
Explorer TabPFN : un modèle de base conçu pour les données tabulaires
Je TabPFN via l’article ICLR 2023 — TabPFN : un transformateur qui résout les petits problèmes de classification tabulaire en une seconde. Le document a présenté TabPFN, un source ouverte modèle de transformateur construit spécifiquement pour les ensembles de données tabulaires, un espace qui n’a pas vraiment bénéficié de l’apprentissage en profondeur et où les modèles d’arbres de décision améliorés par gradient dominent toujours.
À cette époque, TabPFN ne prenait en charge que 1 000 échantillons d’entraînement et 100 fonctionnalités purement numériques, son utilisation dans des contextes réels était donc assez limitée. Au fil du temps, cependant, plusieurs améliorations progressives ont été apportées, notamment TabPFN-2, qui a été introduit en 2025 dans le cadre du document —Prédictions précises sur de petites données avec un modèle de base tabulaire (TabPFN-2).

Plus récemment, OngletPFN-2.5 a été publié et cette version peut gérer près de 100 000 points de données et environ 2 000 fonctionnalités, ce qui la rend assez pratique pour les tâches de prédiction du monde réel. J’ai passé une grande partie de mes années professionnelles à travailler avec des ensembles de données tabulaires, cela a donc naturellement attiré mon intérêt et m’a poussé à approfondir mes recherches. Dans cet article, je donne un aperçu de haut niveau de TabPFN et je présente également une mise en œuvre rapide à l’aide d’un concours Kaggle pour vous aider à démarrer.
Qu’est-ce que TabPFN
TabPFN signifie Réseau ajusté tabulaire de données préalables, un modèle de fondation qui est basé sur l’idée d’adapter un modèle à un avant les ensembles de données tabulaires, plutôt qu’à un seul ensemble de données, d’où son nom.
En lisant les rapports techniques, ces modèles contenaient de nombreux éléments intéressants. Par exemple, TabPFN peut fournir des prédictions tabulaires solides avec une latence très faible, souvent comparable aux méthodes d’ensemble optimisées, mais sans boucles d’entraînement répétées.
Du point de vue du flux de travail, il n’y a pas non plus de courbe d’apprentissage car il s’intègre naturellement dans les configurations existantes grâce à un scikit-learn interface de style. Il peut gérer les valeurs manquantes, les valeurs aberrantes et les types de fonctionnalités mixtes avec un prétraitement minimal que nous aborderons lors de l’implémentation, plus loin dans cet article.
La nécessité d’un modèle de base pour les données tabulaires
Avant d’aborder le fonctionnement de TabPFN, essayons d’abord de comprendre le problème plus large qu’il tente de résoudre.
Avec l’apprentissage automatique traditionnel sur des ensembles de données tabulaires, vous entraînez généralement un nouveau modèle pour chaque nouvel ensemble de données. Cela implique souvent de longs cycles de formation, et cela signifie également qu’un modèle préalablement formé ne peut pas réellement être réutilisé.
Cependant, si l’on regarde les modèles de base du texte et des images, leur idée est radicalement différente. Au lieu de procéder à un recyclage à partir de zéro, une grande quantité de pré-entraînement est effectuée dès le départ sur de nombreux ensembles de données et le modèle résultant peut ensuite être appliqué à de nouveaux ensembles de données sans recyclage dans la plupart des cas.
À mon avis, c’est l’écart que le modèle tente de combler pour les données tabulaires, c’est-à-dire en réduisant le besoin de former un nouveau modèle à partir de zéro pour chaque ensemble de données, ce qui semble être un domaine de recherche prometteur.
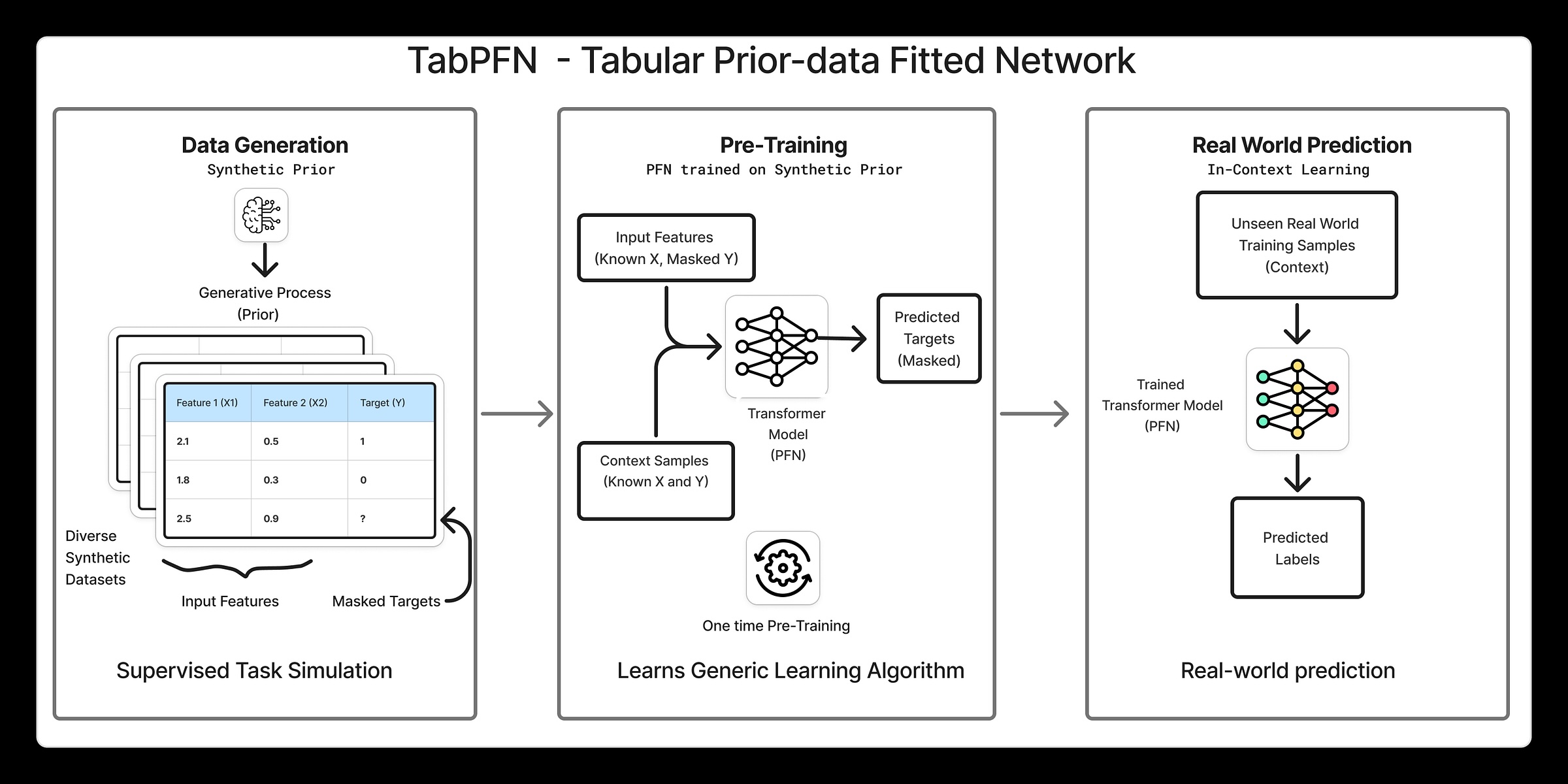
Pipeline de formation et d’inférence TabPFN à un niveau élevé

TabPFN utilise apprentissage en contexte pour adapter un réseau neuronal à un ensemble de données antérieur sur des tableaux. Cela signifie qu’au lieu d’apprendre une tâche à la fois, le modèle apprend à quoi ressemblent généralement les problèmes tabulaires, puis utilise ces connaissances pour faire des prédictions sur de nouveaux ensembles de données en une seule passe. Voici un extrait de TabPFN Nature papier:
TabPFN exploite l’apprentissage en contexte (ICL), le même mécanisme qui a conduit aux performances étonnantes des grands modèles de langage, pour générer un puissant algorithme de prédiction tabulaire entièrement appris. Bien que l’ICL ait été observé pour la première fois dans de grands modèles de langage, des travaux récents ont montré que les transformateurs peuvent apprendre des algorithmes simples tels que la régression logistique via ICL.
Le pipeline peut être divisé en trois étapes principales :
1. Générer des ensembles de données synthétiques
TabPFN traite un ensemble de données entier comme un seul point de données (ou un jeton) introduit dans le réseau. Cela signifie que cela nécessite une exposition à un très grand nombre d’ensembles de données pendant la formation. Pour cette raison, la formation TabPFN commence par ensembles de données tabulaires synthétiques. Pourquoi synthétique ? Contrairement au texte ou aux images, il n’existe pas beaucoup d’ensembles de données tabulaires réels, vastes et diversifiés, ce qui fait des données synthétiques un élément clé de la configuration. Pour mettre les choses en perspective, TabPFN 2 a été formé sur 130 millions d’ensembles de données.
Le processus de génération d’ensembles de données synthétiques est intéressant en soi. TabPFN utilise un modèle hautement paramétrique modèle causal structurel pour créer des ensembles de données tabulaires avec des structures variées, des relations entre les caractéristiques, des niveaux de bruit et des fonctions cibles. En échantillonnant à partir de ce modèle, un ensemble vaste et diversifié d’ensembles de données peut être généré, chacun agissant comme un signal d’entraînement pour le réseau. Cela encourage le modèle à apprendre des modèles généraux sur de nombreux types de problèmes tabulaires, plutôt que de surajuster un seul ensemble de données.
2. Formation
La figure ci-dessous est tirée du Papier naturelmentionné ci-dessus démontre clairement le processus de formation et d’inférence.

Pendant la formation, un ensemble de données tabulaires synthétiques est échantillonné et divisé en train X,Train Y, Test Xet Test Y. Le Test Y les valeurs sont conservées et les parties restantes sont transmises au réseau neuronal qui génère une distribution de probabilité pour chaque Test Y point de données, comme le montre la figure de gauche.
Le tenu Test Y les valeurs sont ensuite évaluées selon ces distributions prédites. UN entropie croisée la perte est ensuite calculée et le réseau est mis à jour pour minimiser cette perte. Cela complète une étape de rétropropagation pour un seul ensemble de données et ce processus est ensuite répété pour des millions d’ensembles de données synthétiques.
3. Inférence
Au moment du test, le modèle TabPFN entraîné est appliqué à un ensemble de données réel. Cela correspond à la figure de droite, où le modèle est utilisé pour l’inférence. Comme vous pouvez le constater, l’interface reste la même que lors de la formation. Vous fournissez Train X, Train Yet Test Xet le modèle génère des prédictions pour Test Y par une seule passe avant.
Plus important encore, il n’y a pas de recyclage au moment du test et TabPFN effectue ce qui est efficace. inférence sans tirproduisant des prédictions immédiatement sans mettre à jour ses poids.
Architecture

Abordons également l’architecture de base du modèle, comme mentionné dans le papier. À un niveau élevé, TabPFN adapte l’architecture du transformateur pour mieux s’adapter aux données tabulaires. Au lieu d’aplatir un tableau en une longue séquence, le modèle traite chaque valeur du tableau comme sa propre unité. Il utilise un mécanisme d’attention en deux étapes dans lequel il apprend d’abord comment les fonctionnalités sont liées les unes aux autres au sein d’une seule ligne, puis apprend comment la même fonctionnalité se comporte sur différentes lignes.
Cette manière de structurer l’attention est vitale car elle correspond à la manière dont les données tabulaires sont réellement organisées. Cela signifie également que le modèle ne se soucie pas de l’ordre des lignes ou des colonnes, ce qui signifie qu’il peut gérer des tables plus grandes que celles sur lesquelles il a été formé.
Mise en œuvre
Passons maintenant en revue une implémentation de OngletPFN-2.5 et compare-le à une vanille XGBoost classificateur pour fournir un point de référence familier. Bien que les poids des modèles puissent être téléchargés à partir de Visage câlinen utilisant Cahiers Kaggle est plus simple puisque le modèle y est facilement disponible et la prise en charge du GPU est prête à l’emploi pour une inférence plus rapide. Dans les deux cas, vous devez accepter les conditions du modèle avant de l’utiliser. Après avoir ajouté le TabPFN modèle dans l’environnement de notebook Kaggle, exécutez la cellule suivante pour l’importer.
# importing the model
import os
os.environ["TABPFN_MODEL_CACHE_DIR"] = "/kaggle/input/tabpfn-2-5/pytorch/default/2"Vous pouvez trouver le code complet dans le carnet Kaggle qui l’accompagne. ici.
Installation
Vous pouvez accéder à TabPFN de deux manières soit en tant que Paquet Python et exécutez-le localement ou en tant que Client API pour exécuter le modèle dans le cloud :
# Python package
pip install tabpfn
# As an API client
pip install tabpfn-clientEnsemble de données : ensemble de données de la compétition Kaggle Playground
Pour avoir une meilleure idée des performances de TabPFN dans un contexte réel, je l’ai testé lors d’un concours Kaggle Playground qui s’est terminé il y a quelques mois. La tâche, Prédiction binaire avec un ensemble de données de précipitations (licence MIT), nécessite de prédire la probabilité de pluie pour chaque id dans l’ensemble de test. L’évaluation se fait à l’aide ROC-AUCce qui en fait un bon choix pour les modèles basés sur les probabilités comme TabPFN. Les données d’entraînement ressemblent à ceci :
Formation d’un classificateur TabPFN
La formation TabPFN Classifier est simple et suit un modèle familier scikit-apprendre interface de style. Même s’il n’existe pas de formation spécifique à des tâches au sens traditionnel du terme, il n’en reste pas moins important de permettre Prise en charge des GPUsinon l’inférence peut être sensiblement plus lente. L’extrait de code suivant explique la préparation des données, la formation d’un classificateur TabPFN et l’évaluation de ses performances à l’aide du score ROC-AUC.
# Importing necessary libraries
from tabpfn import TabPFNClassifier
import pandas as pd, numpy as np
from sklearn.model_selection import train_test_split
# Select feature columns
FEATURES = [c for c in train.columns if c not in ["rainfall",'id']]
X = train[FEATURES].copy()
y = train["rainfall"].copy()
# Split data into train and validation sets
train_index, valid_index = train_test_split(
train.index,
test_size=0.2,
random_state=42
)
x_train = X.loc[train_index].copy()
y_train = y.loc[train_index].copy()
x_valid = X.loc[valid_index].copy()
y_valid = y.loc[valid_index].copy()
# Initialize and train TabPFN
model_pfn = TabPFNClassifier(device=["cuda:0", "cuda:1"])
model_pfn.fit(x_train, y_train)
# Predict class probabilities
probs_pfn = model_pfn.predict_proba(x_valid)
# # Use probability of the positive class
pos_probs = probs_pfn[:, 1]
# # Evaluate using ROC AUC
print(f"ROC AUC: {roc_auc_score(y_valid, pos_probs):.4f}")
-------------------------------------------------
ROC AUC: 0.8722Ensuite, formons un classificateur XGBoost de base.
Entraîner un classificateur XGBoost
from xgboost import XGBClassifier
# Initialize XGBoost classifier
model_xgb = XGBClassifier(
objective="binary:logistic",
tree_method="hist",
device="cuda",
enable_categorical=True,
random_state=42,
n_jobs=1
)
# Train the model
model_xgb.fit(x_train, y_train)
# Predict class probabilities
probs_xgb = model_xgb.predict_proba(x_valid)
# Use probability of the positive class
pos_probs_xgb = probs_xgb[:, 1]
# Evaluate using ROC AUC
print(f"ROC AUC: {roc_auc_score(y_valid, pos_probs_xgb):.4f}")
------------------------------------------------------------
ROC AUC: 0.8515Comme vous pouvez le constater, TabPFN fonctionne plutôt bien dès le départ. Bien que XGBoost puisse certainement être optimisé davantage, mon intention ici est de comparer implémentations de base, vanille plutôt que des modèles optimisés. Cela m’a placé au 22e rang du classement public. Vous trouverez ci-dessous les 3 meilleurs scores pour référence.

Qu’en est-il de l’explicabilité du modèle ?
Les modèles de transformateur ne sont pas intrinsèquement interprétables et, par conséquent, pour comprendre les prédictions, des techniques d’interprétabilité post-hoc telles que SHAP (SHapley Additive Explanations) sont couramment utilisées pour analyser les prédictions individuelles et les contributions aux fonctionnalités. TabPFN fournit un Extension d’interprétabilité qui s’intègre à SHAP, ce qui facilite l’inspection et le raisonnement sur les prédictions du modèle. Pour y accéder, vous devrez d’abord installer l’extension :
# Install the interpretability extension:
pip install "tabpfn-extensions[interpretability]"
from tabpfn_extensions import interpretability
# Calculate SHAP values
shap_values = interpretability.shap.get_shap_values(
estimator=model_pfn,
test_x=x_test[:50],
attribute_names=FEATURES,
algorithm="permutation",
)
# Create visualization
fig = interpretability.shap.plot_shap(shap_values)
Le tracé de gauche montre le importance moyenne des fonctionnalités SHAP sur l’ensemble de l’ensemble de données, donnant une vue globale des fonctionnalités les plus importantes pour le modèle. Le tracé de droite est un Résumé SHAP (essaim d’abeilles)qui fournit une vue plus granulaire en affichant les valeurs SHAP pour chaque fonctionnalité dans les prédictions individuelles.
D’après les tracés ci-dessus, il est évident que couverture nuageuse, soleil, humiditéet point de rosée ont l’impact global le plus important sur les prévisions du modèle, tandis que des caractéristiques telles que la direction du vent, la pression et les variables liées à la température jouent un rôle comparativement moindre.
Il est important de noter que SHAP explique les relations apprises du modèle, et non la causalité physique.
Conclusion
Il y a beaucoup plus dans TabPFN que ce que j’ai couvert dans cet article. Ce que j’ai personnellement aimé, c’est à la fois l’idée sous-jacente et la facilité de démarrage. Il y a de nombreux aspects que je n’ai pas abordés ici, tels que l’utilisation de TabPFN dans la prévision de séries chronologiques, la détection d’anomalies, la génération de données tabulaires synthétiques et l’extraction d’intégrations à partir de modèles TabPFN.
Un autre domaine qui m’intéresse particulièrement est celui du réglage fin, où ces modèles peuvent être adaptés aux données d’un domaine spécifique. Cela dit, cet article se voulait une introduction légère basée sur ma première expérience pratique. Je prévois d’explorer ces capacités supplémentaires plus en profondeur dans les prochains articles. Pour l’instant, le fonctionnaire documentation est un bon endroit pour plonger plus profondément.
Remarque : Toutes les images, sauf indication contraire, sont créées par l’auteur.


