
Le « Calendrier de l’Avent » d’apprentissage automatique Jour 2 : Classificateur k-NN dans Excel
le régresseur k-NN et l’idée de prédiction basée sur la distance, nous examinons maintenant le classificateur k-NN.
Le principe est le même, mais la classification nous permet d’introduire plusieurs variantes utiles, telles que le rayon le plus proche voisin, le centroïde le plus proche, la prédiction multiclasse et les modèles de distance probabilistes.
Nous allons donc d’abord implémenter le classificateur k-NN, puis discuter de la manière dont il peut être amélioré.
Vous pouvez utiliser cette feuille Excel/Google en lisant cet article pour mieux suivre toutes les explications.

Ensemble de données de survie du Titanic
Nous utiliserons l’ensemble de données de survie du Titanic, un exemple classique dans lequel chaque ligne décrit un passager avec des caractéristiques telles que la classe, le sexe, l’âge et le tarif, et l’objectif est de prédire si le passager a survécu.

Principe de k-NN pour la classification
Le classificateur k-NN est tellement similaire au régresseur k-NN que je pourrais presque écrire un seul article pour les expliquer tous les deux.
En fait, quand on cherche le k voisins les plus proches, nous n’utilisons pas la valeur oui du tout, et encore moins sa nature.
MAIS, il existe encore des faits intéressants sur la manière dont les classificateurs (binaires ou multi-classes) sont construits et sur la manière dont les fonctionnalités peuvent être gérées différemment.
Nous commençons par la tâche de classification binaire, puis par la classification multi-classes.
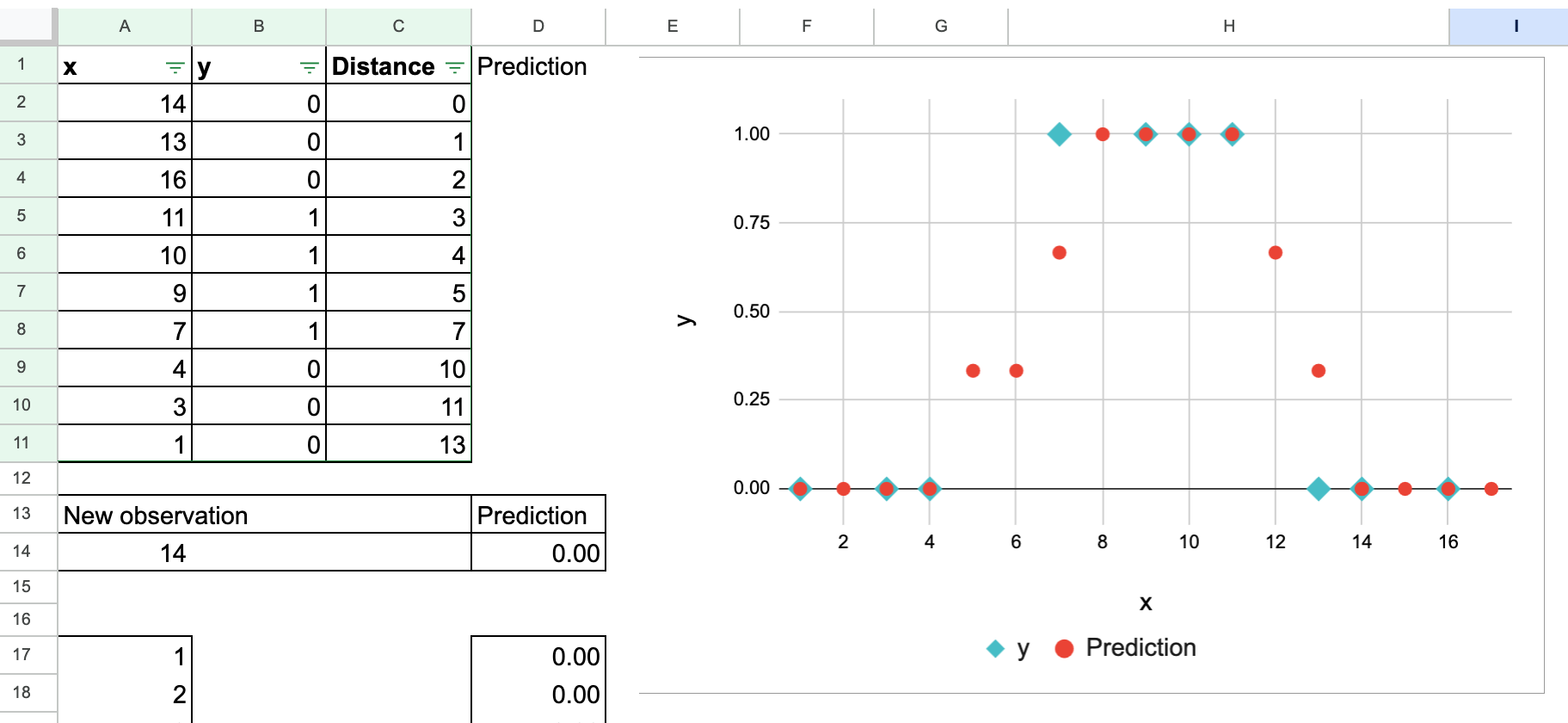
Une fonctionnalité continue pour la classification binaire
Donc, très rapidement, nous pouvons faire le même exercice pour une entité continue, avec cet ensemble de données.
Pour la valeur de y, on utilise généralement 0 et 1 pour distinguer les deux classes. Mais vous remarquerez peut-être, ou vous remarquerez que cela peut être source de confusion.

Maintenant, réfléchissez-y : 0 et 1 sont aussi des nombres, n’est-ce pas ? Ainsi, nous pouvons exactement faire le même processus que si nous faisions une régression.
C’est exact. Rien ne change dans le calcul, comme vous le voyez dans la capture d’écran suivante. Et vous pouvez bien entendu essayer de modifier vous-même la valeur de la nouvelle observation.

La seule différence réside dans la manière dont nous interprétons le résultat. Quand on prend la « moyenne » des voisins oui valeurs, ce nombre s’entend comme la probabilité que la nouvelle observation appartienne à la classe 1.
Donc en réalité, la valeur « moyenne » n’est pas la bonne interprétation, mais c’est plutôt la proportion de classe 1.
Nous pouvons également créer manuellement ce graphique pour montrer comment la probabilité prédite change sur une plage de x valeurs.
Traditionnellement, pour éviter de se retrouver avec une probabilité de 50 pour cent, on choisit une valeur impaire pour kafin que nous puissions toujours décider à la majorité.

Deux fonctionnalités pour la classification binaire
Si nous avons deux fonctionnalités, le fonctionnement est également presque le même que dans le régresseur k-NN.

Une fonctionnalité pour la classification multi-classe
Prenons maintenant un exemple de trois classes pour la variable cible y.
On voit alors qu’on ne peut plus utiliser la notion de « moyenne », puisque le nombre qui représente la catégorie n’est pas réellement un nombre. Et nous devrions plutôt les appeler « catégorie 0 », « catégorie 1 » et « catégorie 2 ».

De k-NN aux centroïdes les plus proches
Quand k devient trop grand
Maintenant, faisons en sorte que k soit grand. Quelle taille ? Aussi grand que possible.
N’oubliez pas que nous avons également fait cet exercice avec le régresseur k-NN, et la conclusion était que si k est égal au nombre total d’observations dans l’ensemble de données d’entraînement, alors le régresseur k-NN est l’estimateur simple de la valeur moyenne.
Pour le classificateur k-NN, c’est presque pareil. Si k est égal au nombre total d’observations, alors pour chaque classe, nous obtiendrons sa proportion globale dans l’ensemble de l’ensemble de données d’entraînement.
Certains, d’un point de vue bayésien, appellent ces proportions les a priori !
Mais cela ne nous aide pas beaucoup à classer une nouvelle observation, car ces a priori sont les mêmes pour chaque point.
La création des centroïdes
Alors faisons un pas de plus.
Pour chaque classe, on peut également regrouper toutes les valeurs de caractéristiques x qui appartiennent à cette classe et calculons leur moyenne.
Ces vecteurs de caractéristiques moyennés sont ce que nous appelons centroïdes.
Que pouvons-nous faire avec ces centroïdes ?
Nous pouvons les utiliser pour classer une nouvelle observation.
Au lieu de recalculer les distances par rapport à l’ensemble de données pour chaque nouveau point, nous mesurons simplement la distance par rapport à chaque centroïde de classe et attribuons la classe du plus proche.
Avec l’ensemble de données de survie du Titanic, nous pouvons commencer avec une seule fonctionnalité, âgeet calculez les centroïdes des deux classes : les passagers qui ont survécu et les passagers qui n’ont pas survécu.

Désormais, il est également possible d’utiliser plusieurs fonctionnalités continues.
Par exemple, nous pouvons utiliser les deux fonctionnalités âge et tarif.

Et nous pouvons discuter de quelques caractéristiques importantes de ce modèle :
- L’échelle est importante, comme nous l’avons vu précédemment pour le régresseur k-NN.
- Les valeurs manquantes ne sont pas un problème ici : lorsque l’on calcule les centroïdes par classe, chacun est calculé avec les valeurs disponibles (non vides)
- Nous sommes passés du modèle le plus « complexe » et le plus « grand » (dans le sens où le modèle réel est l’intégralité de l’ensemble de données d’entraînement, nous devons donc stocker tout l’ensemble de données) au modèle le plus simple (nous n’utilisons qu’une seule valeur par fonctionnalité, et nous stockons uniquement ces valeurs comme modèle)
De hautement non linéaire à naïvement linéaire
Mais maintenant, pouvez-vous penser à un inconvénient majeur ?
Alors que le classificateur k-NN de base est hautement non linéaire, la méthode du centroïde le plus proche est extrêmement linéaire.
Dans cet exemple 1D, les deux centroïdes sont simplement les valeurs x moyennes de la classe 0 et de la classe 1. Comme ces deux moyennes sont proches, la limite de décision devient simplement le point médian entre elles.
Ainsi, au lieu d’une limite irrégulière par morceaux qui dépend de l’emplacement exact de nombreux points d’entraînement (comme dans k-NN), nous obtenons une limite droite qui ne dépend que de deux nombres.
Cela illustre comment les centroïdes les plus proches compressent l’ensemble de données en une règle simple et très linéaire.

Une note sur la régression : pourquoi les centroïdes ne s’appliquent pas
Or, ce type d’amélioration n’est pas possible pour le régresseur k-NN. Pourquoi?
En classification, chaque classe forme un groupe d’observations, il est donc logique de calculer le vecteur caractéristique moyen pour chaque classe, ce qui nous donne les centroïdes de classe.
Mais en régression, la cible oui est continue. Il n’y a pas de groupes discrets, pas de frontières de classe, et donc aucun moyen significatif de calculer « le centroïde d’une classe ».
Une cible continue a une infinité de valeurs possibles, nous ne pouvons donc pas regrouper les observations selon leur valeur. oui valeur pour former des centroïdes.
Le seul « centroïde » possible en régression serait le moyenne globalece qui correspond au cas k = N dans le régresseur k-NN.
Et cet estimateur est beaucoup trop simple pour être utile.
En bref, le classificateur de centroïdes le plus proche est une amélioration naturelle pour la classification, mais il n’a pas d’équivalent direct en régression.
Autres améliorations statistiques
Que pouvons-nous faire d’autre avec le classificateur k-NN de base ?
Moyenne et variance
Avec le classificateur de centroïdes le plus proche, nous avons utilisé la statistique la plus simple qui est la moyenne. Un réflexe naturel en statistique est d’ajouter le variance aussi.
Ainsi, désormais, la distance n’est plus euclidienne, mais Mahalanobis distance. En utilisant cette distance, nous obtenons la probabilité basée sur la distribution caractérisée par la moyenne et la variance de chaque classe.
Gestion des caractéristiques catégorielles
Pour les caractéristiques catégorielles, nous ne pouvons pas calculer de moyennes ou de variances. Et pour le régresseur k-NN, nous avons vu qu’il était possible de faire un encodage one-hot ou un encodage ordinal/étiquette. Mais l’ampleur est importante et difficile à déterminer.
Ici, nous pouvons faire quelque chose de tout aussi significatif, en termes de probabilités : nous pouvons compter les proportions de chaque catégorie à l’intérieur d’une classe.
Ces proportions agissent exactement comme des probabilités, décrivant la probabilité que chaque catégorie se trouve au sein de chaque classe.
Cette idée est directement liée à des modèles tels que Bayes naïfs catégoriquesoù les classes sont caractérisées par distributions de fréquence au fil des catégories.
Distance pondérée
Une autre solution consiste à introduire des pondérations, de sorte que les voisins les plus proches comptent plus que les voisins éloignés. Dans scikit-learn, il y a l’argument « poids » qui nous permet de le faire.
Nous pouvons également passer de « k voisins » à un rayon fixe autour de la nouvelle observation, ce qui conduit à des classificateurs basés sur le rayon.
Rayon des voisins les plus proches
Parfois, nous pouvons trouver ce graphique suivant pour expliquer le classificateur k-NN. Mais en réalité, avec un rayon comme celui-ci, cela reflète davantage l’idée du rayon le plus proche voisin.
Un avantage est le contrôle du quartier. C’est particulièrement intéressant quand on connaît la signification concrète de la distance, comme la distance géographique.

Mais l’inconvénient est qu’il faut connaître le rayon à l’avance.
D’ailleurs, cette notion de rayon des plus proches voisins convient également à la régression.
Récapitulatif des différentes variantes
Tous ces petits changements donnent des modèles différents, chacun essayant d’améliorer l’idée de base de la comparaison des voisins selon une définition plus complexe de la distance, avec un paramètre de contrôle qui permet d’obtenir des voisins locaux, ou une caractérisation plus globale du voisinage.
Nous n’explorerons pas ici tous ces modèles. Je ne peux tout simplement pas m’empêcher d’aller un peu trop loin lorsqu’une petite variation mène naturellement à une autre idée.
Pour l’instant, considérez cela comme une annonce des modèles que nous mettrons en œuvre plus tard ce mois-ci.

Conclusion
Dans cet article, nous avons exploré le classificateur k-NN depuis sa forme la plus basique jusqu’à plusieurs extensions.
L’idée centrale n’est pas vraiment modifiée : une nouvelle observation est classée en regardant à quel point elle est similaire aux données d’entraînement.
Mais cette idée simple peut prendre de nombreuses formes différentes.
Avec des entités continues, la similarité est basée sur la distance géométrique.
Avec les caractéristiques catégorielles, nous examinons plutôt la fréquence à laquelle chaque catégorie apparaît parmi les voisins.
Lorsque k devient très grand, l’ensemble des données se réduit à quelques statistiques récapitulatives, ce qui conduit naturellement à Classificateur de centroïdes le plus proche.
Comprendre cette famille d’idées basées sur la distance et sur les probabilités nous aide à comprendre que de nombreux modèles d’apprentissage automatique sont simplement des manières différentes de répondre à la même question :
À quelle classe cette nouvelle observation ressemble-t-elle le plus ?
Dans les prochains articles, nous continuerons à explorer les modèles basés sur la densité, qui peuvent être compris comme des mesures globales de similarité entre observations et classes.


