
Le « Calendrier de l’Avent » d’apprentissage automatique Jour 14 : Régression Softmax dans Excel
Avec Logistic Regression, nous avons appris à classer en deux classes.
Maintenant, que se passe-t-il s’il y a plus de deux classes.
n est simplement l’extension multiclasse de cette idée. Et nous discuterons de ce modèle pour le jour 14 de mon « Calendrier de l’Avent » de Machine Learning (suivez ce lien pour obtenir toutes les informations sur l’approche et les fichiers que j’utilise).
Au lieu d’une partition, nous créons désormais une partition par classe. Au lieu d’une probabilité, nous appliquons la fonction Softmax pour produire des probabilités dont la somme est égale à 1.
Comprendre le modèle Softmax
Avant d’entraîner le modèle, comprenons d’abord quel est le modèle.
Softmax Regression ne concerne pas encore l’optimisation.
Il s’agit d’abord de comment les prédictions sont calculées.
Un petit ensemble de données avec 3 classes
Utilisons un petit ensemble de données avec une fonctionnalité x et trois classes.
Comme nous l’avons dit précédemment, la variable cible y devrait pas être traité comme numérique.
Il représente des catégories, pas des quantités.
Une façon courante de représenter cela est encodage à chaudoù chaque classe est représentée par son propre indicateur.
De ce point de vue, la régression Softmax peut être considérée comme trois régressions logistiques exécutées en parallèleun par classe.
Les petits ensembles de données sont idéaux pour l’apprentissage.
Vous pouvez voir chaque formule, chaque valeur et comment chaque partie du modèle contribue au résultat final.

Description du modèle
Alors, quel est le modèle exactement ?
Score par classe
En régression logistique, le score du modèle est une expression linéaire simple : score = a * x + b.
Softmax Regression fait exactement la même chose, mais un score par classe :
score_0 = a0 * x + b0
score_1 = a1 * x + b1
score_2 = a2 * x + b2
À ce stade, ces scores ne sont que des chiffres réels.
Ce ne sont pas encore des probabilités.
Transformer les scores en probabilités : l’étape Softmax
Softmax convertit les trois scores en trois probabilités. Chaque probabilité est positive et la somme des trois est égale à 1.
Le calcul est direct :
- Exponent chaque score
- Calculer la somme de toutes les exponentielles
- Divisez chaque exponentielle par cette somme
Cela nous donne p0, p1 et p2 pour chaque ligne.
Ces valeurs représentent la confiance du modèle pour chaque classe.
À ce stade, le modèle est entièrement défini.
Entraîner le modèle consistera simplement à ajuster les coefficients ak et bk pour que ces probabilités correspondent au mieux aux classes observées.

Visualisation du modèle Softmax
À ce stade, le modèle est entièrement défini.
Nous avons:
- un score linéaire par classe
- une étape Softmax qui transforme ces scores en probabilités
Entraîner le modèle consiste simplement à ajuster les coefficients aka_kak et bkb_kbk pour que ces probabilités correspondent au mieux aux classes observées.
Une fois les coefficients trouvés, nous pouvons visualiser le comportement du modèle.
Pour ce faire, nous prenons une plage de valeurs d’entrée, par exemple x de 0 à 7, et nous calculons : score0,score1,score2 et les probabilités correspondantes p0,p1,p2.
Le tracé de ces probabilités donne trois courbes lisses, une par classe.

Le résultat est très intuitif.
Pour de petites valeurs de x, la probabilité de classe 0 est élevée.
À mesure que x augmente, cette probabilité diminue, tandis que la probabilité d’appartenir à la classe 1 augmente.
Pour des valeurs de x plus élevées, la probabilité de classe 2 devient dominante.
Pour chaque valeur de x, les trois probabilités totalisent 1.
Le modèle ne prend pas de décisions brusques ; au lieu de cela, il exprime à quel point il est confiant dans chaque classe.
Ce graphique rend le comportement de Softmax Regression facile à comprendre.
- Vous pouvez voir comment le modèle passe en douceur d’une classe à l’autre
- Les limites de décision correspondent aux intersections entre les courbes de probabilité
- La logique du modèle devient visible et non abstraite
C’est l’un des principaux avantages de la création du modèle dans Excel :
vous ne faites pas que calculer des prédictions, vous pouvez voir comment le modèle pense.
Maintenant que le modèle est défini, nous avons besoin d’un moyen de évaluer à quel point c’est bonet une méthode pour améliorer ses coefficients.
Les deux étapes réutilisent des idées que nous avons déjà vues avec Logistic Regression.
Évaluation du modèle : perte d’entropie croisée
La régression Softmax utilise le même fonction de perte comme régression logistique.
Pour chaque point de données, nous examinons la probabilité attribuée au bonne classeet on prend le logarithme négatif :
perte = – log (p vraie classe)
Si le modèle attribue une probabilité élevée à la bonne classe, la perte est faible.
S’il attribue une faible probabilité, la perte devient importante.
Dans Excel, c’est très simple à mettre en œuvre.
Nous sélectionnons la probabilité correcte en fonction de la valeur de y et appliquons le logarithme :
perte = -LN( CHOISIR(y + 1, p0, p1, p2) )
Enfin, nous calculons le perte moyenne sur toutes les lignes.
Cette perte moyenne est la quantité que nous souhaitons minimiser.

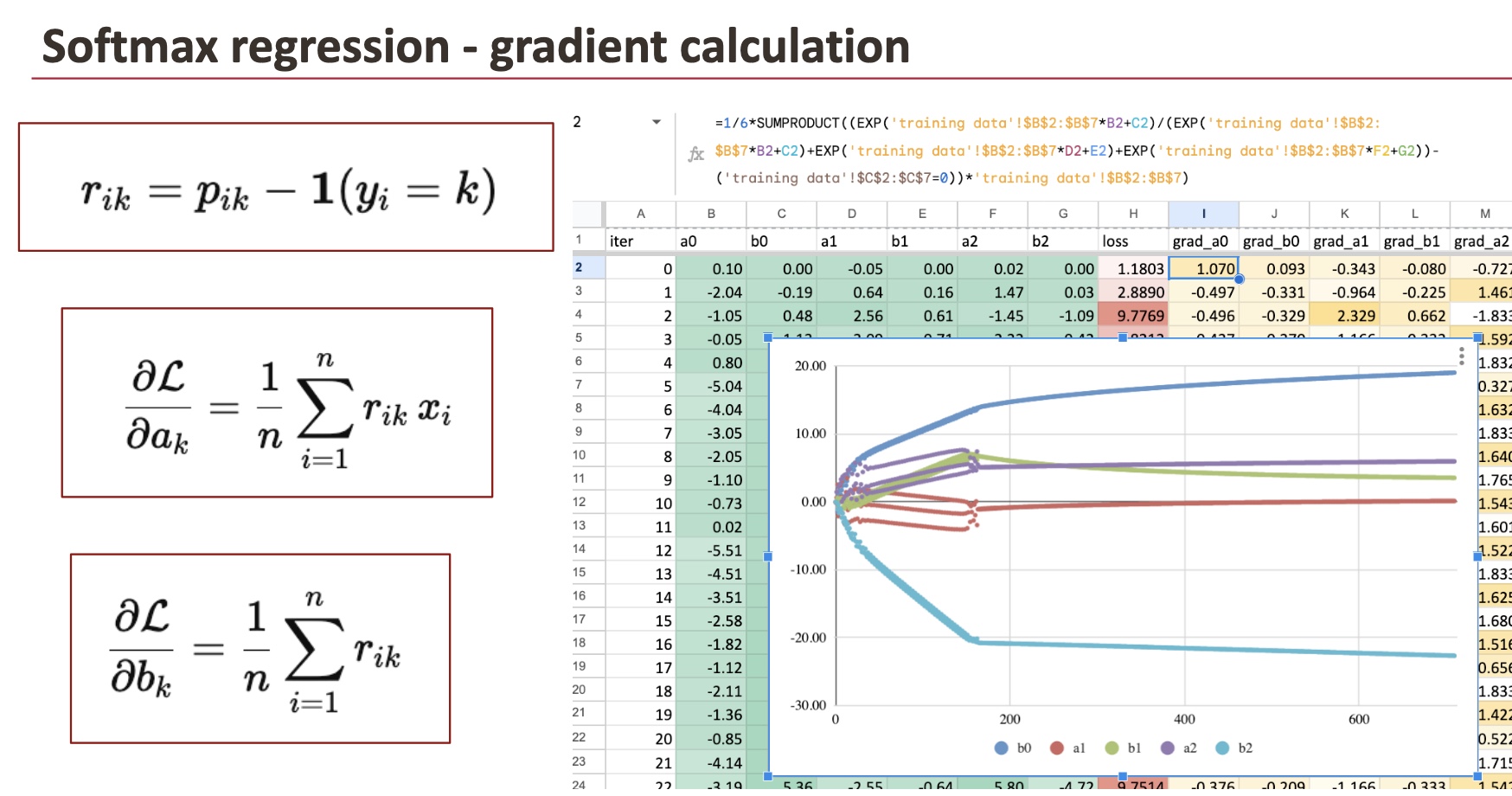
Calcul des résidus
Pour mettre à jour les coefficients, on commence par calculer résidusun par classe.
Pour chaque ligne :
- résidu_0 = p0 moins 1 si y est égal à 0, sinon 0
- résiduel_1 = p1 moins 1 si y est égal à 1, sinon 0
- résiduel_2 = p2 moins 1 si y est égal à 2, sinon 0
En d’autres termes, pour la bonne classe, on soustrait 1.
Pour les autres classes, on soustrait 0.
Ces résidus mesurent dans quelle mesure les probabilités prédites sont éloignées de ce que nous attendons.
Calcul des dégradés
Les dégradés sont obtenus en combinant les résidus avec les valeurs des caractéristiques.
Pour chaque classe k :
- le gradient de ak est la moyenne de
residual_k * x - le gradient de bk est la moyenne de
residual_k
Dans Excel, cela est implémenté avec des formules simples telles que SUMPRODUCT et AVERAGE.
A ce stade, tout est explicite :
vous voyez les résidus, les gradients et la contribution de chaque point de données.

Mise à jour des coefficients
Une fois les gradients connus, nous mettons à jour les coefficients en utilisant la descente de gradient.
Cette étape est identique à celle que nous avons vue précédemment, avant la régression logistique ou la régression linéaire.
La seule différence est que nous mettons désormais à jour six coefficients au lieu de deux.
Pour visualiser l’apprentissage, nous créons une deuxième feuille avec une ligne par itération :
- le numéro d’itération actuel
- les six coefficients (a0, b0, a1, b1, a2, b2)
- la perte
- les dégradés
La ligne 2 correspond à itération 0avec les coefficients initiaux.
La ligne 3 calcule les coefficients mis à jour en utilisant les gradients de la ligne 2.
En faisant glisser les formules vers le bas sur des centaines de lignes, nous simulons une descente de gradient sur de nombreuses itérations.
On voit alors clairement :
- les coefficients se stabilisent progressivement
- la perte décroissante itération après itération
Cela rend le processus d’apprentissage tangible.
Au lieu d’imaginer un optimiseur, vous pouvez regardez le modèle apprendre.

La régression logistique comme cas particulier de la régression Softmax
La régression logistique et la régression Softmax sont souvent présentées comme des modèles différents.
En réalité, il s’agit de la même idée à différentes échelles.
Softmax Regression calcule un score linéaire par classe et transforme ces scores en probabilités en les comparant.
Lorsqu’il n’y a que deux classes, cette comparaison dépend uniquement de la différence entre les deux scores.
Cette différence est une fonction linéaire de l’entrée, et l’application de Softmax dans ce cas produit exactement la fonction logistique (sigmoïde).
En d’autres termes, la régression logistique est simplement une régression Softmax appliquée à deux classes, avec la suppression des paramètres redondants.
Une fois cela compris, passer de la classification binaire à la classification multiclasse devient une extension naturelle et non un saut conceptuel.

Softmax Regression n’introduit pas une nouvelle façon de penser.
Cela montre simplement que Logistic Regression contenait déjà tout ce dont nous avions besoin.
En dupliquant le score linéaire une fois par classe et en les normalisant avec Softmax, on passe des décisions binaires aux probabilités multiclasses sans changer la logique sous-jacente.
La perte est la même idée.
Les dégradés ont la même structure.
L’optimisation est la même descente de gradient que nous connaissons déjà.
Ce qui change, c’est seulement le nombre de scores parallèles.
Une autre façon de gérer la classification multiclasse ?
Softmax n’est pas le seul moyen de résoudre les problèmes multiclasses dans les modèles basés sur le poids.
Il existe une autre approche, moins élégante conceptuellement, mais très courante dans la pratique :
un contre repos ou un contre un classification.
Au lieu de construire un seul modèle multiclasse, nous formons plusieurs modèles binaires et combinons leurs résultats.
Cette stratégie est largement utilisée avec Machines à vecteurs de support.
Demain, nous examinerons SVM.
Et vous verrez que cela peut s’expliquer d’une manière assez inhabituelle… et, comme d’habitude, directement dans Excel.


