
Il n’est pas nécessaire qu’il s’agisse d’un chatbot
commence généralement de la même manière. Lors d’une réunion de direction, quelqu’un dit : « Utilisons l’IA ! » Les têtes hochent la tête, l’enthousiasme monte et avant que vous vous en rendiez compte, la salle atterrit sur la conclusion par défaut : « Bien sûr, nous allons créer un chatbot. » Cet instinct est compréhensible. Les grands modèles de langage sont puissants, omniprésents et fascinants. Ils promettent un accès intuitif à des connaissances et des fonctionnalités universelles.
L’équipe s’éloigne et commence à construire. Bientôt, l’heure de la démonstration arrive. Une interface de discussion raffinée apparaît, accompagnée d’arguments confiants expliquant pourquoi cette fois, ce sera différent. Cependant, à ce stade, les utilisateurs réels n’ont généralement pas été touchés dans des situations réelles, et l’évaluation est biaisée et optimiste. Quelqu’un dans le public pose inévitablement une question personnalisée, ce qui irrite le robot. Les développeurs promettent de résoudre ce problème, mais dans la plupart des cas, le problème sous-jacent est systémique.
Une fois le chatbot lancé, l’optimisme initial s’accompagne souvent de frustration des utilisateurs. Ici, les choses deviennent un peu personnelles car ces dernières semaines, j’ai été obligé de passer du temps à discuter avec différents chatbots. J’ai tendance à retarder les interactions avec les prestataires de services jusqu’à ce que la situation devienne intenable, et quelques-uns de ces cas se sont accumulés. Les widgets de chatbot souriants sont devenus mon dernier espoir avant un éternel appel à la hotline, mais :
- Après m’être connecté au site de mon assureur automobile, j’ai demandé des explications sur une augmentation de prix inopinée, pour me rendre compte que le chatbot n’avait pas accès à mes données de tarification. Tout ce qu’il pouvait offrir, c’était le numéro d’assistance téléphonique. Aie.
- Après qu’un vol ait été annulé à la dernière minute, j’en ai demandé la raison au chatbot de la compagnie aérienne. Il s’est excusé poliment car, comme l’heure de départ était déjà passée, il ne pouvait pas m’aider. Il était cependant ouvert à discuter de tous les autres sujets.
- Sur un site de télécommunications, j’ai demandé pourquoi mon forfait mobile avait soudainement expiré. Le chatbot a répondu avec confiance qu’il ne pouvait pas commenter les questions contractuelles et m’a renvoyé vers la FAQ. Comme prévu, celles-ci étaient longues mais sans intérêt.
Ces interactions ne m’ont pas rapproché d’une solution et m’ont laissé à l’opposé du plaisir. Les chatbots ressemblaient à des corps étrangers. Assis là, ils consommaient de l’espace, de la latence et de l’attention, mais n’ajoutaient pas de valeur.
Laissons de côté le débat sur la question de savoir s’il s’agit de motifs sombres intentionnels. Le fait est que les systèmes existants comme ceux ci-dessus portent un lourd fardeau d’entropie. Ils contiennent des tonnes de données, de connaissances et de contextes uniques. Dès que vous essayez de les intégrer à un LLM à usage général, vous faites s’affronter deux mondes. Le modèle doit ingérer le contexte de votre produit afin de pouvoir raisonner de manière significative sur votre domaine. Une bonne ingénierie du contexte nécessite des compétences et du temps pour une évaluation et une itération incessantes. Et avant même d’en arriver là, vos données doivent être prêtes, mais dans la plupart des organisations, les données sont bruitées, fragmentées ou tout simplement manquantes.
Dans cet article, je récapitulerai les idées de mon livre L’art du développement de produits IA et ma récente conférence au Sommet Google sur l’IA Web et partager une approche plus organique et progressive de l’intégration de l’IA dans les produits existants.
Utiliser des modèles plus petits pour une intégration incrémentielle et à faible risque de l’IA
« Lors de la mise en œuvre de l’IA, je constate que de plus en plus d’organisations échouent en commençant trop grand plutôt qu’en commençant trop petit. » ( Andrew Ng).
L’intégration de l’IA prend du temps :
- Votre équipe technique doit préparer les données et apprendre les techniques et outils disponibles.
- Vous devez prototyper et itérer pour trouver les points forts de la valeur de l’IA dans votre produit et votre marché.
- Les utilisateurs doivent calibrer leur confiance lorsqu’ils passent à de nouvelles expériences probabilistes.
Pour vous adapter à ces courbes d’apprentissage, vous ne devez pas vous précipiter pour exposer l’IA – en particulier la fonctionnalité de chat ouverte – à vos utilisateurs. L’IA introduit de l’incertitude et des erreurs dans l’expérience, ce que la plupart des gens n’aiment pas.
Un moyen efficace de rythmer votre parcours d’IA dans le contexte des friches industrielles consiste à utiliser des petits modèles de langage (SLM), qui varient généralement de quelques centaines de millions à quelques milliards de paramètres. Ils peuvent s’intégrer de manière flexible aux données et à l’infrastructure existantes de votre produit, plutôt que d’ajouter des frais technologiques supplémentaires.
Comment les SLM sont formés
La plupart des SLM sont dérivés de modèles plus grands grâce à distillation des connaissances. Dans cette configuration, un grand modèle fait office d’enseignant et un plus petit, d’élève. Par exemple, Gemini de Google a servi de professeur pour Gemme 2 et Gemme 3 tandis que le Llama Behemoth de Meta entraînait son troupeau de petits modèles Llama 4. Tout comme un enseignant humain condense des années d’étude en explications claires et en leçons structurées, le grand modèle distille son vaste espace de paramètres en une représentation plus petite et plus dense que l’élève peut absorber. Le résultat est un modèle compact qui conserve une grande partie des compétences de l’enseignant mais fonctionne avec beaucoup moins de paramètres et un coût de calcul considérablement inférieur.

Utiliser les SLM
L’un des principaux avantages des SLM est leur flexibilité de déploiement. Contrairement aux LLM qui sont principalement utilisés via des API externes, les modèles plus petits peuvent être exécutés localement, soit sur l’infrastructure de votre organisation, soit directement sur l’appareil de l’utilisateur :
- Déploiement local: Vous pouvez héberger des SLM sur vos propres serveurs ou dans votre environnement cloud, en gardant un contrôle total sur les données, la latence et la conformité. Cette configuration est idéale pour les applications d’entreprise où les informations sensibles ou les contraintes réglementaires rendent les API tierces peu pratiques.
📈 Le déploiement local vous offre également des opportunités de réglage flexibles à mesure que vous collectez davantage de données et devez répondre aux attentes croissantes des utilisateurs.
- Déploiement sur appareil via le navigateur: Les navigateurs modernes disposent de capacités d’IA intégrées sur lesquelles vous pouvez compter. Par exemple, Chrome intègre Gemini Nano via le API d’IA intégréestandis que Microsoft Edge inclut Phi-4 (voir Documentation rapide de l’API). L’exécution de modèles directement dans le navigateur permet des cas d’utilisation à faible latence et préservant la confidentialité, tels que les suggestions de texte intelligentes, le remplissage automatique de formulaires ou l’aide contextuelle.
Si vous souhaitez en savoir plus sur les aspects techniques des SLM, voici quelques ressources utiles :
Passons maintenant à autre chose et voyons ce que vous pouvez construire avec les SLM pour offrir de la valeur utilisateur et progresser régulièrement dans votre intégration de l’IA.
Opportunités de produits pour les SLM
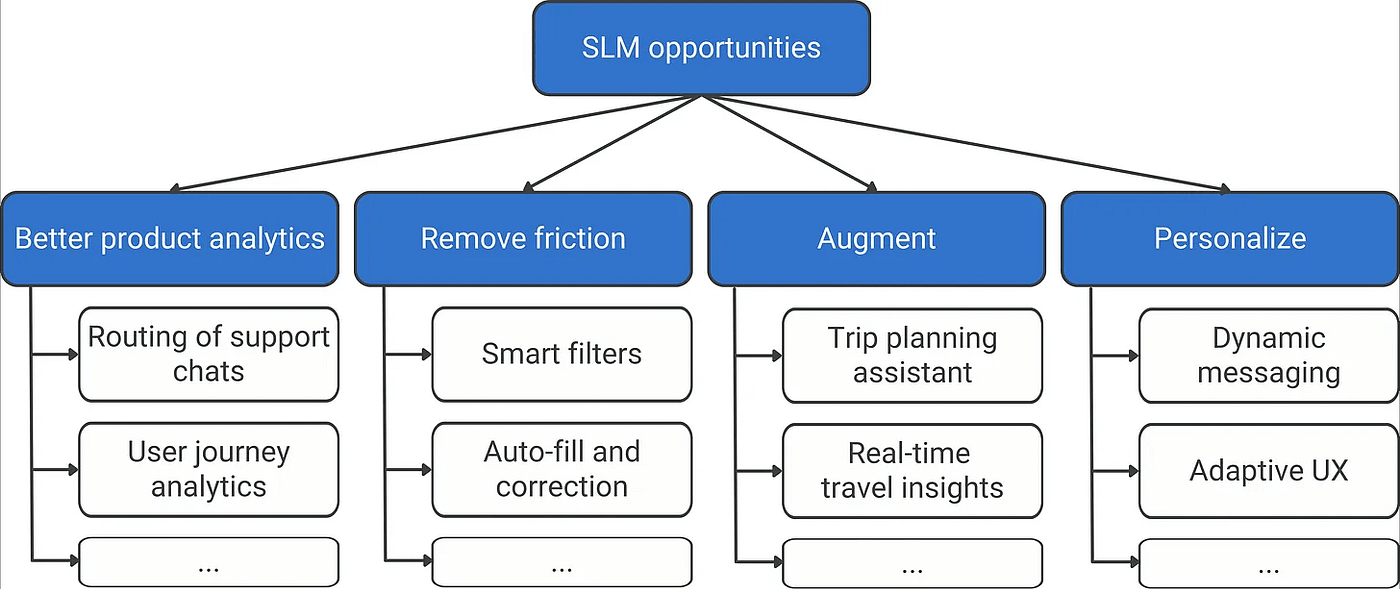
Les SLM brillent dans les tâches ciblées et bien définies où le contexte et les données sont déjà connus – les types de cas d’utilisation qui sont profondément ancrés dans les produits existants. Vous pouvez les considérer comme des renseignements spécialisés intégrés plutôt que comme des assistants à usage général. Passons en revue les principales opportunités qu’ils débloquent dans les friches industrielles, comme illustré dans l’arbre d’opportunités suivant.

1. De meilleures analyses de produits
Avant d’exposer les fonctionnalités de l’IA aux utilisateurs, recherchez des moyens d’améliorer votre produit de l’intérieur. La plupart des produits génèrent déjà un flux continu de texte non structuré : discussions d’assistance, demandes d’aide, commentaires dans l’application. Les SLM peuvent analyser ces données en temps réel et générer des informations qui éclairent à la fois les décisions relatives aux produits et l’expérience utilisateur immédiate. Voici quelques exemples :
- Étiqueter et acheminer les discussions d’assistance au fur et à mesure qu’ils surviennent, en dirigeant les problèmes techniques vers les bonnes équipes.
- Signaler les signaux de désabonnement au cours d’une sessionce qui incite à des interventions opportunes.
- Suggérer du contenu ou des actions pertinentes en fonction du contexte actuel de l’utilisateur.
- Détecter les points de friction répétés pendant que l’utilisateur est toujours dans le flux, et non des semaines plus tard dans une rétrospective.
Ces catalyseurs internes maintiennent les risques à un faible niveau tout en ajoutant de la valeur et en donnant à votre équipe le temps d’apprendre. Ils renforcent votre base de données et vous préparent à des fonctionnalités d’IA plus visibles et destinées aux utilisateurs à l’avenir.
2. Supprimer les frictions
Ensuite, prenez du recul et auditez la dette UX qui existe déjà. Dans les friches industrielles, la plupart des produits ne sont pas exactement le rêve d’un designer. Ils ont été conçus sous les contraintes techniques et architecturales de leur époque. Avec l’IA, nous avons désormais la possibilité de lever certaines de ces contraintes, en réduisant les frictions et en créant des expériences plus rapides et plus intuitives.
Un bon exemple est celui des filtres intelligents sur les sites Web basés sur la recherche comme Booking.com. Traditionnellement, ces pages utilisent de longues listes de cases à cocher et de catégories qui tentent de couvrir toutes les préférences possibles de l’utilisateur. Ils sont lourds à concevoir et à utiliser et, au final, de nombreux utilisateurs ne parviennent pas à trouver le paramètre qui leur tient à cœur.
Le filtrage basé sur la langue change cela. Au lieu de naviguer dans une taxonomie complexe, les utilisateurs saisissent simplement ce qu’ils veulent (par exemple « hôtels acceptant les animaux domestiques près de la plage »), et le modèle le traduit en une requête structurée en coulisses.

Plus largement, recherchez les domaines de votre produit dans lesquels les utilisateurs doivent appliquer votre logique interne (vos catégories, structures ou terminologie) et remplacez-la par une interaction en langage naturel. Chaque fois que les utilisateurs peuvent exprimer directement leur intention, vous supprimez une couche de friction cognitive et rendez le produit plus intelligent et plus convivial.
3. Augmentation
Une fois votre expérience utilisateur désencombrée, il est temps de penser à l’augmentation, en ajoutant de petites fonctionnalités d’IA utiles à votre produit. Au lieu de réinventer l’expérience de base, examinez ce que les utilisateurs font déjà autour de votre produit : les tâches secondaires, les solutions de contournement ou les outils externes sur lesquels ils s’appuient pour atteindre leur objectif. Les modèles d’IA ciblés peuvent-ils les aider à le faire plus rapidement et plus intelligemment ?
Par exemple, une application de voyage pourrait intégrer un générateur de notes de voyage contextuelles qui résume les détails de l’itinéraire ou rédige des messages pour les co-voyageurs. Un outil de productivité pourrait inclure un générateur de récapitulation de réunion qui résume les discussions ou les actions à partir de notes textuelles, sans envoyer de données vers le cloud.
Ces fonctionnalités se développent de manière organique à partir du comportement réel des utilisateurs et étendent le contexte de votre produit au lieu de le redéfinir.
4. Personnalisez
Une personnalisation réussie est le Saint Graal de l’IA. Cela renverse la dynamique traditionnelle : au lieu de demander aux utilisateurs d’apprendre et de s’adapter à votre produit, votre produit s’adapte désormais à eux comme un gant bien ajusté.
Lorsque vous démarrez, gardez vos ambitions à distance : vous n’avez pas besoin d’un assistant entièrement adaptatif. Introduisez plutôt de petits ajustements à faible risque dans ce que voient les utilisateurs, dans la manière dont les informations sont formulées ou dans les options qui apparaissent en premier. Au niveau du contenu, l’IA peut adapter le ton et le style, par exemple en utilisant une formulation concise pour les experts et une formulation plus explicative pour les nouveaux arrivants. Au niveau de l’expérience, il peut créer des interfaces adaptatives. Par exemple, un outil de gestion de projet pourrait faire apparaître les actions les plus pertinentes (« créer une tâche », « partager la mise à jour », « générer un résumé ») en fonction des flux de travail passés de l’utilisateur.
⚠️ Lorsque la personnalisation tourne mal, elle érode rapidement la confiance. Les utilisateurs ont le sentiment d’avoir échangé leurs données personnelles contre une expérience qui ne semble pas meilleure. Ainsi, n’introduisez la personnalisation qu’une fois que vos données sont prêtes à la prendre en charge.
Pourquoi les « petits » gagnent au fil du temps
Chaque fonctionnalité d’IA réussie (qu’il s’agisse d’une amélioration analytique, d’un point de contact UX sans friction ou d’une étape personnalisée dans un flux plus large) renforce votre base de données et développe la force d’itération et les connaissances en IA de votre équipe. Il jette également les bases d’applications ultérieures plus vastes et plus complexes. Lorsque vos « petites » fonctionnalités fonctionnent de manière fiable, elles deviennent des composants réutilisables dans des workflows plus importants ou des systèmes d’agents modulaires (cf. l’article de Nvidia Les petits modèles de langage sont l’avenir de l’IA agentique).
Pour résumer :
✅ Commencez petit — privilégier une amélioration progressive plutôt qu’une perturbation.
✅ Expérimentez rapidement — des modèles plus petits signifient un coût inférieur et des boucles de rétroaction plus rapides.
✅ Soyez prudent — démarrer en interne ; introduisez l’IA orientée utilisateur une fois que vous l’avez validée.
✅ Développez votre muscle d’itération – des progrès constants et composés surpassent les grands projets.
Publié initialement sur https://jannalipenkova.substack.com.
You may also like


