
Le Bonus 1 du « Calendrier de l’Avent » du Machine Learning : AUC dans Excel
nous implémenterons AUC dans Excel.
L’AUC est généralement utilisée pour les tâches de classification en tant que mesure de performance.
Mais nous commençons par une matrice de confusion, car c’est par là que tout le monde commence en pratique. Nous verrons ensuite pourquoi une seule matrice de confusion ne suffit pas.
Et nous répondrons également à ces questions :
- AUC signifie Aire sous la courbe, mais sous quelle courbe ?
- D’où vient cette courbe ?
- Pourquoi la zone a-t-elle un sens ?
- L’AUC est-elle une probabilité ? (Oui, il a une interprétation probabiliste)
1. Pourquoi une matrice de confusion ne suffit pas
1.1 Scores des modèles
Un classificateur nous donnera généralement partitionspas de décisions finales. La décision vient plus tard, quand on choisit un seuil.
Si vous avez lu les précédents articles du « Calendrier de l’Avent », vous avez déjà vu que « score » peut signifier différentes choses selon la famille de modèles :
- Modèles basés sur la distance (comme k-NN) calculent souvent la proportion de voisins pour une classe donnée (ou une confiance basée sur la distance), qui devient un score.
- Modèles basés sur la densité calculez une probabilité sous chaque classe, puis normalisez pour obtenir une probabilité finale (postérieure).
- Classification Modèles basés sur des arbres affiche souvent la proportion d’une classe donnée parmi les échantillons d’apprentissage à l’intérieur de la feuille (c’est pourquoi de nombreux points partagent le même score).
- Modèles basés sur le poids (modèles linéaires, noyaux, réseaux de neurones) calculent une somme pondérée ou un score non linéaire, et appliquent parfois une étape de calibrage (sigmoïde, softmax, mise à l’échelle de Platt, etc.) pour le mapper à une probabilité.
Alors quelle que soit l’approche, on se retrouve avec la même situation : une note par observation.
Ensuite, en pratique, on choisit un seuil, souvent 0,5et nous convertissons les scores en classes prédites.
Et c’est exactement là que la matrice de confusion entre dans l’histoire.
1.2 La matrice de confusion à un seuil
Une fois un seuil choisi, chaque observation devient une décision binaire :
- prédit positif (1) ou prédit négatif (0)
De là, nous pouvons compter quatre nombres :
- TP (Vrais positifs) : 1 prédit et en réalité 1
- TN (Vrais Négatifs) : 0 prédit et en réalité 0
- PF (Faux Positifs) : prédit 1 mais en réalité 0
- FR (Faux Négatifs) : prédit 0 mais en réalité 1
Cette table de comptage 2×2 est la matrice de confusion.
Ensuite, nous calculons généralement des ratios tels que :
- Précision = TP / (TP + FP)
- Rappel (TPR) = TP / (TP + FN)
- Spécificité = TN / (TN + FP)
- FPR = FP / (FP + TN)
- Précision = (TP + TN) / Total
Jusqu’à présent, tout est clair et intuitif.
Mais il existe une limitation cachée : toutes ces valeurs dépendent du seuil. Ainsi, la matrice de confusion évalue le modèle à un point de fonctionnement, et non le modèle lui-même.

1.3 Quand un seuil casse tout
C’est un exemple étrange, mais il illustre néanmoins très clairement ce point.
Imaginez que votre seuil soit fixé à 0,50 et que tous les scores soient inférieurs à 0,50.
Le classificateur prédit alors :
- Positif prédit : aucun
- Négatif prédit : tout le monde
Vous obtenez donc :
- TP = 0, FP = 0
- FN = 10, TN = 10

Il s’agit d’une matrice de confusion parfaitement valable. Cela crée également un sentiment très étrange :
- La précision devient
#DIV/0!car il n’y a aucun résultat positif prévu. - Le rappel est de 0 % car vous n’avez capturé aucun positif.
- La précision est de 50 %, ce qui ne semble « pas si mal », même si le modèle n’a rien trouvé.
Il n’y a rien de mal avec la matrice de confusion. Le problème est la question à laquelle nous lui avons demandé de répondre.
Une matrice de confusion répond : « Quelle est la qualité du modèle à ce seuil spécifique ? »
Si le seuil est mal choisi, la matrice de confusion peut rendre un modèle inutile, même lorsque les scores contiennent une réelle séparation.
Et dans votre tableau, la séparation est visible : les positifs ont souvent des scores autour de 0,49, les négatifs sont plutôt autour de 0,20 ou 0,10. Le modèle n’est pas aléatoire. Votre seuil est tout simplement trop strict.
C’est pourquoi un seul seuil ne suffit pas.
Ce dont nous avons besoin, c’est d’un moyen d’évaluer le modèle au-delà des seuilspas un seul.
2. ROC
Nous devons d’abord construire la courbe, puisque AUC signifie Area Under a Curve, nous devons donc comprendre cette courbe.
2.1 Ce que signifie ROC (et qu’est-ce que c’est)
Car la première question que chacun devrait se poser est : AUC sous quelle courbe ?
La réponse est :
L’AUC est l’aire sous la courbe ROC.
Mais cela soulève une autre question.
Qu’est-ce que la courbe ROC et d’où vient-elle ?
ROC signifie Caractéristiques de fonctionnement du récepteur. Le nom est historique (détection précoce des signaux), mais l’idée est moderne et simple : elle décrit ce qui se passe lorsque vous modifiez le seuil de décision.
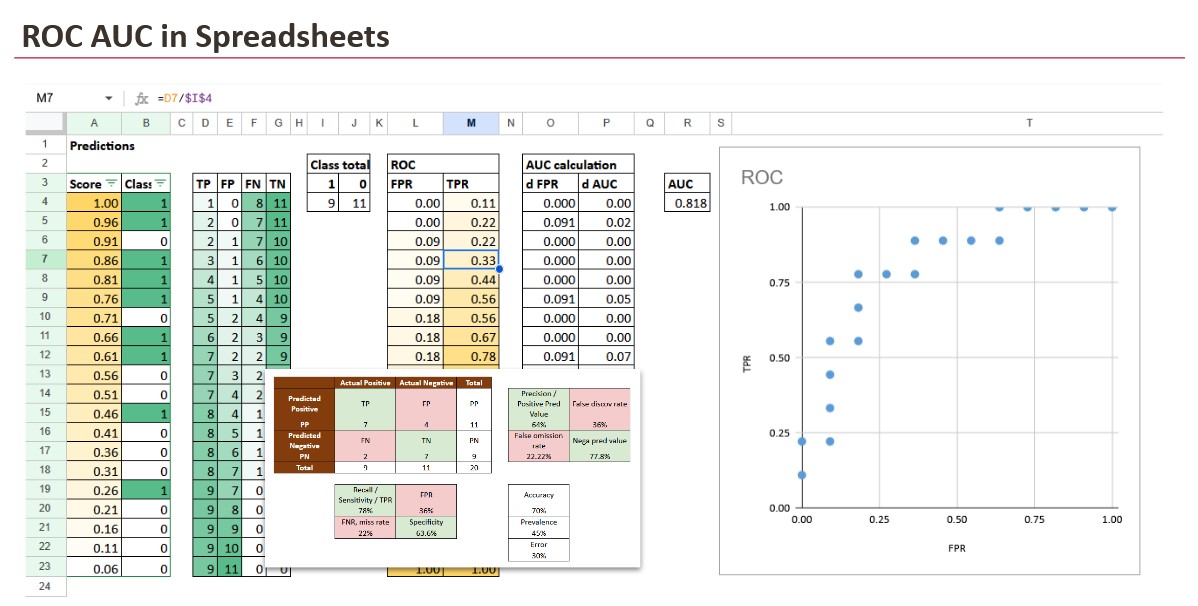
La courbe ROC est un tracé avec :
- Axe des x : FPR (Taux de faux positifs)
FPR = FP / (FP + TN) - Axe y : TPR (True Positive Rate), également appelé rappel ou sensibilité
TPR = TP / (TP + FN)
Chaque seuil donne un point (FPR, TPR). Lorsque vous connectez tous les points, vous obtenez la courbe ROC.
A ce stade, un détail compte : la courbe ROC n’est pas observée directement ; il est construit en balayant le seuil sur l’ordre des scores.
2.2 Construire la courbe ROC à partir des scores
Pour chaque score, nous pouvons l’utiliser comme seuil (et bien sûr, nous pourrions également définir des seuils personnalisés).
Pour chaque seuil :
- nous calculons TP, FP, FN, TN à partir de la matrice de confusion
- puis on calcule FPR et TPR
La courbe ROC est donc simplement la collection de toutes ces paires (FPR, TPR), ordonnées depuis les seuils stricts jusqu’aux seuils permissifs.
C’est exactement ce que nous allons implémenter dans Excel.

À ce stade, il est important de remarquer quelque chose qui semble presque trop simple. Lorsque nous construisons la courbe ROC, les valeurs numériques réelles des scores n’ont pas d’importance. Ce qui compte c’est le commande.
Si un modèle génère des scores compris entre 0 et 1, un autre produit des scores compris entre -12 et +5 et un troisième ne produit que deux valeurs distinctes, ROC fonctionne de la même manière. Tant que les scores les plus élevés tendent à correspondre à la classe positive, le balayage du seuil créera la même séquence de décisions.
C’est pourquoi la première étape dans Excel est toujours la même : trier par score du plus élevé au plus bas. Une fois que les lignes sont dans le bon ordre, le reste ne fait que compter.
2.3 Lecture de la courbe ROC
Dans la feuille Excel, la construction devient très concrète.
Vous triez les observations par score, du plus élevé au plus bas. Ensuite, vous parcourez la liste. À chaque ligne, vous agissez comme si le seuil était fixé à ce score, ce qui signifie : tout ce qui précède est prédit positif.
Cela permet à Excel de calculer les décomptes cumulés :
- combien de points positifs avez-vous acceptés jusqu’à présent
- combien de négatifs avez-vous accepté jusqu’à présent
À partir de ces décomptes cumulés et des totaux de l’ensemble de données, nous calculons le TPR et le FPR.
Désormais, chaque ligne représente un point ROC.
Pourquoi la courbe ROC ressemble à un escalier
- Lorsque la prochaine ligne acceptée est positive, TP augmente, donc TPR augmente tandis que FPR reste stable.
- Lorsque la prochaine ligne acceptée est négative, FP augmente, donc FPR augmente tandis que TPR reste stable.
C’est pourquoi, avec des données réelles finies, la courbe ROC est un escalier. Excel rend cela visible.
2.4 Cas de référence à reconnaître
Quelques cas de référence vous aident à lire immédiatement la courbe :
- Classement parfait: la courbe monte tout droit (TPR atteint 1 tandis que FPR reste 0), puis va tout en haut.

- Classificateur aléatoire: la courbe reste proche de la diagonale de (0,0) à (1,1).

- Classement inversé: la courbe descend « en dessous » de la diagonale, et l’AUC devient inférieure à 0,5. Mais dans ce cas, nous devons changer les scores avec un score de 1. En théorie, on peut considérer ce cas fictif. En pratique, cela se produit généralement lorsque les scores sont interprétés dans le mauvais sens ou que les étiquettes de classe sont inversées.

Ce ne sont pas seulement de la théorie. Ce sont des ancres visuelles. Une fois que vous les avez, vous pouvez interpréter rapidement n’importe quelle courbe ROC réelle.
3. AUC ROC
Maintenant, avec la courbe, que pouvons-nous faire ?
3.1 Calcul de la surface
Une fois que la courbe ROC existe sous forme de liste de points (FPR, TPR), l’AUC est une pure géométrie.
Entre deux points consécutifs, l’aire ajoutée est l’aire d’un trapèze :
- largeur = changement de FPR
- hauteur = TPR moyen des deux points
Dans Excel, cela devient une approche « colonne delta » :
- calculer dFPR entre des lignes consécutives
- multiplier par le TPR moyen
- résumer tout

Différents cas :
- classification parfaite : AUC = 1
- classement aléatoire : AUC ≈ 0,5
- classement inversé : AUC < 0,5
L’AUC est donc littéralement le résumé de tout l’escalier ROC.
3.2. AUC comme probabilité
L’AUC ne consiste pas à choisir un seuil.
Cela répond à une question beaucoup plus simple :
Si je choisis au hasard un exemple positif et un exemple négatif, quelle est la probabilité que le modèle attribue un score plus élevé à l’exemple positif ?
C’est tout.
- AUC = 1,0 signifie un classement parfait (le positif obtient toujours un score plus élevé)

- AUC = 0,5 signifie un classement aléatoire (il s’agit essentiellement d’un tirage au sort)

- AUC < 0,5 signifie que le classement est inversé (les négatifs ont tendance à obtenir des scores plus élevés)
Cette interprétation est extrêmement utile, car elle explique à nouveau ce point important :
L’AUC dépend uniquement de l’ordre des scores et non des valeurs absolues.
C’est pourquoi le ROC AUC fonctionne même lorsque les « scores » ne sont pas des probabilités parfaitement calibrées. Il peut s’agir de scores bruts, de marges, de proportions de feuilles ou de toute valeur de confiance monotone. Tant que plus élevé signifie « plus probablement positif », l’AUC peut évaluer la qualité du classement.
Conclusion
Une matrice de confusion évalue un modèle à un seuil, mais les classificateurs produisent des scores et non des décisions.
ROC et AUC évaluent le modèle sur tous les seuils en se concentrant sur classementpas d’étalonnage.
En fin de compte, l’AUC répond à une question simple : à quelle fréquence un exemple positif reçoit-il un score plus élevé qu’un exemple négatif ?
Vu de cette façon, ROC AUC est une mesure intuitive, et une feuille de calcul suffit pour rendre explicite chaque étape.


