
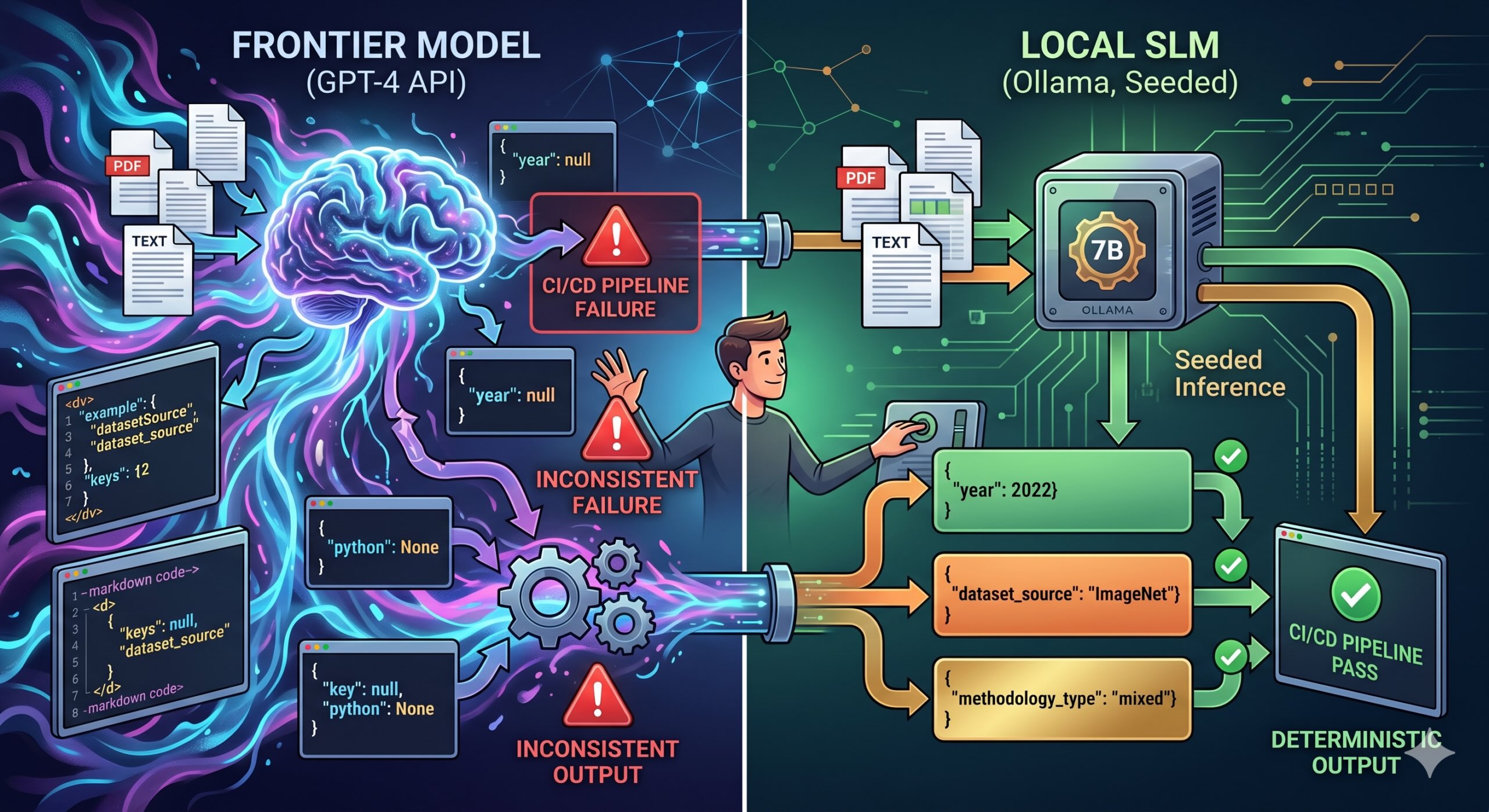
J’ai remplacé GPT-4 par un SLM local et mon pipeline CI/CD a cessé d’échouer
réécriture de la même invite système.
Vous DEVEZ renvoyer UNIQUEMENT un JSON valide. Pas de démarque. Pas de barrières de code. Aucune explication. JUSTE l’objet JSON.
J’avais écrit MUST en majuscules. Vers un modèle de langage. Comme si l’accent pouvait être mis sur quelque chose qui n’a pas de sentiments ou, apparemment, une définition cohérente de « JSON valide ».
Cela n’a pas fonctionné. Voici ce qui s’est passé.
Comment GPT-4 s’est retrouvé dans un travail par lots nocturne
Notre équipe consomme des documents de recherche, tels que des PDF et du texte brut, et parfois ces satanés rapports semi-structurés que certains fournisseurs ont clairement exportés à partir d’une feuille de calcul dont ils étaient très fiers. Et une partie de ce pipeline les classe et extrait les champs structurés avant que quoi que ce soit ne touche l’entrepôt de données. Type de méthodologie, source de l’ensemble de données, indicateurs clés.
Cela ressemble à un problème résolu. C’est généralement le cas, jusqu’à ce qu’il y ait une quarantaine de types de méthodes répertoriées et que les documents ne ressemblent plus à ceux sur lesquels vous avez été formé.
Pendant un certain temps, nous avons géré cela à l’aide d’expressions régulières, d’extracteurs basés sur des règles et d’un modèle BERT affiné. La bonne nouvelle, c’est que cela a fonctionné, mais le maintenir, c’était comme réparer un fichier CSS de 2015, dans lequel vous touchez une règle et quelque chose sans rapport s’interrompt sur une page que vous n’avez pas visitée depuis des mois.
Ainsi, lorsque GPT-4 est arrivé, nous l’avons essayé.
Je ne vais pas mentir, c’était assez incroyable. Les cas extrêmes qui ont rendu BERT fou pendant des mois, les formats que nous n’avions jamais vus auparavant et les documents avec des sections incohérentes ont tous été traités proprement par GPT-4.
La démo de l’équipe s’est bien déroulée. Je veux dire, quelqu’un a même dit « wow » à voix haute.
J’ai envoyé un SMS à mon manager ce soir-là : « Je pense que nous avons résolu le problème de l’extraction. » Envoyé en toute confiance.
Deux semaines après son déploiement, les échecs ont commencé.
Le problème du « principalement cohérent »
D’après mon expérience, GPT-4 est capable et non déterministe.
Pour de nombreux cas d’utilisation, le non-déterminisme n’a pas d’importance. Pour un pipeline de lots nocturne alimentant un entrepôt de données, cela compte beaucoup.
À temperature=0 tu as surtout des résultats cohérents. Dans un contexte CI/CD, « la plupart du temps » signifie « ça va s’arrêter un vendredi ».
Les échecs n’étaient pas non plus dramatiques ; sinon, cela aurait été plus facile à déboguer. GPT-4 n’hallucinait pas les champs ni ne retournait les ordures.
Il faisait des choses subtiles. "dataset_source" une nuit, "datasetSource" le suivant, "source_dataset" la nuit d’après. Le code Markdown contourne le JSON même si nous lui avions dit de ne pas le faire, dans chaque version de l’invite. Nombres renvoyés sous forme de chaînes. JSON null renvoyé sous forme de chaîne Python "None"; J’ai passé plus de temps que je ne voudrais l’admettre à regarder celui-là.
Chaque échec suivait le même rituel.
Pydantic l’attrape en aval, le pipeline échoue, je confirme qu’il s’agit d’une autre bizarrerie de formatage, puis je me mets immédiatement au travail pour le réexécuter manuellement. Cela revient, puis environ trois jours plus tard, une bizarrerie différente recommence.
J’ai donc commencé à tenir un journal. Six semaines :
- 23 pannes de pipelines de l’incohérence de sortie GPT-4
- ~18 minutes moyenne pour diagnostiquer et réexécuter
- 0 bug réel dans le code du pipeline
Zéro vrai bug. À chaque échec, le modèle était subtilement différent de ce qu’il avait été la nuit précédente. C’est ce chiffre qui m’a fait arrêter de défendre la configuration.
Ce que j’ai essayé avant d’admettre le vrai problème
Invite
Sept réécritures sur deux jours.
Je n’avais même pas réalisé que cela avait rapporté autant. Je voulais juste une bonne solution. Et cela ne s’est même pas arrêté là.
J’ai essayé des instructions en majuscules, des exemples de quelques plans et des contre-exemples avec un en-tête « Ne faites PAS cela ». J’ai même essayé d’ajouter un rappel à la toute fin du message utilisateur comme un dernier coup de pouce, comme si le modèle arrivait à cette ligne et réfléchissait oh c’est vrai, JSON uniquement, j’ai presque oublié.
À un moment donné, la même instruction est apparue à trois endroits différents dans la même invite, et j’ai sincèrement pensé que cela pourrait aider. Les échecs se sont poursuivis, inchangés.
Un analyseur de nettoyage
Lorsque l’invite a échoué, j’ai écrit du code pour nettoyer tout désordre que GPT-4 m’avait renvoyé.
Supprimez les barrières de démarque, recherchez l’objet JSON s’il était enfoui dans le texte et enregistrez la sortie brute lorsque rien ne fonctionnait.
Cette méthode a fonctionné pendant environ une semaine, ce qui était suffisamment de temps pour que je me sente bien.
Et puis GPT-4 a commencé à renvoyer du JSON structurellement valide avec de mauvais noms de clé, camelCase au lieu de Snake_case. L’analyseur l’a bien réussi et l’erreur est apparue trois étapes plus tard.
Je jouais à Whack-a-Mole avec un modèle qui avait une infinité de taupes.
response_format + temperature=0. OpenAI response_format={"type": "json_object"} combiné avec temperature=0 a ramené le nombre d’échecs de 23 à environ 9. Des progrès significatifs. Ce n’est toujours pas zéro, et « neuf pannes aléatoires toutes les six semaines » n’est pas une propriété de pipeline que je pourrais défendre.
Appel de fonction
C’est celui qui a presque fonctionné. Forcer la sortie via un contrat de schéma dactylographié a véritablement resserré les choses.
J’ai arrêté de vérifier les journaux tous les matins, j’ai arrêté de me préparer à la notification Slack. J’ai dit à quelqu’un de l’équipe que c’était stable. Ce qui, si vous travaillez dans un logiciel, vous savez que c’est le moyen le plus rapide de gâcher quelque chose.
functions = [
{
"name": "extract_document_metadata",
"parameters": {
"type": "object",
"properties": {
"methodology_type": {
"type": "string",
"enum": ["experimental", "observational", "review", "simulation", "mixed"]
},
"dataset_source": {"type": "string"},
"primary_metric": {"type": "string"},
"year": {"type": "integer"},
"confidence_score": {"type": "number", "minimum": 0, "maximum": 1}
},
"required": ["methodology_type", "dataset_source", "year"]
}
}
]
response = openai_client.chat.completions.create(
model="gpt-4-turbo",
messages=messages,
functions=functions,
function_call={"name": "extract_document_metadata"},
temperature=0
)Puis un mardi, l’API OpenAI a connu une interruption de 20 minutes. Le pipeline a échoué durement ; ce n’était pas un problème de modèle, juste une dépendance au réseau avec laquelle nous n’avions jamais vraiment pris en compte.
Nous ne pouvions pas verrouiller la version du modèle, nous ne pouvions pas l’exécuter hors ligne, nous ne pouvions pas répondre « qu’est-ce qui a changé entre l’exécution qui a fonctionné et celle qui n’a pas fonctionné ? » parce que le modèle à l’autre bout du fil n’était pas le nôtre.
Assis là, attendant que l’API de quelqu’un d’autre soit récupérée, j’ai finalement posé la question que j’aurais dû poser des mois plus tôt : ce travail spécifique nécessite-t-il réellement un modèle frontière ?
Les modèles locaux sont meilleurs que ce à quoi je m’attendais
J’y suis allé en m’attendant à passer une journée à confirmer qu’ils n’étaient pas assez bons. J’avais une conclusion prête avant d’effectuer un seul test : essayé, la qualité n’était pas là, restant sur GPT-4 avec une meilleure logique de nouvelle tentative. Une histoire où la première décision était encore défendable.
Il m’a fallu peut-être trois heures pour réaliser que j’avais mal réfléchi.
L’extraction de documents dans un schéma fixe n’est pas réellement une tâche difficile pour un modèle de langage. Pas dans le sens où un modèle frontière serait nécessaire. Il n’y a aucun raisonnement impliqué, aucune synthèse, pas besoin de l’étendue des connaissances mondiales qui font que GPT-4 vaut ce qu’il coûte.
Qu’est-ce que c’est réellement : une compréhension écrite structurée. Le modèle lit un document et remplit les champs. Un modèle 7B bien entraîné fait cela très bien. Et avec la bonne configuration, en particulier l’inférence prédéfinie, il le fait à l’identique chaque course.
J’ai exécuté quatre modèles sur 50 documents que j’avais annotés manuellement :
- Phi-3-mini (3,8B): Meilleure instruction suivie que ce à quoi je m’attendais pour un modèle 3,8B, mais elle s’est effondrée sur tout ce qui dépassait environ 3 000 jetons. J’ai failli choisir ceci avant de regarder les résultats de la documentation plus longue.
- Instruire Mistral 7B: Du solide partout, pas de réelles surprises dans les deux sens. La Toyota Camry des modèles locaux. Ça ne te conviendrait pas.
- Qwen2.5-7B-Instruct: Celui-ci a gagné clairement. Meilleure cohérence de sortie structurée des quatre avec une marge suffisamment large pour que ce ne soit pas un appel serré.
- Lama 3.2 3B Instruire: C’est rapide, mais la qualité de l’extraction a suffisamment diminué dans les cas extrêmes pour que je ne l’exécute pas sur des données de production sans d’abord beaucoup plus de travail de validation.
Qwen2.5 et Mistral atteignent tous deux une précision de 90 à 95 % sur l’ensemble annoté, inférieure à GPT-4 sur des documents véritablement ambigus, oui.
Mais j’ai exécuté Qwen2.5 trois fois sur les mêmes 20 documents et je suis revenu pour comparer les résultats. Aucune différence. Même JSON, mêmes valeurs, même ordre des champs à chaque exécution.
Après six semaines d’échecs que je ne pouvais pas prédire, cela semblait presque trop propre pour être réel.
Avant et Après
L’extracteur GPT-4 dans sa forme la plus stable, pas le prototype original, la version après des mois de code défensif s’était accumulée autour de lui :
# extractor_gpt4.py
import os
import json
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
SYSTEM_PROMPT = """You are a research document metadata extractor.
Given the text of a research document, extract the specified metadata fields.
Be precise. If you are unsure about a field, use your best judgment based on context."""
EXTRACTION_SCHEMA = {
"name": "extract_document_metadata",
"parameters": {
"type": "object",
"properties": {
"methodology_type": {
"type": "string",
"enum": ["experimental", "observational", "review", "simulation", "mixed"]
},
"dataset_source": {"type": "string"},
"primary_metric": {"type": "string"},
"year": {"type": "integer"},
"confidence_score": {"type": "number"}
},
"required": ["methodology_type", "dataset_source", "year"]
}
}
def extract_metadata_gpt4(document_text: str) -> dict:
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Extract metadata from this document:\n\n{document_text[:8000]}"}
],
functions=[EXTRACTION_SCHEMA],
function_call={"name": "extract_document_metadata"},
temperature=0,
timeout=30
)
try:
args = response.choices[0].message.function_call.arguments
return json.loads(args)
except (AttributeError, json.JSONDecodeError) as e:
raise ValueError(f"Failed to parse GPT-4 response: {e}")Latence : 3,5 à 5,8 s par document. Coût : ~0,04 $ par appel. Taux d’échec : ~6 % après tous les correctifs.
Pour le remplacement, j’ai choisi Ollama. Un collègue l’a mentionné avec désinvolture, et les documents semblaient raisonnables à 23 heures, ce qui est honnêtement ainsi que de nombreuses décisions en matière d’infrastructure sont prises. L’API REST est suffisamment proche de celle d’OpenAI pour que l’échange prenne environ une heure :
# extractor_slm.py
import json
import logging
import os
import re
import requests
logger = logging.getLogger(__name__)
OLLAMA_URL = os.getenv("OLLAMA_URL", "http://localhost:11434")
MODEL = os.getenv("MODEL_NAME", "qwen2.5:7b-instruct-q4_K_M")
# Tested empirically: 7B q4 on a T4 takes ~8s on cold first token,
# then ~1.5s per doc chunk. 45s covers bad days.
_TIMEOUT = 45
_SYSTEM_PROMPT = """\
You are a metadata extractor for research documents.
Return ONLY a JSON object — no explanation, no markdown, no surrounding text.
Fields to extract:
- methodology_type (required): one of experimental | observational | review | simulation | mixed
- dataset_source (required): where the data came from
- year (required): integer
- primary_metric: main eval metric if present
- confidence_score: your confidence 0.0–1.0
Output example:
{"methodology_type": "experimental", "dataset_source": "ImageNet", "year": 2022, "primary_metric": "top-1 accuracy", "confidence_score": 0.95}
"""
def call_ollama(doc_text: str) -> dict:
payload = {
"model": MODEL,
"messages": [
{"role": "system", "content": _SYSTEM_PROMPT},
{"role": "user", "content": doc_text[:6000]},
],
"stream": False,
"options": {
"temperature": 0,
"seed": 42, # determinism — this is the whole point
},
}
try:
resp = requests.post(f"{OLLAMA_URL}/api/chat", json=payload, timeout=_TIMEOUT)
resp.raise_for_status()
except requests.exceptions.Timeout:
raise RuntimeError(f"Ollama timed out after {_TIMEOUT}s — is the model loaded?")
except requests.exceptions.ConnectionError:
raise RuntimeError(f"Can't reach Ollama at {OLLAMA_URL} — is the container running?")
raw = resp.json()["message"]["content"].strip()
cleaned = re.sub(r"^```(?:json)?\s*|\s*```$", "", raw).strip()
try:
return json.loads(cleaned)
except json.JSONDecodeError as e:
logger.error("Failed to parse model output: %s\nRaw was: %s", e, raw[:400])
raiseLe seed: 42 dans les options, c’est ce qui fournit réellement le déterminisme. Ollama soutient la génération ensemencée ; même entrée, même graine, même sortie, à chaque fois, pas approximativement. temperature=0 avec une API hébergée, cela impliquait cela mais ne l’a jamais garanti car vous ne contrôlez pas le runtime. Localement, vous l’êtes.
L’intégrer dans les actions GitHub
Deux choses qui ne sont pas évidentes jusqu’à ce qu’elles vous mordent. Premièrement : les conteneurs de services GitHub Actions sont réseau isolé du coureur. Tu ne peux pas docker exec en eux; l’extraction du modèle doit passer par l’API REST. Deuxièmement : mettez en cache le modèle. Un tirage à froid représente 4,7 Go et ajoute 3 à 4 minutes à chaque tâche.
# The non-obvious parts — the rest is standard Actions boilerplate
- name: Cache Ollama model
uses: actions/cache@v4
with:
path: ~/.ollama/models
key: ollama-qwen2.5-7b-q4
- name: Pull SLM model
# Can't docker exec into service containers — use the API
run: |
curl -s http://localhost:11434/api/pull \
-d '{"name": "qwen2.5:7b-instruct-q4_K_M"}' \
--max-time 300
- name: Warm up model
run: |
curl -s http://localhost:11434/api/generate \
-d '{"model": "qwen2.5:7b-instruct-q4_K_M", "prompt": "hello", "stream": false}' \
> /dev/null
- name: Run ingestion pipeline
run: python pipeline/run_ingestion.py
env:
OLLAMA_URL: "http://localhost:11434"
MODEL_NAME: "qwen2.5:7b-instruct-q4_K_M"Le bug de capitalisation sur lequel j’ai passé trop de temps
Qwen 2.5 revient occasionnellement "Experimental" avec un E majuscule malgré les instructions explicites de ne pas le faire. Le Literal la vérification de type le rejette et vous obtenez un échec de validation sur un document que le modèle a réellement extrait correctement.
J’ai passé un temps embarrassant là-dessus parce que le message d’erreur disait simplement « valeur invalide », et mon premier réflexe a été de regarder le document, puis l’extracteur, avant de finalement regarder le validateur et de le voir.
UN normalize_methodology validateur avec mode="before" le corrige avant l’exécution de la vérification de type :
# pipeline/validation.py
from typing import Literal, Optional
from pydantic import BaseModel, Field, field_validator
class DocMetadata(BaseModel):
methodology_type: Literal["experimental", "observational", "review", "simulation", "mixed"]
dataset_source: str = Field(min_length=3)
year: int = Field(ge=1950, le=2030)
primary_metric: Optional[str] = None
confidence_score: Optional[float] = Field(default=None, ge=0.0, le=1.0)
@field_validator("dataset_source")
@classmethod
def strip_whitespace(cls, v: str) -> str:
return v.strip()
@field_validator("methodology_type", mode="before")
@classmethod
def normalize_methodology(cls, v: str) -> str:
# Qwen occasionally returns "Experimental" despite instructions
return v.lower().strip() if isinstance(v, str) else vJe veux être honnête sur les compromis parce que je déteste les articles qui ne le font pas.
GPT-4 est véritablement meilleur sur les documents ambigus, les textes non anglais, tout ce qui nécessite une véritable inférence. Il existe une classe de documents dans notre corpus, des PDF plus anciens, des rapports mélangeant plusieurs langues, des formats non standards, sur lesquels le SLM trébuche et le GPT-4 ne le ferait pas.
Nous les signalons séparément et les acheminons vers une file d’attente de révision. Ce n’est pas transparent, mais c’est honnête. Le SLM fait les 90 % pour lesquels il est bon et on ne lui demande pas de faire le reste.
La configuration demande également plus de travail que pip install openai. La première configuration prend un véritable après-midi. Et Ollama ne met pas à jour automatiquement les modèles, donc la gestion des versions est mon problème maintenant. J’ai vraiment fait la paix avec cela, sachant exactement quelle version du modèle a été utilisée la nuit dernière et la nuit précédente, c’est tout l’intérêt.
Ce que je pense maintenant
Le matin, le pipeline a fonctionné pour la première fois, sans notification, ni réexécution, juste un fichier journal montrant 312 documents traités en 8,4 minutes, je l’ai vérifié deux fois, puis je l’ai réexécuté manuellement.
J’avais passé six semaines à m’attendre à moitié à une alerte avant même d’avoir fini mon café. Le regarder passer tranquillement était vraiment étrange.
L’échec n’utilisait pas GPT-4. L’échec était de traiter un système probabiliste comme une fonction déterministe. temperature=0 réduit la variance. Cela ne l’élimine pas.
J’ai compris cela en théorie tout le temps. Il a fallu 23 échecs pour le comprendre d’une manière qui a changé ma façon de construire les choses.
Si vous exécutez un LLM dans un pipeline automatisé et que les choses continuent de se briser d’une manière que vous ne pouvez pas reproduire, il se peut qu’il ne s’agisse pas de votre code ou de vos invites. Cela peut être dû à la nature de ce dont vous dépendez.
Un modèle local sur le matériel que vous contrôlez, axé sur le déterminisme, constitue une classe d’outils véritablement différente pour ce type de travail. Pas meilleur en tout mais meilleur pour être deux fois la même chose. Et pour un pipeline qui fonctionne sans surveillance toutes les nuits, c’est là l’essentiel de ce qui compte réellement.
Avant de partir !
Si cela s’est avéré utile, j’écrirai davantage sur la réalité compliquée derrière la construction avec l’IA, les interruptions de production, ce qui fonctionne réellement et les compromis derrière les correctifs.
Tu peux abonnez-vous à mon bulletin si vous en voulez plus.
Connectez-vous avec moi
Références
You may also like


