
Le « Calendrier de l’Avent » d’apprentissage automatique Jour 20 : Régression linéaire optimisée par dégradé dans Excel
nous associons l’apprentissage au vote, au bagging et à Random Forest.
Le vote lui-même n’est qu’un mécanisme d’agrégation. Cela ne crée pas de diversité, mais combine les prédictions de modèles déjà différents.
L’ensachage, en revanche, crée explicitement de la diversité en entraînant le même modèle de base sur plusieurs versions bootstrapées de l’ensemble de données d’entraînement.
Random Forest étend le bagging en restreignant davantage l’ensemble des fonctionnalités prises en compte à chaque division.
D’un point de vue statistique, l’idée est simple et intuitive : la diversité se crée par le hasard, sans introduire de concept de modélisation fondamentalement nouveau.
Mais l’apprentissage collectif ne s’arrête pas là.
Il existe une autre famille de méthodes d’ensemble qui ne reposent pas du tout sur le hasard, mais sur optimisation. Le Gradient Boosting appartient à cette famille. Et pour vraiment le comprendre, nous partirons d’une idée volontairement étrange :
Nous appliquerons le gradient boosting à la régression linéaire.
Oui je sais. C’est probablement la première fois que vous entendez parler de l’application de la régression linéaire boostée par gradient.
(Nous verrons les arbres de décision boostés par gradient, demain).
Dans cet article, voici le plan :
- Tout d’abord, nous prendrons du recul et revisiterons les trois étapes fondamentales de l’apprentissage automatique.
- Ensuite, nous présenterons l’algorithme Gradient Boosting.
- Ensuite, nous appliquerons le Gradient Boosting à la régression linéaire.
- Enfin, nous réfléchirons à la relation entre Gradient Boosting et Gradient Descent.
1. Machine Learning en trois étapes
Pour faciliter l’apprentissage du machine learning, je le divise toujours en trois étapes claires. Appliquons ce cadre à la régression linéaire boostée par gradient.
Car contrairement à l’ensachage, chaque étape révèle quelque chose d’intéressant.

1. Modèle
Un modèle est quelque chose qui prend des caractéristiques en entrée et produit une prédiction en sortie.
Dans cet article, le modèle de base sera Régression linéaire.
1bis. Modèle de méthode d’ensemble
L’augmentation du dégradé est pas un modèle lui-même. Il s’agit d’une méthode d’ensemble qui regroupe plusieurs modèles de base en un seul méta-modèle. À lui seul, il ne mappe pas les entrées aux sorties. Il doit être appliqué à un modèle de base.
Ici, Gradient Boosting sera utilisé pour agréger des modèles de régression linéaire.
2. Montage du modèle
Chaque modèle de base doit être adapté aux données d’entraînement.
Pour la régression linéaire, l’ajustement signifie estimer les coefficients. Cela peut être fait numériquement en utilisant la descente de gradient, mais aussi analytiquement. Dans Google Sheets ou Excel, on peut utiliser directement le LINEST fonction pour estimer ces coefficients.
2 bis. Apprentissage du modèle d’ensemble
Au premier abord, le Gradient Boosting peut ressembler à une simple agrégation de modèles. Mais cela reste un processus d’apprentissage. Comme nous le verrons, il s’appuie sur une fonction de perte, exactement comme les modèles classiques qui apprennent les poids.
3. Réglage du modèle
Le réglage du modèle consiste à optimiser les hyperparamètres.
Dans notre cas, le modèle de base de régression linéaire lui-même n’a pas d’hyperparamètres (sauf si nous utilisons des variantes régularisées telles que Ridge ou Lasso).
Le Gradient Boosting introduit cependant deux hyperparamètres importants : le nombre d’étapes de boosting et le taux d’apprentissage. Nous verrons cela dans la section suivante.
En un mot, c’est l’apprentissage automatique, rendu facile, en trois étapes !
2. Algorithme de régresseur d’amplification de gradient
2.1 Principe de l’algorithme
Voici les principales étapes de l’algorithme Gradient Boosting, appliqué à la régression.
- Initialisation: On part d’un modèle très simple. Pour la régression, il s’agit généralement de la valeur moyenne de la variable cible.
- Calcul des erreurs résiduelles: Nous calculons les résidus, définis comme la différence entre les valeurs réelles et les prédictions actuelles.
- Ajustement de la régression linéaire aux résidus: Nous ajustons un nouveau modèle de base (ici, une régression linéaire) à ces résidus.
- Mettre à jour l’ensemble : Nous ajoutons ce nouveau modèle à l’ensemble, mis à l’échelle par un taux d’apprentissage (également appelé retrait).
- Répéter le processus: On répète les étapes 2 à 4 jusqu’à atteindre le nombre d’itérations de boosting souhaité ou jusqu’à ce que l’erreur converge.
C’est ça! Il s’agit de la procédure de base pour effectuer un gradient boosting appliqué à la régression linéaire.
2.2 Algorithme exprimé avec des formules
Maintenant que nous pouvons écrire les formules explicitement, cela permet de rendre chaque étape concrète.
Étape 1 – Initialisation
On part d’un modèle constant égal à la moyenne de la variable cible :
f0 = moyenne(y)
Étape 2 – Calcul résiduel
Nous calculons les résidus, définis comme la différence entre les valeurs réelles et les prédictions actuelles :
r1 = y − f0
Étape 3 – Ajuster un modèle de base aux résidus
Nous ajustons un modèle de régression linéaire à ces résidus :
r̂1 = a0 · x + b0
Étape 4 – Mettre à jour l’ensemble
Nous mettons à jour le modèle en ajoutant la régression ajustée, mise à l’échelle par le taux d’apprentissage :
f1 = f0 − taux_d’apprentissage · (a0 · x + b0)
Prochaine itération
Nous répétons la même procédure :
r2 = y − f1
r̂2 = a1 · x + b1
f2 = f1 − taux_d’apprentissage · (a1 · x + b1)
En développant cette expression, on obtient :
f2 = f0 − taux_d’apprentissage · (a0 · x + b0) − taux_d’apprentissage · (a1 · x + b1)
Le même processus se poursuit à chaque itération. Les résidus sont recalculés, un nouveau modèle est ajusté et l’ensemble est mis à jour en ajoutant ce modèle avec un taux d’apprentissage.
Cette formulation montre clairement que Gradient Boosting construit le modèle final comme une somme de modèles de correction successifs.
3. Régression linéaire renforcée par gradient
3.1 Formation du modèle de base
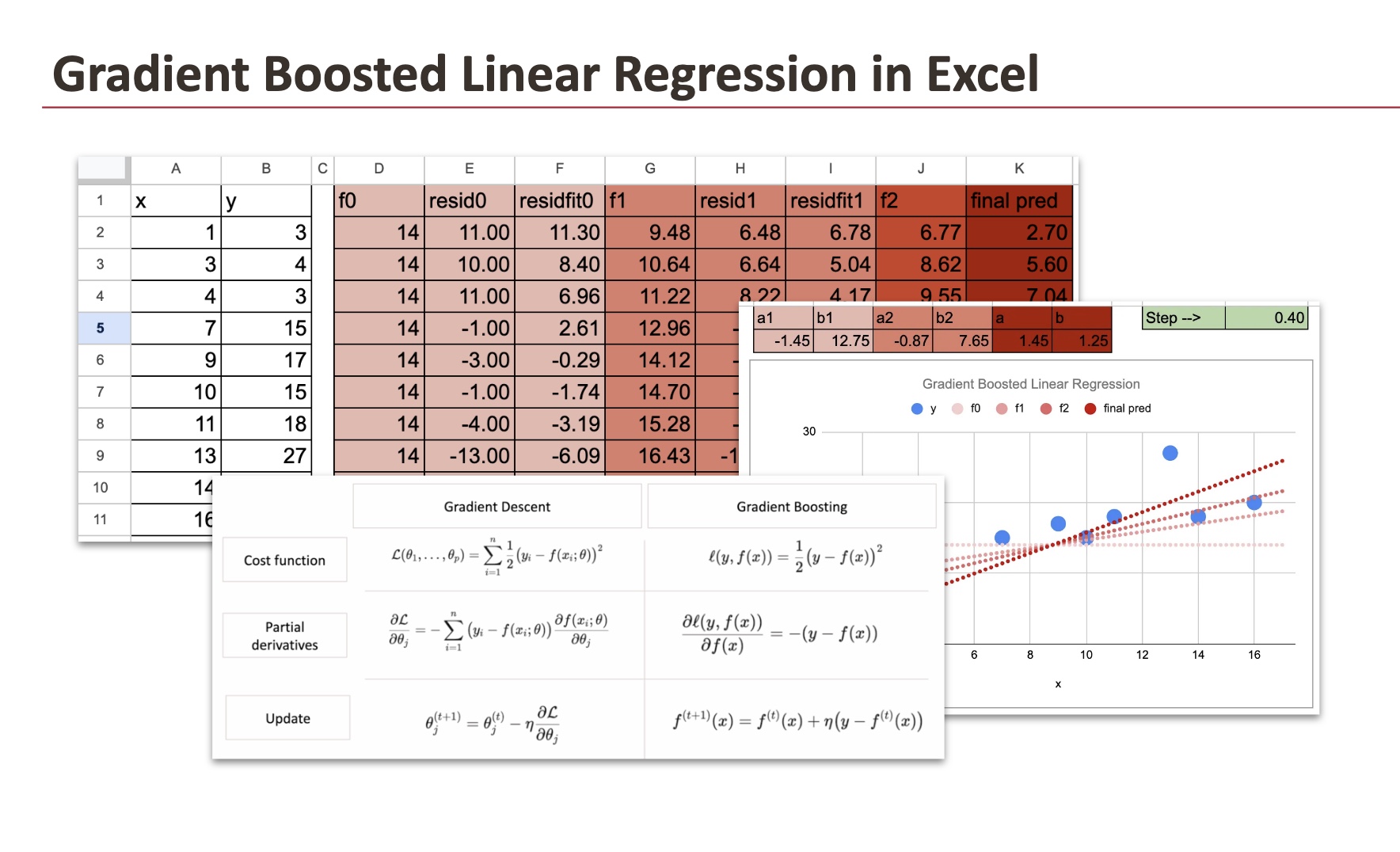
Nous commençons par une simple régression linéaire comme modèle de base, en utilisant un petit ensemble de données de dix observations que j’ai généré.
Pour l’ajustement du modèle de base, nous utiliserons une fonction dans Google Sheet (elle fonctionne aussi dans Excel) : LINEST pour estimer les coefficients de la régression linéaire.

3.2 Algorithme de boosting de gradient
La mise en œuvre de ces formules est simple dans Google Sheet ou Excel.
Le tableau ci-dessous montre l’ensemble de données d’entraînement ainsi que les différentes étapes des étapes d’amélioration du gradient :

Pour chaque étape d’ajustement, nous utilisons la fonction Excel LINEST :

Nous ne ferons que 2 itérations, et nous pouvons deviner comment cela se passe pour plus d’itérations. Voici ci-dessous un graphique pour montrer les modèles à chaque itération. Les différentes nuances de rouge illustrent la convergence du modèle et nous montrons également le modèle final que l’on trouve directement avec la descente de gradient appliquée directement à y.

3.3 Pourquoi stimuler la régression linéaire est purement pédagogique
Si vous examinez attentivement l’algorithme, deux observations importantes ressortent.
Tout d’abord, à l’étape 2, nous ajustons une régression linéaire aux résidus, il faudra du temps et des étapes algorithmiques pour réaliser les étapes d’ajustement du modèle, au lieu d’ajuster une régression linéaire aux résidus, nous pouvons directement ajuster une régression linéaire aux valeurs réelles de y, et nous trouverions déjà le modèle optimal final !
Deuxièmement, lorsqu’on ajoute une régression linéaire à une autre régression linéaire, il s’agit toujours d’une régression linéaire.
Par exemple, nous pouvons réécrire f2 comme suit :
f2 = f0 – taux_d’apprentissage *(b0+b1) – taux_d’apprentissage * (a0+a1) x
Il s’agit toujours d’une fonction linéaire de x.
Cela explique pourquoi la régression linéaire boostée par gradient n’apporte aucun avantage pratique. Sa valeur est purement pédagogique : elle nous aide à comprendre le fonctionnement de l’algorithme Gradient Boosting, mais elle n’améliore pas les performances prédictives.
En fait, c’est encore moins utile que le bagging appliqué à la régression linéaire. Avec le bagging, la variabilité entre les modèles bootstrapés nous permet d’estimer l’incertitude des prédictions et de construire des intervalles de confiance. La régression linéaire boostée par gradient, en revanche, se réduit à un modèle linéaire unique et ne fournit aucune information supplémentaire sur l’incertitude.
Comme nous le verrons demain, la situation est très différente lorsque le modèle de base est un arbre de décision.
3.4 Réglage des hyperparamètres
Il existe deux hyperparamètres que nous pouvons régler : le nombre d’itérations et le taux d’apprentissage.
Pour le nombre d’itérations, nous n’en avons implémenté que deux, mais il est facile d’en imaginer davantage, et on peut s’arrêter par examiner l’ampleur des résidus.
Pour le taux d’apprentissage, nous pouvons le modifier dans Google Sheet et voir ce qui se passe. Lorsque le taux d’apprentissage est faible, le « processus d’apprentissage » sera lent. Et si le taux d’apprentissage est de 1, on voit que la convergence est atteinte à l’itération 1.

Et les résidus de l’itération 1 sont déjà des zéros.

Si le taux d’apprentissage est supérieur à 1, alors le modèle divergera.

4. Boosting en tant que descente de gradient dans l’espace fonctionnel
4.1 Comparaison avec l’algorithme de descente de gradient
À première vue, le rôle du taux d’apprentissage et du nombre d’itérations dans Gradient Boosting ressemble beaucoup à ce que nous voyons dans Gradient Descent. Cela conduit naturellement à la confusion.
- Débutants remarquez souvent que les deux algorithmes contiennent le mot «pente » et suivent une procédure itérative. Il est donc tentant de supposer que Gradient Descent et Gradient Boosting sont étroitement liés, sans vraiment savoir pourquoi.
- Praticiens expérimentés réagissent généralement différemment. De leur point de vue, les deux méthodes semblent sans rapport. La descente de gradient est utilisée pour ajuster les modèles basés sur le poids en optimisant leurs paramètres, tandis que le gradient boosting est une méthode d’ensemble qui combine plusieurs modèles équipés des résidus. Les cas d’utilisation, les implémentations et l’intuition semblent complètement différents.
- À un niveau plus profondCependant, les experts diront que ces deux algorithmes sont en fait la même idée d’optimisation. La différence ne réside pas dans la règle d’apprentissage, mais dans l’espace où cette règle s’applique. Ou on peut dire que la variable d’intérêt est différente.
Gradient Descent effectue des mises à jour basées sur le dégradé dans espace de paramètres. Gradient Boosting effectue des mises à jour basées sur le dégradé dans espace fonctionnel.
C’est la seule différence dans cette optimisation numérique mathématique. Voyons les équations dans le cas de la régression et dans le cas général ci-dessous.
4.2 Le cas de l’erreur quadratique moyenne : même algorithme, espace différent
Avec l’erreur quadratique moyenne, la descente de gradient et l’augmentation du gradient minimisent le même objectif et sont pilotés par la même quantité : le résidu.
Dans Gradient Descent, les résidus influencent les mises à jour des paramètres du modèle.
Dans Gradient Boosting, les résidus mettent directement à jour la fonction de prédiction.
Dans les deux cas, le taux d’apprentissage et le nombre d’itérations jouent le même rôle. La différence réside uniquement dans l’endroit où la mise à jour est appliquée : espace des paramètres par rapport à l’espace des fonctions.
Une fois cette distinction claire, il devient évident que le Gradient Boosting avec MSE est simplement une Descente de Gradient exprimée au niveau des fonctions.

4.3 Gradient Boosting avec n’importe quelle fonction de perte
La comparaison ci-dessus ne se limite pas à l’erreur quadratique moyenne. La descente de gradient et l’augmentation de gradient peuvent être définies en fonction de différentes fonctions de perte.
Dans Gradient Descent, la perte est définie dans l’espace des paramètres. Cela nécessite que le modèle soit différenciable par rapport à ses paramètres, ce qui limite naturellement la méthode aux modèles basés sur le poids.
Dans Gradient Boosting, la perte est définie dans l’espace de prédiction. Seule la perte doit être différentiable par rapport aux prédictions. Le modèle de base lui-même n’a pas besoin d’être différentiable et, bien entendu, il n’a pas besoin d’avoir sa propre fonction de perte.
Cela explique pourquoi le Gradient Boosting peut combiner des fonctions de perte arbitraires avec des modèles non basés sur la pondération tels que les arbres de décision.

Conclusion
Le Gradient Boosting n’est pas seulement une technique d’ensemble naïve mais un algorithme d’optimisation. Il suit la même logique d’apprentissage que Gradient Descent, ne différant que par l’espace où l’optimisation est effectuée : paramètres versus fonctions. L’utilisation de la régression linéaire nous a permis d’isoler ce mécanisme dans sa forme la plus simple.
Dans le prochain article, nous verrons comment ce framework devient vraiment puissant lorsque le modèle de base est un arbre de décision, conduisant à des régresseurs d’arbre de décision boostés par gradient.
Tous les fichiers Excel sont disponibles via ce Lien Kofi. Votre soutien compte beaucoup pour moi. Le prix augmentera au cours du mois, afin que les premiers supporters bénéficient du meilleur rapport qualité-prix.



