-à-dire la valeur moyenne de y.
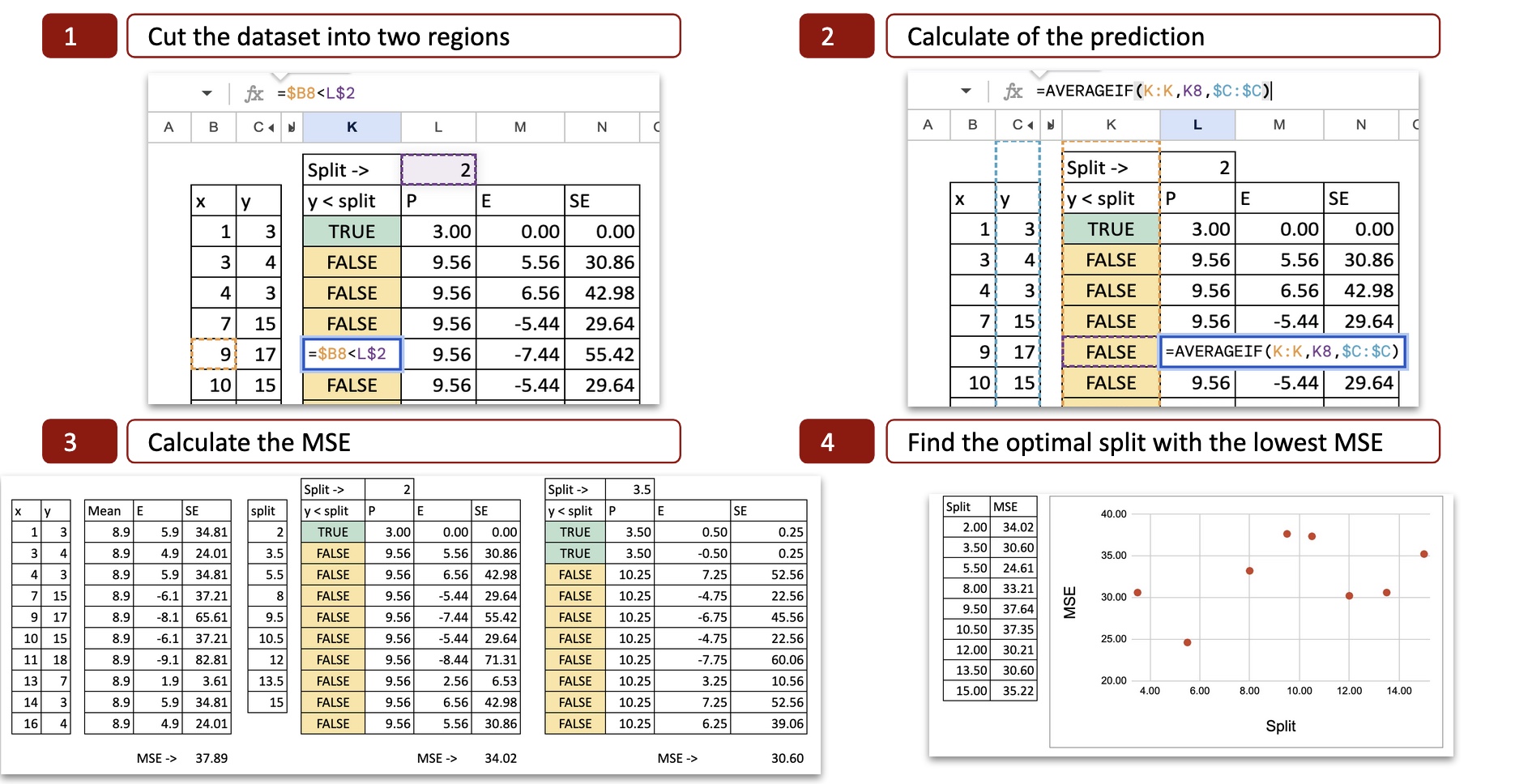
Pour chaque répartition possible, on peut alors calculer le MSE (Mean Squared Error). L’image ci-dessous montre le calcul de la première division possible, qui est x = 2.

On peut voir le détail du calcul :
- Coupez l’ensemble de données en deux régions : avec la valeur x=2, nous déterminons deux possibilités x<2 ou x>2, donc l’axe des x est coupé en deux parties.
- Calculez la prédiction : pour chaque partie, on calcule la moyenne de y. C’est la prédiction potentielle pour y.
- Calculer l’erreur : nous comparons ensuite la prédiction à la valeur réelle de y
- Calculer l’erreur quadratique : pour chaque observation, on peut calculer l’erreur quadratique.

Répartition optimale
Pour chaque répartition possible, on fait de même pour obtenir le MSE. Dans Excel, nous pouvons copier et coller la formule et la seule valeur qui change est la valeur de division possible pour x.

Ensuite, nous pouvons tracer le MSE sur l’axe des y et la division possible sur l’axe des x, et maintenant nous pouvons voir qu’il y a un minimum de MSE pour x=5,5, c’est exactement le résultat obtenu avec le code python.

Maintenant, un petit exercice que vous pouvez faire est de changer le MSE en MAE (Mean Absolute Error).
Et vous pouvez tenter de répondre à cette question : quel est l’impact de ce changement ?
Condensation de tous les calculs fractionnés en un seul tableau récapitulatif
Dans les sections précédentes, nous avons calculé chaque fractionnement étape par étape, afin de mieux visualiser les détails des calculs.
Désormais, nous rassemblons tout dans un seul tableau, de sorte que l’ensemble du processus devient compact et facile à automatiser.
Pour ce faire, nous simplifions d’abord les calculs.
Dans un nœud, la prédiction est la moyenne, donc le MSE est exactement la variance. Et pour la variance, on peut aussi utiliser la formule simplifiée :

Ainsi, dans le tableau suivant, nous utilisons une ligne pour chaque division possible.
Pour chaque division, nous calculons le MSE du nœud gauche et le MSE du nœud droit.
La variance de chaque groupe peut être simplifiée en utilisant les résultats intermédiaires de y et y au carré.
Ensuite, nous calculons la moyenne pondérée des deux valeurs MSE. Et au final, on obtient exactement le même résultat que dans la méthode pas à pas.

Divisé avec plusieurs fonctionnalités continues
Nous allons maintenant utiliser deux fonctionnalités.
C’est là que ça devient intéressant.
Nous aurons des divisions de candidats venant de les deux caractéristiques.
Comment choisissons-nous ?
Nous considérerons simplement tous d’entre eux, puis sélectionnez la division avec le le plus petit MSE.
L’idée dans Excel est la suivante :
- Tout d’abord, placez toutes les séparations possibles des deux fonctionnalités dans une seule colonne,
- puis, pour chacune de ces répartitions, calculez le MSE comme précédemment,
- enfin, choisissez le meilleur.
Divise la concaténation
Tout d’abord, nous énumérons toutes les divisions possibles pour la fonctionnalité 1 (par exemple, tous les seuils entre deux valeurs triées).
Ensuite, nous listons toutes les divisions possibles pour la fonctionnalité 2 de la même façon.
Dans Excel, nous concaténons ces deux listes en une colonne des divisions des candidats.
Ainsi, chaque ligne de cette colonne représente :
- « Si je coupe ici, en utilisant cette fonctionnalité, qu’arrive-t-il au MSE ? »
Cela nous donne une liste unifiée de toutes les séparations des deux fonctionnalités.

Calculs MSE
Une fois qu’on a la liste de tous les splits, la suite est dans la même logique qu’avant.
Pour chaque ligne (c’est-à-dire pour chaque fractionnement) :
- nous divisons les points en nœud gauche et nœud droit,
- nous calculons le MSE du nœud gauche,
- nous calculons le MSE du nœud droit,
- nous prenons le moyenne pondérée des deux valeurs MSE.
A la fin, on regarde cette colonne de « Total MSE » et on choisit le split (et donc la caractéristique et le seuil) qui donne le minimum valeur.

Divisé avec une fonctionnalité continue et une fonctionnalité catégorielle
Combinons maintenant deux types de fonctionnalités très différents :
- un continu fonctionnalité
- un catégorique fonctionnalité (par exemple, A, B, C).
Un arbre de décision peut se diviser en les deuxmais la façon dont nous générons les répartitions des candidats n’est pas la même.
Avec une fonctionnalité continue, nous testons seuils.
Avec une fonctionnalité catégorielle, nous testons groupes de catégories.
L’idée est donc exactement la même que précédemment :
nous considérons toutes les divisions possibles des deux fonctionnalités, puis nous sélectionnons celle avec le le plus petit MSE.
Divisions de fonctionnalités catégorielles
Pour une caractéristique catégorielle, la logique est différente :
- chaque catégorie est déjà un « groupe »,
- donc la répartition la plus simple est : une catégorie contre toutes les autres.
Par exemple, si les catégories sont A, B et C :
- division 1 : A contre (B, C)
- division 2 : B contre (A, C)
- division 3 : C contre (A, B)
Cela donne déjà une répartition significative des candidats et permet de gérer les formules Excel.
Chacune de ces répartitions basées sur des catégories est ajoutée à la même liste qui contient les seuils continus.
Calcul du MSE
Une fois tous les fractionnements répertoriés (seuils continus + partitions catégorielles), les calculs suivent les mêmes étapes :
- attribuer chaque point au gauche ou droite nœud,
- calculer le MSE du nœud gauche,
- calculer le MSE du nœud droit,
- calculer le moyenne pondérée.
La rupture avec le MSE total le plus bas devient la première division optimale.

Exercice que vous pouvez essayer
Maintenant, vous pouvez jouer avec Google Sheet :
- Vous pouvez essayer de trouver la prochaine division
- Vous pouvez changer le critère, à la place de MSE, vous pouvez utiliser l’erreur absolue, Poisson ou friedman_mse comme indiqué dans la documentation de DécisionTreeRegressor
- Vous pouvez changer la variable cible en variable binaire, normalement, cela devient une tâche de classification, mais 0 ou 1 sont aussi des nombres donc le critère MSE peut toujours être appliqué. Mais si vous souhaitez créer un bon classificateur, vous devez appliquer le critère habituel Entroy ou Gini. C’est pour le prochain article.
Conclusion
À l’aide d’Excel, il est possible d’implémenter une division pour obtenir plus d’informations sur le fonctionnement des régresseurs d’arbre de décision. Même si nous n’avons pas créé d’arbre complet, cela reste intéressant, car le plus important est de trouver la répartition optimale parmi toutes les répartitions possibles.
Encore une chose à propos des valeurs manquantes
Avez-vous remarqué quelque chose d’intéressant dans la façon dont les fonctionnalités sont gérées entre les modèles basés sur la distance et les arbres de décision ?
Pour les modèles basés sur la distance, tout doit être numérique. Les caractéristiques continues restent continues et les caractéristiques catégorielles doivent être transformées en nombres. Le modèle compare des points dans l’espace, donc tout doit vivre sur un axe numérique.
Les arbres de décision font l’inverse : ils couper fonctionnalités en groupes. Une caractéristique continue devient des intervalles. Une caractéristique catégorielle reste catégorique.
Et une valeur manquante ? Cela devient simplement une autre catégorie. Il n’est pas nécessaire d’imputer au préalable. L’arbre peut naturellement le gérer en envoyant toutes les valeurs « manquantes » à une branche, comme n’importe quel autre groupe.


