
Google Trends vous induit en erreur : comment faire du machine learning avec les données de Google Trends
. Quel cadeau pour la société. Sans les tendances Google, comment aurions-nous pu savoir cela ? plus de films Disney sortis dans les années 2000 ont entraîné moins de divorces au Royaume-Uni. Ou ça boire du Coca Cola est un remède inconnu contre les griffures de chat.
Attendez, est-ce que je suis encore une fois confus entre corrélation et causalité ?
Si vous préférez regarder plutôt que lire, vous pouvez le faire ici :
Google Trends est l’un des outils les plus utilisés pour analyser le comportement humain à grande échelle. Les journalistes l’utilisent. Les data scientists l’utilisent. Des articles entiers sont construits là-dessus. Mais il existe une propriété fondamentale des données Google Trends qui les rend très faciles à utiliser à mauvais escient, surtout si vous travaillez avec des séries chronologiques ou si vous essayez de créer des modèles, et la plupart des gens ne se rendent jamais compte qu’ils le font.
Tous les graphiques et captures d’écran sont créés par l’auteur, sauf indication contraire.
Le problème avec les données Google Trends
Google ne publie pas réellement de chiffres sur son volume de recherche. Ces informations leur rapportent des dollars et il n’est pas possible qu’ils les ouvrent à d’autres personnes pour qu’elles les monétisent. Mais ce qu’ils nous donnent, c’est un moyen de voir une série chronologique, de comprendre les changements dans les recherches des gens sur un terme particulier et ils le font en nous donnant une ensemble de données normalisé.
Cela ne semble pas être un problème jusqu’à ce que vous essayiez de faire un peu d’apprentissage automatique avec. Parce que lorsqu’il s’agit de faire apprendre quelque chose à une machine, nous devons lui fournir beaucoup de données.
Mon idée initiale était de saisir une fenêtre de cinq ans, mais j’ai immédiatement rencontré un problème : plus la fenêtre temporelle est grande, moins les données sont granulaires. Je n’ai pas pu obtenir de données quotidiennes pendant cinq ans et même si je pensais alors « prenez simplement la période de temps maximale pour laquelle vous pouvez obtenir des données quotidiennes et déplacez cette fenêtre », c’était aussi un problème. Parce que c’est ici que j’ai découvert la véritable terreur de normalisation:
Quelle que soit la période que j’utilise ou quel que soit le terme de recherche que j’utilise, le point de données avec le plus grand nombre de recherches est immédiatement défini sur 100. Cela signifie la signification de 100 changements à chaque fenêtre que j’utilise.
Cet article entier existe pour cette raison.
Les bases de Google Tendances
Maintenant, je ne sais pas si vous avez utilisé Tendances Google avant, mais si ce n’est pas le cas, je vais vous en parler afin que nous puissions aller au fond du problème.
Je vais donc rechercher le mot « motivation » et ce sera par défaut au Royaume-Uni parce que c’est de là que je viens et jusqu’à la veille et nous avons un joli graphique qui montre à quelle fréquence les gens ont recherché le mot « motivation » au cours des dernières 24 heures.

J’aime ça parce que vous pouvez voir très clairement que les gens recherchent principalement de la motivation pendant la journée de travail, personne ne le cherche alors que la majeure partie du pays dort et il y a certainement quelques enfants qui ont besoin d’encouragements pour leurs devoirs. Je n’ai pas d’explication pour les fouilles nocturnes, mais je suppose que ce sont des gens qui ne sont pas prêts à retourner travailler demain.
C’est joli, mais même si des incréments de huit minutes sur 24 heures nous donnent 180 points de données à utiliser, la plupart d’entre eux sont en fait nuls et je ne sais pas si les dernières 24 heures ont été très démotivantes par rapport au reste de l’année ou si aujourd’hui représente la plus forte contribution au PIB de l’année, donc je vais agrandir la fenêtre un petit peu.
Dès que nous passons à une semaine, la première chose que l’on remarque est que les données sont beaucoup moins granulaires. Nous avons une semaine de données mais maintenant ce n’est que toutes les heures et j’ai toujours le même problème fondamental de ne pas savoir quelle représentativité cette semaine c’est le cas.
Je peux continuer à zoomer. 30 jours, 90 jours. À chaque point, nous perdons de la granularité et n’avons pas autant de points de données que pendant 24 heures. Si je veux construire un modèle réel, cela ne suffira pas. Je dois aller grand.
Et lorsque je sélectionne cinq années, c’est là que nous allons rencontrer le problème qui a motivé toute cette vidéo (excusez le jeu de mots, ce n’était pas intentionnel) : je ne peux pas obtenir de données quotidiennes. Et aussi, pourquoi aujourd’hui on n’est plus à 100 ?

C’est là que réside le vrai problème des données de Google Trends
Comme je l’ai mentionné plus tôt, les données de tendances Google sont normalisées. Cela signifie que quelle que soit la période que j’utilise ou quel que soit le terme de recherche que j’utilise, le point de données avec le plus grand nombre de recherches est immédiatement défini sur 100. Tous les autres points sont réduits en conséquence. Si le 1er avril a enregistré la moitié des recherches du maximum, alors le 1er avril aura un score Google Trends de 50.
Alors regardons un exemple ici juste pour illustrer ce point. Prenons les mois de mai et juin 2025, tous deux de 30 ou 31 jours donc nous avons ici des données quotidiennes, nous les perdons effectivement au-delà de 90 jours. Si je regarde le mois de mai, vous pouvez voir que nous avons atteint 100 le 13 et qu’en juin, nous l’avons atteint le 10. Cela signifie-t-il que la motivation a été recherchée aussi souvent le 10 juin que le 13 mai ?


Si je fais un zoom arrière maintenant pour avoir mai et juin sur le même graphique, vous pouvez immédiatement voir que ce n’est pas le cas. Lorsque les deux mois sont inclus, nous constatons que les recherches de motivation avaient un score Google Trends de 83 le 10 juin, ce qui signifie qu’en proportion des recherches au Royaume-Uni, cela représentait 81 % de la proportion des recherches le 13 mai. Si nous ne faisions pas de zoom arrière, nous ne l’aurions pas su.

Maintenant, tout n’est pas perdu, nous avons obtenu pas mal d’informations de cette expérience car nous savons que nous pouvons voir la différence relative entre deux points de données s’ils sont tous deux inclus dans le même graphique, donc si nous chargeons mai et juin séparément, sachant que le 10 juin est 81 % du 13 mai signifie que nous pouvons réduire juin en conséquence et les données seront comparables.
C’est donc ce que j’ai décidé de faire. Je récupèrerais mes données de tendances Google avec un chevauchement d’un jour sur chaque fenêtre, donc du 1er janvier au 31 mars, puis du 31 mars au 31 juillet. Ensuite, je pourrais utiliser la date du 31 mars dans les deux ensembles de données pour mettre à l’échelle le deuxième ensemble afin qu’il soit comparable au premier.
Mais même si c’est proche de quelque chose que nous pouvons utiliser, il y a encore un problème Je dois vous en informer.
Google Trends : une autre couche d’aléatoire
Ainsi, lorsqu’il s’agit de données sur les tendances de Google, Google ne suit pas réellement chaque recherche. Ce serait un cauchemar informatique. Au lieu de cela, Google utilise techniques d’échantillonnage donc de construire une représentation des volumes de recherche.
Cela signifie que même si l’échantillon est probablement très bien construit, il s’agit bien de Google après tout, chaque jour aura quelques variation aléatoire naturelle. Si par hasard le 31 mars était un jour où l’échantillon de Google était inhabituellement élevé ou faible par rapport au monde réel, notre méthode de chevauchement introduirait une erreur dans l’ensemble de notre ensemble de données.
En plus de cela, nous devons également considérer arrondi. Google Trends arrondit tout au nombre entier le plus proche. Il n’y a pas de 50,5, c’est 50 ou c’est 51. Cela semble être un petit détail, mais cela peut en réalité devenir un gros problème. Laissez-moi vous montrer pourquoi.
Le 4 octobre 2021, il y a eu un pointe massive dans les recherches sur Facebook. Ce pic massif est porté à 100 et, par conséquent, tout le reste au cours de cette période est beaucoup plus proche de zéro. Lorsque vous arrondissez au nombre entier le plus proche, cette petite erreur de 0,5 devient soudainement un énorme erreur proportionnelle lorsque votre nombre n’est que 1 ou 2. Cela signifie que notre solution doit être suffisamment robuste pour gérer le bruit, pas seulement la mise à l’échelle.
Alors, comment pouvons-nous résoudre ce problème ? Eh bien, nous savons qu’en moyenne, les échantillons seront représentatifs, donc prenons juste un échantillon plus gros. Si nous utilisons une fenêtre plus grande pour obtenir notre chevauchement, la variation aléatoire et les erreurs d’arrondi ont moins d’impact.
Voici donc le plan final. Je sais que je peux obtenir des données quotidiennes jusqu’à 90 jours. Je vais charger une fenêtre glissante de périodes de 90 jours, mais je veillerai à ce que chaque fenêtre se chevauche d’un mois complet avec la suivante. De cette façon, notre chevauchement n’est pas seulement une journée potentiellement bruyante mais une ancre stable pendant un mois que nous pouvons utiliser pour mettre à l’échelle nos données avec plus de précision.
Il semble donc que nous ayons un plan. J’ai quelques inquiétudes, principalement parce qu’en ayant beaucoup de lots, il y aura des erreurs de composition et cela pourrait entraîner une explosion de grands nombres. Mais pour voir comment cela évolue avec des données réelles nous devons y aller et le faire. En voici donc un que j’ai réalisé plus tôt.
Écrire du code pour comprendre les tendances de Google
Après avoir écrit tout ce dont nous avons discuté sous forme de code et, après avoir pris du plaisir à obtenir temporairement banni à partir des tendances de Google pour extraire trop de données, j’ai rassemblé quelques graphiques. Ma réaction immédiate lorsque j’ai vu cela a été : « Oh non, ça a explosé ».

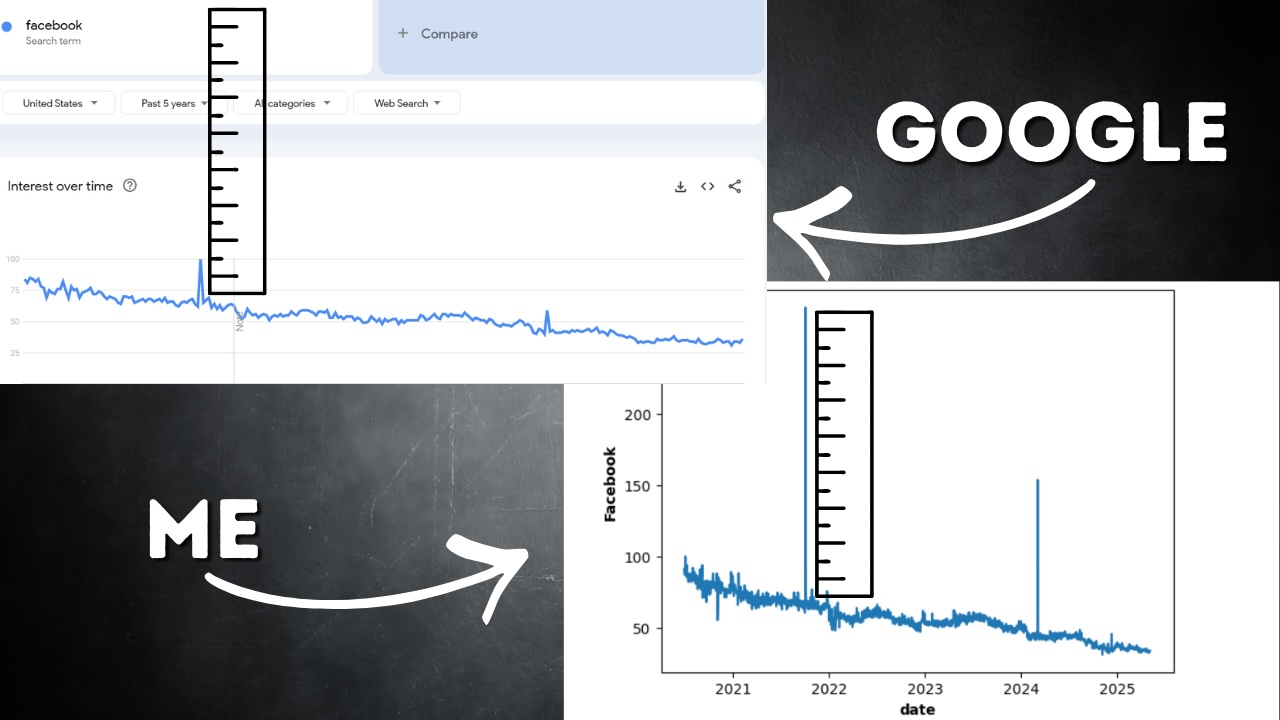
Le graphique ci-dessous montre mes cinq années enchaînées de volumes de recherche pour Facebook. Vous constaterez une tendance à la baisse assez constante, mais deux pics se démarquent. Le premier d’entre eux a été le pic massif du 4 octobre 2021 que nous avons mentionné plus tôt.

Ma première pensée a été de vérifier les pointes. Sans ironie, je l’ai recherché sur Google et j’ai découvert des pannes généralisées de Meta ce jour-là. J’ai extrait des données pour Instagram et Whatsapp sur la même période et j’ai constaté des pics similaires. Je savais donc que le pic était réel mais j’avais quand même une question : Était-ce trop gros ?
Lorsque j’ai mis ma série chronologique côte à côte avec le graphique de Google Trends, mon cœur s’est serré. Mes pointes étaient énormes en comparaison. J’ai commencé à réfléchir à la façon de gérer cela. Dois-je plafonner la valeur maximale du pic ? Cela semblait arbitraire et entraînerait une perte d’informations sur la taille relative des pointes. Dois-je appliquer un facteur d’échelle arbitraire ? Encore, c’était comme une supposition.

C’était jusqu’à ce que j’aie un éclair d’inspiration. N’oubliez pas que Google Trends nous fournit des données hebdomadaires pour cette période, c’est la raison pour laquelle nous faisons cela. Et si je fait la moyenne de mes données pour cette semaine pour voir comment cela se compare à la valeur hebdomadaire de Google ?
C’est là que j’ai poussé un énorme soupir de soulagement. Cette semaine-là a été le plus gros pic sur Google Trends, donc fixé à 100. Lorsque j’ai fait la moyenne de mes données pour la même semaine, J’ai 102,8. Incroyablement proche de Google Trends. Nous terminons également à peu près au même endroit. Cela signifie que les erreurs de composition de ma méthode de mise à l’échelle n’ont pas fait exploser mes données. J’ai quelque chose qui ressemble et se comporte comme les données Google Trends!
Nous disposons désormais d’une méthodologie robuste pour créer une série chronologique quotidienne claire et comparable pour n’importe quel terme de recherche. Ce qui est génial. Mais que se passe-t-il si nous voulons réellement en faire quelque chose d’utile, comme comparer les termes de recherche dans le monde entier Par exemple?
Car si Google Trends vous permet de comparer plusieurs termes de recherche, il ne le permet pas comparaison directe de plusieurs pays. Je peux donc récupérer un ensemble de données sur la motivation pour chaque pays en utilisant la méthode dont nous avons discuté aujourd’hui, mais comment puis-je les rendre comparables ? Facebook fait partie de la solution.
Mais cette solution est celle d’un article de blog ultérieur, dans lequel nous allons construire un « panier de marchandises » pour comparer les pays et voir exactement comment Facebook s’intègre dans tout cela.
Nous avons donc commencé aujourd’hui par nous demander si nous pouvions modéliser la motivation nationale et, en essayant de le faire, nous nous sommes immédiatement heurtés à un mur. Parce que les données quotidiennes de Google Trends sont trompeuses. Ce n’est pas dû à une erreur, mais de par sa conception même. Nous avons trouvé un moyen de résoudre ce problème maintenant, mais dans la vie d’un data scientist, il y a toujours plus de problèmes qui se cachent au coin de la rue.


