Le « Calendrier de l’Avent » d’apprentissage automatique Jour 17 : Régresseur de réseau neuronal dans Excel
sont souvent présentés comme des boîtes noires.
Calques, activations, dégradés, rétropropagation… cela peut sembler écrasant, surtout lorsque tout est caché derrière model.fit().
Nous construirons un régresseur de réseau neuronal à partir de zéro en utilisant Excel. Chaque calcul sera explicite. Chaque valeur intermédiaire sera visible. Rien ne sera caché.
À la fin de cet article, vous comprendrez comment un réseau de neurones effectue une régression, comment fonctionne la propagation vers l’avant et comment le modèle peut approximer des fonctions non linéaires en utilisant seulement quelques paramètres.
Avant de commencer, si vous n’avez pas déjà lu mes articles précédents, vous devez d’abord vous pencher sur la mise en œuvre de la régression linéaire et de la régression logistique.
Vous verrez qu’un réseau de neurones n’est pas un objet nouveau. Il s’agit d’une extension naturelle de ces modèles.
Comme d’habitude, nous suivrons ces étapes :
- Tout d’abord, nous examinerons le fonctionnement du modèle de régresseur de réseau neuronal. Dans le cas des réseaux de neurones, cette étape est appelée propagation vers l’avant.
- Ensuite, nous entraînerons cette fonction en utilisant la descente de gradient. Ce processus est appelé rétropropagation.
1. Propagation vers l’avant
Dans cette partie, nous allons définir notre modèle, puis l’implémenter dans Excel pour voir comment fonctionne la prédiction.
1.1 Un ensemble de données simple
Nous utiliserons un ensemble de données très simple que j’ai généré. Il ne comprend que 12 observations et une seule fonctionnalité.
Comme vous pouvez le constater, la variable cible a une relation non linéaire avec x.
Et pour cet ensemble de données, nous utiliserons deux neurones dans la couche cachée.

1.2 Structure du réseau neuronal
Notre exemple de réseau neuronal a :
- Une couche d’entrée avec la fonctionnalité x comme entrée
- Une couche cachée avec deux neurones dans la couche cachée, et ces deux neurones vont nous permettre de créer une relation non linéaire
- La couche de sortie n’est qu’une régression linéaire
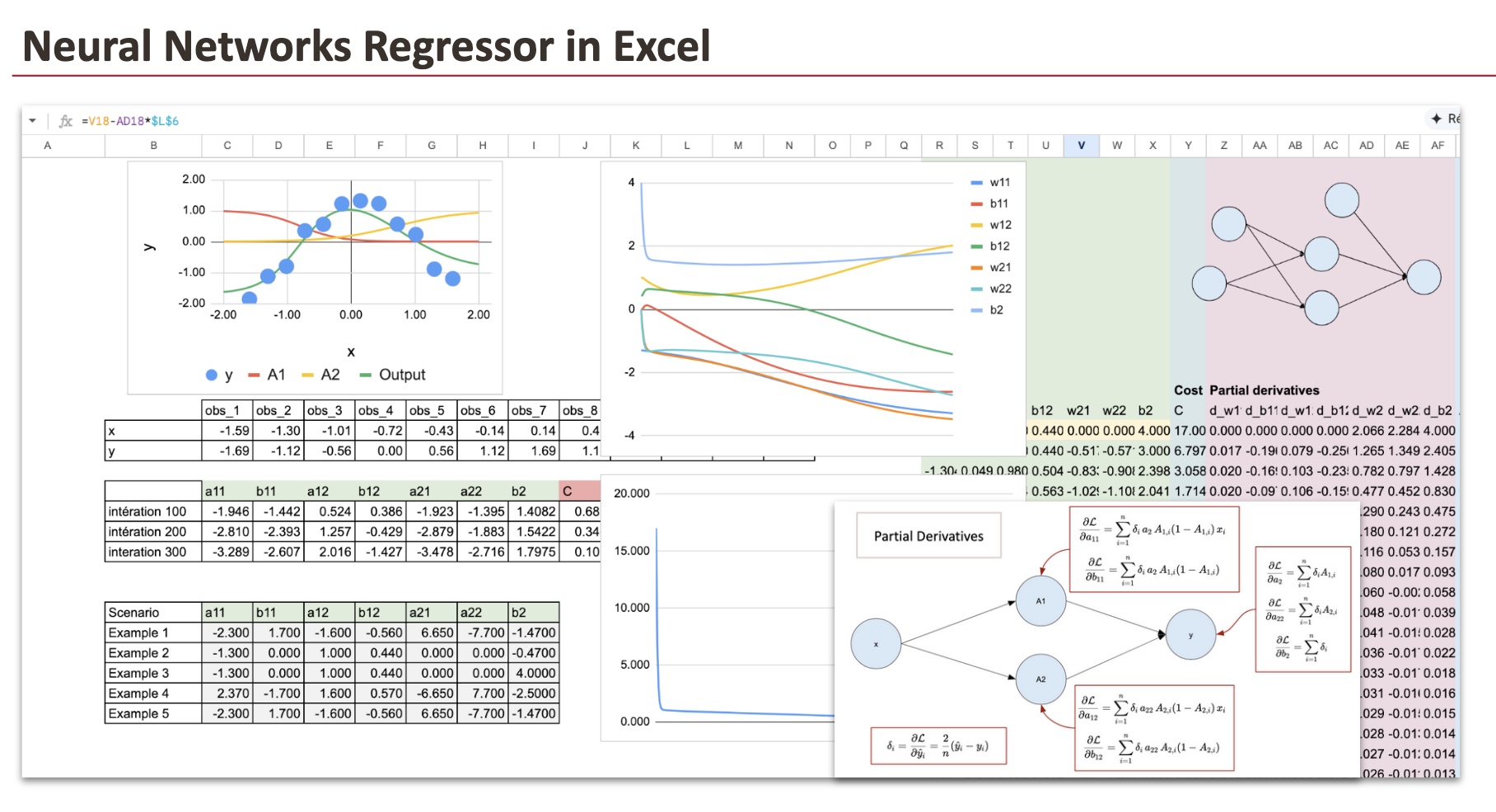
Voici le schéma qui représente ce réseau de neurones, ainsi que tous les paramètres qu’il faut estimer. Il y a un total de 7 paramètres.
Calque masqué :
- a11 : poids de x au neurone caché 1
- b11 : biais du neurone caché 1
- a12 : poids de x au neurone caché 2
- b12 : biais du neurone caché 2
Couche de sortie :
- a21 : poids du neurone caché 1 vers la sortie
- a22 : poids du neurone caché 2 vers la sortie
- b2 : biais de sortie
À la base, un réseau de neurones n’est qu’une fonction. Une fonction composée.
Si vous l’écrivez explicitement, cela n’a rien de mystérieux.

On représente généralement cette fonction par un diagramme constitué de « neurones ».
À mon avis, la meilleure façon d’interpréter ce diagramme est de représentation visuelle d’une fonction mathématique composéeet non comme une affirmation selon laquelle il reproduit littéralement le fonctionnement des neurones biologiques.

Pourquoi cette fonction fonctionne-t-elle ?
Chaque sigmoïde se comporte comme une marche douce.
Avec deux sigmoïdes, le modèle peut augmenter, diminuer, plier et aplatir la courbe de sortie.
En les combinant linéairement, le réseau peut se rapprocher de courbes non linéaires lisses.
C’est pourquoi pour cet ensemble de données, deux neurones suffisent déjà. Mais seriez-vous capable de trouver un ensemble de données pour lequel cette structure ne convient pas ?
1.3 Implémentation de la fonction dans Excel
Dans cette section, nous supposerons que les 7 coefficients sont déjà trouvés. Et nous pouvons alors mettre en œuvre la formule que nous avons vue juste avant.
Pour visualiser le réseau de neurones, on peut utiliser de nouvelles valeurs continues de x allant de -2 à 2 avec un pas de 0,02.
Voici la capture d’écran, et nous pouvons voir que la fonction finale correspond assez bien à la forme des données d’entrée.

2. Rétropropagation (descente de gradient)
À ce stade, le modèle est entièrement défini.
Puisqu’il s’agit d’un problème de régression, nous utiliserons le MSE (erreur quadratique moyenne), tout comme pour une régression linéaire.
Maintenant, nous devons trouver les 7 paramètres qui minimiser le MSE.
2.1 Détails de l’algorithme de rétropropagation
Le principe est simple. MAIS, comme il existe de nombreuses fonctions composées et de nombreux paramètres, il faut s’organiser avec les dérivées.
Je ne dériverai pas explicitement toutes les 7 dérivées partielles. Je vais juste donner les résultats.

Comme nous pouvons le voir, il existe le terme d’erreur. Donc, afin de mettre en œuvre l’ensemble du processus, nous devons suivre cette boucle :
- initialiser les poids,
- calculer la sortie (propagation vers l’avant),
- calculer l’erreur,
- calculer des gradients à l’aide de dérivées partielles,
- mettre à jour les poids,
- répéter jusqu’à convergence.
2.2 Initialisation
Commençons par mettre l’ensemble de données d’entrée sous forme de colonne, ce qui facilitera la mise en œuvre des formules dans Excel.

En théorie, on peut partir de valeurs aléatoires pour l’initialisation des valeurs des paramètres. Mais en pratique, le nombre d’itérations peut être important pour parvenir à une convergence complète. Et comme la fonction de coût n’est pas convexe, on peut se retrouver coincé dans un minimum local.
Il faut donc choisir « judicieusement » les valeurs initiales. Je vous en ai préparé. Vous pouvez apporter de petites modifications pour voir ce qui se passe.

2.3 Propagation vers l’avant
Dans les colonnes de AG à BP, nous effectuons la phase de propagation vers l’avant. Nous calculons d’abord A1 et A2, suivis du résultat. Ce sont les mêmes formules utilisées dans la première partie de la propagation vers l’avant.
Pour simplifier les calculs et les rendre plus gérables, nous effectuons les calculs pour chaque observation séparément. Cela signifie que nous avons 12 colonnes pour chaque couche cachée (A1 et A2) et la couche de sortie. Au lieu d’utiliser une formule de sommation, nous calculons les valeurs de chaque observation individuellement.
Pour faciliter le processus de boucle for pendant la phase de descente de gradient, nous organisons l’ensemble de données d’entraînement en colonnes, et nous pouvons ensuite étendre la formule dans Excel par ligne.

2.4 Erreurs et fonction Coût
Dans les colonnes BQ à CN, nous pouvons maintenant calculer les valeurs de la fonction de coût.

2.5 Dérivées partielles
Nous allons calculer 7 dérivées partielles correspondant aux poids de notre réseau de neurones. Pour chacune de ces dérivées partielles, nous devrons calculer les valeurs des 12 observations, ce qui donne un total de 84 colonnes. Cependant, nous avons fait des efforts pour simplifier ce processus en organisant la feuille avec un code couleur et des formules pour en faciliter l’utilisation.
Nous allons donc commencer par la couche de sortie, pour les paramètres : a21, a22 et b2. On les retrouve dans les colonnes de CO à DX.

Ensuite pour les paramètres a11 et a12, on peut les retrouver des colonnes DY à EV :

Et enfin, pour les paramètres de biais b11 et b12, nous utilisons les colonnes EW à FT.

Et pour conclure, nous additionnons toutes les dérivées partielles des 12 observations. Ces dégradés agrégés sont soigneusement disposés en colonnes Z à AF. Les mises à jour des paramètres sont ensuite effectuées en colonnes R à Xen utilisant ces valeurs.

2.6 Visualisation de la convergence
Pour mieux comprendre le processus d’entraînement, nous visualisons l’évolution des paramètres lors de la descente de gradient à l’aide d’un graphique. Dans le même temps, la diminution de la fonction de coût est suivie dans colonne Yrendant clairement visible la convergence du modèle.

Conclusion
Un régresseur de réseau neuronal n’est pas magique.
Il s’agit simplement d’une composition de fonctions élémentaires, contrôlées par un certain nombre de paramètres et entraînées par minimisation d’un objectif mathématique bien défini.
En construisant le modèle explicitement dans Excel, chaque étape devient visible. La propagation directe, le calcul des erreurs, les dérivées partielles et les mises à jour de paramètres ne sont plus des concepts abstraits, mais des calculs concrets que vous pouvez inspecter et modifier.
La mise en œuvre complète de notre réseau neuronal, de la propagation vers l’avant jusqu’à la rétropropagation, est désormais terminée. Vous êtes encouragé à expérimenter en modifiant l’ensemble de données, les valeurs initiales des paramètres ou le taux d’apprentissage, et à observer le comportement du modèle pendant la formation.
Grâce à cet exercice pratique, nous avons vu comment les gradients déterminent l’apprentissage, comment les paramètres sont mis à jour de manière itérative et comment un réseau neuronal se façonne progressivement pour s’adapter aux données. C’est exactement ce qui se passe dans les bibliothèques modernes d’apprentissage automatique, cachées derrière quelques lignes de code.
Une fois compris ainsi, les réseaux de neurones cessent d’être des boîtes noires.