
Des « ralentissements de données » aux flux de données : la révolution des performances Gen2 dans Microsoft Fabric
Parmi les annonces faites lors de la récente FabCon Europe à Vienne, celle qui aurait pu passer inaperçue concernait l’amélioration des performances et l’optimisation des coûts pour Dataflows Gen2.
Avant d’expliquer l’impact de ces améliorations sur votre configuration Dataflows actuelle, prenons du recul et donnons un bref aperçu de Dataflows. Pour ceux d’entre vous qui découvrent Microsoft Fabric, un Dataflow Gen2 est l’élément Fabric sans code/low code utilisé pour extraire, transformer et charger les données (ETL).
Un Dataflow Gen2 offre de nombreux avantages :
- Tirez parti de plus de 100 connecteurs intégrés pour extraire les données d’une myriade de sources de données
- Tirez parti d’une interface graphique familière de Power Query pour appliquer des dizaines de transformations aux données sans écrire une seule ligne de code – un rêve devenu réalité pour de nombreux développeurs citoyens
- Stockez le résultat de la transformation des données sous forme de table delta dans OneLake, afin que les données transformées puissent être utilisées en aval par différents moteurs Fabric (Spark, T-SQL, Power BI…)
Cependant, la simplicité a généralement un coût. Dans le cas de Dataflows, le coût était nettement supérieur à la consommation de CU par rapport aux solutions axées sur le code, telles que les notebooks Fabric et/ou les scripts T-SQL. Cela a déjà été bien expliqué et examiné dans deux excellents articles de blog rédigés par mes collègues MVP, Gilbert Quevauvilliers (Fourmoo) : Comparaison de Dataflow Gen2 et Notebook sur les coûts et la convivialitéet Stepan Resl : Activité de copie, flux de données Gen2 et blocs-notes par rapport aux listes SharePointdonc je ne perdrai pas de temps à discuter du passé. Concentrons-nous plutôt sur ce que le présent (et le futur) apporte à Dataflows !
Modifications du modèle de tarification

Examinons brièvement ce qui est affiché dans l’illustration ci-dessus. Auparavant, chaque seconde d’exécution de Dataflow Gen2 était facturée à 16 CU (CU signifie Capacité Unité, représentant un ensemble regroupé de ressources (CPU, mémoire et E/S) utilisées en synergie pour effectuer une opération spécifique.). En fonction de la taille de la capacité Fabric, vous obtenez un certain nombre d’unités de capacité : F2 fournit 2 CU, F4 fournit 4 CU, et ainsi de suite.
Pour revenir à notre scénario Dataflows, décomposons cela en utilisant un exemple concret. Supposons que vous disposiez d’un Dataflow qui s’exécute pendant 20 minutes (1 200 secondes)…
- Auparavant, cette exécution de Dataflow vous aurait coûté 19.200 UC: 1200 secondes * 16 UC
- Désormais, cette exécution de Dataflow vous coûtera 8.100 UC: 600 secondes (10 premières minutes) * 12 CU + 600 secondes (après les 10 premières minutes) * 1,5 CU
Plus votre Dataflow doit s’exécuter longtemps, plus vous réalisez potentiellement d’économies en CU.
C’est incroyable en soi, mais il y a encore plus à cela. Je veux dire, c’est bien d’être facturé moins cher pour la même quantité de travail, mais et si nous pouvions réaliser ces 1 200 secondes, disons 800 secondes ? Ainsi, cela ne nous permettrait pas seulement d’économiser des UC, mais réduirait également le temps d’analyse, puisque les données auraient été traitées plus rapidement. Et c’est exactement l’objectif des deux prochaines améliorations…
Évaluateur moderne
La nouvelle fonctionnalité d’aperçu, nommée Modern Evaluator, permet d’utiliser le nouveau moteur d’exécution de requêtes (exécuté sur .NET Core version 8) pour exécuter des flux de données. Selon le documents Microsoft officielsLes flux de données exécutant l’évaluateur moderne peuvent offrir les avantages suivants :
- Exécution plus rapide du flux de données
- Un traitement plus efficace
- Évolutivité et fiabilité

L’illustration ci-dessus montre les différences de performances entre les différentes « versions » de Dataflow. Ne vous inquiétez pas, nous testerons bientôt ces chiffres dans une démo, et je vous montrerai également comment activer ces dernières améliorations dans vos charges de travail Fabric.
Calcul partitionné
Auparavant, une logique Dataflow était exécutée en séquence. Par conséquent, en fonction de la complexité logique, l’exécution de certaines opérations pouvait prendre un certain temps, de sorte que d’autres opérations du flux de données devaient attendre dans la file d’attente. Avec le Fonctionnalité de calcul partitionnéDataflow peut désormais exécuter des parties de la logique de transformation en parallèle, réduisant ainsi le temps global d’exécution.
À l’heure actuelle, il existe certaines limitations quant au moment où le calcul partitionné démarrera. À savoir, seuls les connecteurs ADLS Gen2, Fabric Lakehouse, Folder et Azure Blob Storage peuvent exploiter cette nouvelle fonctionnalité. Encore une fois, nous explorerons son fonctionnement plus loin dans cet article.
3, 2, 1…Action !
Ok, il est temps de remettre en question les chiffres fournis par Microsoft et de vérifier si (et dans quelle mesure) il existe un gain de performances entre les différents types de Dataflows.
Voici notre scénario : j’ai généré 50 fichiers CSV contenant des données factices sur les commandes. Chaque fichier contient environ 575 000 enregistrements, il y a donc env. 29 millions d’enregistrements au total (environ 2,5 Go de données). Tous les fichiers sont déjà stockés dans le dossier SharePoint, ce qui permet une comparaison équitable, car Dataflow Gen1 ne prend pas en charge OneLake Lakehouse comme source de données.

Je prévois d’exécuter deux séries de tests : premièrement, inclure le Dataflow Gen1 dans la comparaison. Dans ce scénario, je n’écrirai pas les données dans OneLake à l’aide de Dataflows Gen2 (oui, je sais, cela va à l’encontre de l’objectif de Dataflow Gen2), car je souhaite comparer « des pommes avec des pommes » et exclure le temps nécessaire à l’écriture des données dans OneLake. Je vais tester les quatre scénarios suivants, dans lesquels j’effectue quelques opérations de base pour combiner et charger les données, en appliquant quelques transformations de base (renommer les colonnes, etc.) :
- Utiliser Dataflow Gen1 (l’ancien flux de données Power BI)
- Utiliser Dataflow Gen2 sans aucune amélioration d’optimisation supplémentaire
- Utiliser Dataflow Gen2 avec uniquement l’évaluateur Modern activé
- Utiliser Dataflow Gen2 avec l’évaluateur moderne et le calcul partitionné activés
Dans la deuxième série, je comparerai uniquement trois versions de Dataflow Gen2 (points 2 à 4 de la liste ci-dessus), avec l’écriture des données dans un Lakehouse activée.
Commençons !
Flux de données Gen1
L’ensemble du processus de transformation dans l’ancien Dataflow Gen1 est assez basique : j’ai simplement combiné les 50 fichiers en une seule requête, divisé les colonnes par délimiteur et renommé les colonnes. Donc, rien de vraiment avancé ne se passe ici :

Le même ensemble d’opérations/transformations a été appliqué aux trois Dataflows Gen2.
Veuillez garder à l’esprit qu’avec Dataflow Gen1, il n’est pas possible de générer les données sous forme de table Delta dans OneLake. Toutes les transformations sont conservées dans le flux de données lui-même. Ainsi, lorsque vous avez besoin de ces données, par exemple dans le modèle sémantique, vous devez prendre en compte le temps et les ressources nécessaires pour charger/actualiser les données dans le modèle sémantique du mode d’importation. Mais nous en reparlerons plus tard.
Dataflow Gen2 sans améliorations
Faisons maintenant la même chose, mais cette fois en utilisant le nouveau Dataflow Gen2. Dans ce premier scénario, je n’ai appliqué aucune de ces nouvelles fonctionnalités d’optimisation des performances.

Dataflow Gen2 avec un évaluateur moderne
Ok, le moment de vérité : activons maintenant Modern Evaluator pour Dataflow Gen2. Je vais dans les Options, puis sous l’onglet Échelle, cochez la case Autoriser l’utilisation du moteur d’évaluation de requête moderne :

Tout le reste reste exactement le même que dans le cas précédent.
Dataflow Gen2 avec évaluateur moderne et calcul partitionné
Dans le dernier exemple, j’activerai les deux nouvelles fonctionnalités d’optimisation dans les options de Dataflow Gen2 :

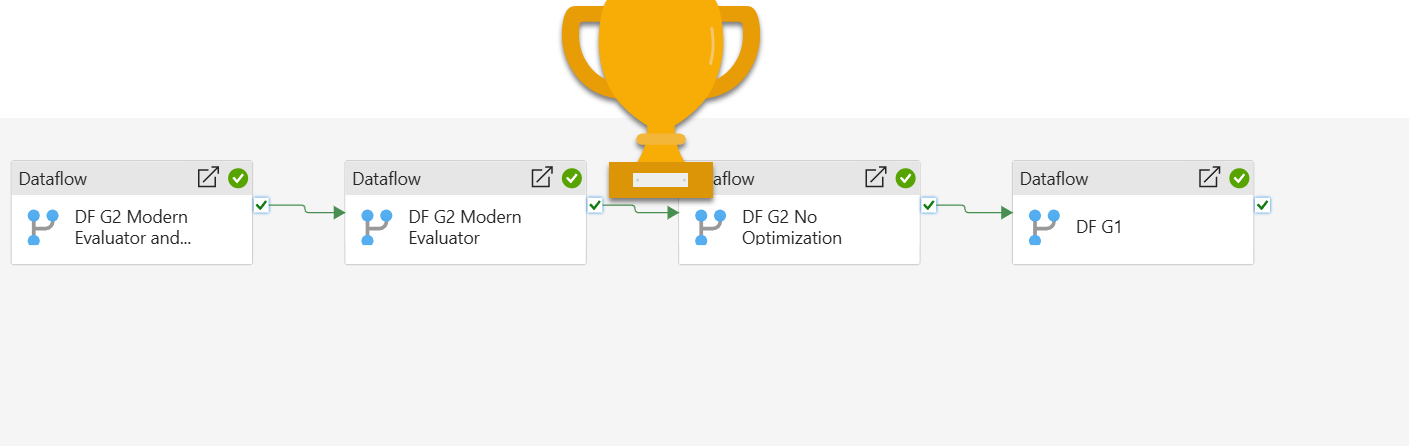
Passons maintenant aux tests et à l’analyse des résultats. J’exécuterai les quatre flux de données en séquence à partir du pipeline Fabric, afin que nous puissions être sûrs que chacun d’eux s’exécute indépendamment des autres.

Et voici les résultats :

Le partitionnement n’a évidemment pas beaucoup compté dans ce scénario particulier, et j’examinerai plus en détail son fonctionnement dans l’un des articles suivants, avec différents scénarios en place. Dataflow Gen2 avec Modern Evaluator activé a surpassé de loin tous les autresréalisant 30 % d’économies par rapport à l’ancien Dataflow Gen1 et ca. 20 % de gain de temps par rapport au Dataflow Gen2 classique sans aucune optimisation ! N’oubliez pas que ces économies se reflètent également dans les économies de CU, donc le coût final estimé en CU pour chacune des solutions utilisées est le suivant :
- Dataflow Gen1 : 550 secondes * 12 CU = 6 600 CU
- Dataflow Gen2 sans optimisation : 520 secondes * 12 CU = 6 240 CU
- Dataflow Gen2 avec Modern Evaluator : 368 secondes * 12 CU = 4 416 CU
- Dataflow Gen2 avec Modern Evaluator et partitionnement : 474 secondes * 12 CU = 5,688 CU
Cependant, je voulais revérifier et confirmer que mon calcul est exact. Par conséquent, j’ai ouvert l’application Capacity Metrics et j’ai jeté un œil aux métriques capturées par l’application :

Bien que le résultat global reflète avec précision les chiffres affichés dans le journal d’exécution du pipeline, le nombre exact de CU utilisées dans l’application est différent :
- Flux de données Gen1 : 7 788 UC
- Dataflow Gen2 sans optimisation : 5 684 CU
- Dataflow Gen2 avec Modern Evaluator : 3 565 CU
- Dataflow Gen2 avec évaluateur moderne et partitionnement : 4 732 CU
Ainsi, selon l’application Capacity Metrics, un Dataflow Gen2 avec Modern Evaluator activé a consommé moins de 50 % de la capacité par rapport au Dataflow Gen1 dans ce scénario particulier ! Je prévois de créer davantage de cas d’utilisation de tests dans les jours/semaines suivants et de fournir une série plus complète de tests et de comparaisons, qui incluront également un temps pour écrire les données dans OneLake (à l’aide de Dataflows Gen2) par rapport au temps nécessaire pour actualiser le modèle sémantique du mode d’importation qui utilise l’ancien Dataflow Gen1.
Conclusion
Comparés à d’autres options (code d’abord), les flux de données étaient (à juste titre ?) considérés comme « l’option la plus lente et la moins performante » pour l’ingestion de données dans Power BI/Microsoft Fabric. Cependant, les choses évoluent rapidement dans le monde Fabric et j’aime la façon dont l’équipe Fabric Data Integration apporte des améliorations constantes au produit. Honnêtement, je suis curieux de voir comment les performances et les coûts de Dataflows Gen2 évoluent au fil du temps, afin que nous puissions envisager d’exploiter Dataflows non seulement pour les exigences d’ingestion de données low-code/no-code et de transformation de données, mais également comme une alternative viable aux solutions code-first du point de vue coût/performance.
Merci d’avoir lu!
Clause de non-responsabilité: Je n’ai aucune affiliation avec Microsoft (sauf en tant que MVP Microsoft Data Platform) et je n’ai pas été approché/parrainé par Microsoft pour écrire cet article.


