
De 4 semaines à 45 minutes : conception d’un système d’extraction de documents pour plus de 4 700 PDF
et m’a demandé si je pouvais aider à extraire les numéros de révision de plus de 4 700 fichiers PDF de dessins techniques. Ils migraient vers un nouveau système de gestion des actifs et avaient besoin de la valeur REV actuelle de chaque dessin, un petit champ enfoui dans le cartouche de chaque document. L’alternative était une équipe d’ingénieurs ouvrant chaque PDF un par un, localisant le cartouche et saisissant manuellement la valeur dans une feuille de calcul. À raison de deux minutes par dessin, cela représente environ 160 heures-personnes. Quatre semaines de temps d’ingénieur. À des tarifs à pleine charge d’environ 50 £ de l’heure, cela représente plus de 8 000 £ de coûts de main-d’œuvre pour une tâche qui ne produit aucune valeur technique au-delà du remplissage d’une colonne de feuille de calcul.
Ce n’était pas un problème d’IA. Il s’agissait d’un problème de conception de systèmes avec de réelles contraintes : budget, exigences de précision, formats de fichiers mixtes et une équipe qui avait besoin de résultats fiables. L’IA était un élément de la solution. Ce sont les décisions techniques qui ont permis au système de fonctionner réellement.
La complexité cachée des PDF « simples »
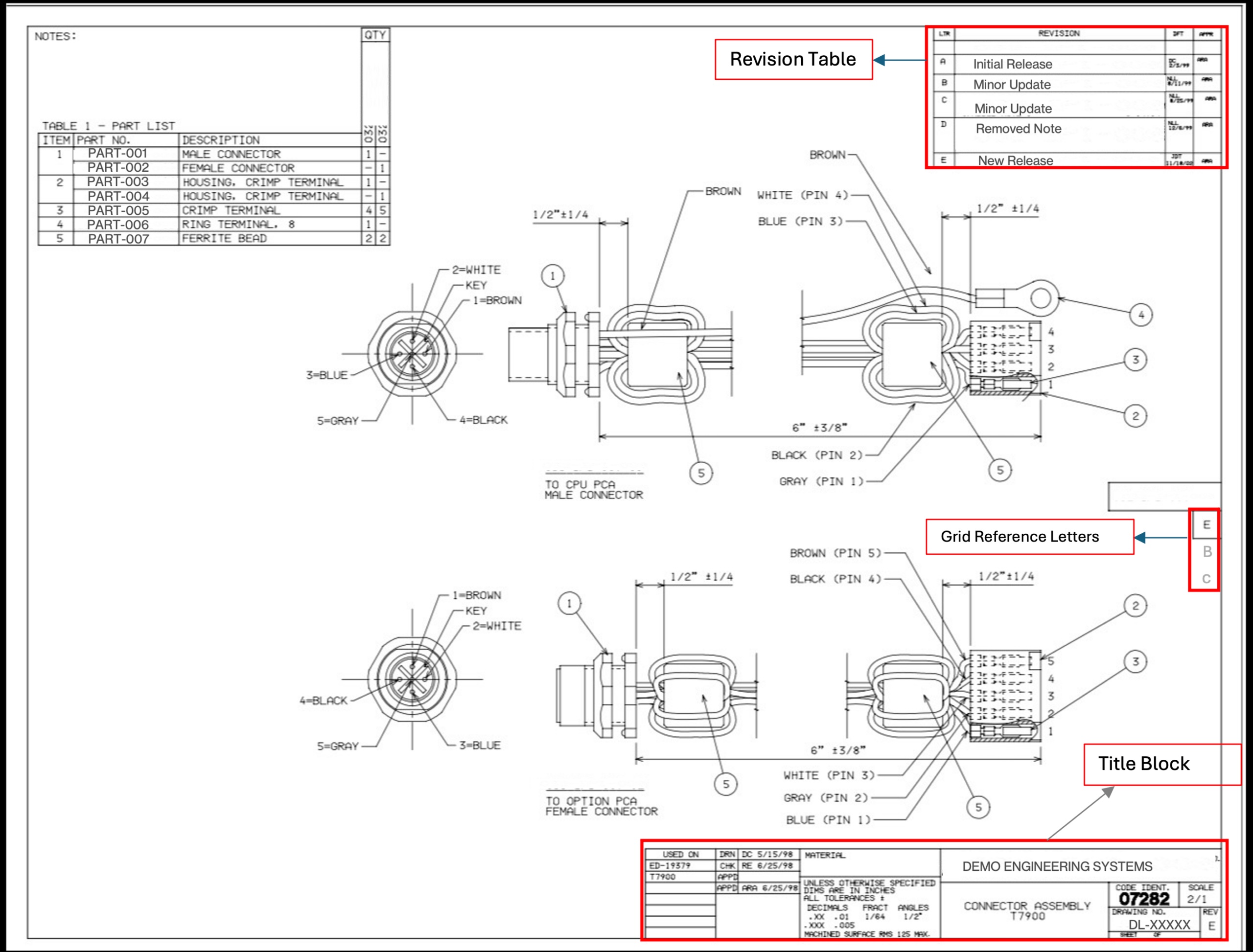
Les dessins techniques ne sont pas des PDF ordinaires. Certains ont été créés dans un logiciel de CAO et exportés sous forme de PDF texte où vous pouvez extraire du texte par programme. D’autres, en particulier des dessins hérités des années 1990 et du début des années 2000, ont été numérisés à partir d’originaux papier et enregistrés sous forme de fichiers PDF basés sur des images. La page entière est une image raster plate sans aucun calque de texte.

Notre corpus était composé à environ 70 à 80 % de texte et à 20 à 30 % d’images. Mais même le sous-ensemble basé sur du texte était traître. Les valeurs REV apparaissaient dans au moins quatre formats : des versions numériques avec trait d’union comme 1-0, 2-0 ou 5-1 ; des lettres simples comme A, B, C ; des lettres doubles comme AA ou AB ; et parfois des champs vides ou manquants. Certains dessins ont été pivotés de 90 ou 270 degrés. Beaucoup avaient des tableaux d’historique de révision (journaux de modifications à plusieurs lignes) juste à côté du champ REV actuel, ce qui est un piège évident de faux positifs. Les lettres de référence de grille le long de la bordure du dessin pourraient facilement être confondues avec des révisions à une seule lettre.
Pourquoi une approche entièrement IA était le mauvais choix
Vous pouvez lancer chaque document sur GPT-4 Vision et l’appeler un jour, mais à environ 0,01 $ par image et 10 secondes par appel, cela représente 47 $ et près de 100 minutes de temps API. Plus important encore, vous paieriez pour une inférence coûteuse sur des documents où quelques lignes de Python pourraient extraire la réponse en millisecondes.
La logique était simple : si un document contient du texte extractible et que la valeur REV suit des modèles prévisibles, il n’y a aucune raison d’impliquer un LLM. Enregistrez le modèle pour les cas où les méthodes déterministes échouent.
L’architecture hybride qui a fonctionné

Étape 1 : extraction PyMuPDF (déterministe, coût nul). Pour chaque PDF, nous tentons une extraction basée sur des règles à l’aide de PyMuPDF. La logique se concentre sur le quadrant inférieur droit de la page, où se trouvent les cartouches, et recherche le texte à proximité des ancres connues telles que « REV », « DWG NO », « SHEET » et « SCALE ». Une fonction de notation classe les candidats en fonction de leur proximité avec ces ancres et de leur conformité aux formats REV connus.
def extract_native_pymupdf(pdf_path: Path) -> Optional[RevResult]:
"""Try native PyMuPDF text extraction with spatial filtering."""
try:
best = process_pdf_native(
pdf_path,
brx=DEFAULT_BR_X, # bottom-right X threshold
bry=DEFAULT_BR_Y, # bottom-right Y threshold
blocklist=DEFAULT_REV_2L_BLOCKLIST,
edge_margin=DEFAULT_EDGE_MARGIN
)
if best and best.value:
value = _normalize_output_value(best.value)
return RevResult(
file=pdf_path.name,
value=value,
engine=f"pymupdf_{best.engine}",
confidence="high" if best.score > 100 else "medium",
notes=best.context_snippet
)
return None
except Exception:
return None
La liste de blocage filtre les faux positifs courants : marqueurs de section, références de grille, indicateurs de page. En limitant la recherche à la région du cartouche, les fausses correspondances étaient proches de zéro.
Étape 2 : GPT-4 Vision (pour tout ce que l’étape 1 manque). Lorsque l’extraction native revient vide, soit parce que le PDF est basé sur une image, soit parce que la mise en page du texte est trop ambiguë, nous rendons la première page au format PNG et l’envoyons à GPT-4 Vision via Azure OpenAI.
def pdf_to_base64_image(self, pdf_path: Path, page_idx: int = 0,
dpi: int = 150) -> Tuple[str, int, bool]:
"""Convert PDF page to base64 PNG with smart rotation handling."""
rotation, should_correct = detect_and_validate_rotation(pdf_path)
with fitz.open(pdf_path) as doc:
page = doc[page_idx]
pix = page.get_pixmap(matrix=fitz.Matrix(dpi/72, dpi/72), alpha=False)
if rotation != 0 and should_correct:
img_bytes = correct_rotation(pix, rotation)
return base64.b64encode(img_bytes).decode(), rotation, True
else:
return base64.b64encode(pix.tobytes("png")).decode(), rotation, False
Nous avons opté pour 150 DPI après les tests. Des résolutions plus élevées ont gonflé la charge utile et ralenti les appels d’API sans améliorer la précision. Les résolutions inférieures ont perdu des détails sur les numérisations marginales.
Qu’est-ce qui s’est cassé dans la production
Deux catégories de problèmes ne sont apparues que lorsque nous avons parcouru le corpus complet de 4 700 documents.
Ambiguïté de rotation. Les dessins techniques sont fréquemment stockés en orientation paysage, mais les métadonnées PDF codant cette orientation varient énormément. Certains fichiers définissent /Rotate correctement. D’autres font physiquement pivoter le contenu mais laissent les métadonnées à zéro. Nous avons résolu ce problème avec une heuristique : si PyMuPDF peut extraire plus de dix blocs de texte de la page non corrigée, l’orientation est probablement correcte, indépendamment de ce que disent les métadonnées. Sinon, nous appliquons la correction avant l’envoi vers GPT-4 Vision.
Hallucination rapide. Le modèle s’accrochait parfois aux valeurs des propres exemples de l’invite au lieu de lire le dessin réel. Si chaque exemple montrait REV « 2-0 », le modèle développait un biais vers la sortie « 2-0 » même lorsque le dessin montrait clairement « A » ou « 3-0 ». Nous avons résolu ce problème de deux manières : nous avons diversifié les exemples dans tous les formats valides avec des avertissements anti-mémorisation explicites, et nous avons ajouté des instructions claires distinguant la table de l’historique des révisions (journal des modifications sur plusieurs lignes) du champ REV actuel (valeur unique dans le cartouche).
CRITICAL RULES - AVOID THESE:
✗ DO NOT extract from REVISION HISTORY TABLES
(columns: REV | DESCRIPTION | DATE)
- We want the CURRENT REV from title block (single value)
✗ DO NOT extract grid reference letters (A, B, C along edges)
✗ DO NOT extract section markers ("SECTION C-C", "SECTION B-B")
Résultats et compromis
Nous avons validé sur un échantillon de 400 fichiers avec une vérité terrain vérifiée manuellement.
| Métrique | Hybride (PyMuPDF + GPT-4) | GPT-4 uniquement |
| Précision (n=400) | 96% | 98% |
| Temps de traitement (n = 4 730) | ~45 minutes | ~100 minutes |
| Coût de l’API | ~10-15$ | ~ 47 $ (tous les fichiers) |
| Taux d’évaluation humaine | ~5% | ~1% |
L’écart de précision de 2 % était le prix d’une réduction du temps d’exécution de 55 minutes et de coûts limités. Pour une migration de données où les ingénieurs vérifieraient de toute façon un pourcentage de valeurs, un taux de 96 % avec un taux de signalement pour révision de 5 % était acceptable. Si le cas d’utilisation avait été la conformité réglementaire, nous aurions exécuté GPT-4 sur chaque fichier.
Nous avons ensuite comparé les modèles plus récents, y compris GPT-5+, au même ensemble de validation de 400 fichiers. La précision était comparable à GPT-4.1 à 98 %. Les modèles les plus récents n’offraient aucun avantage significatif pour cette tâche d’extraction, avec un coût par appel plus élevé et une inférence plus lente. Nous avons expédié GPT-4.1. Lorsque la tâche consiste à faire correspondre des modèles spatialement contraints dans une région de document bien définie, le plafond est l’invite et le prétraitement, et non la capacité de raisonnement du modèle.
Dans le travail de production, le « bon » objectif de précision n’est pas toujours le plus élevé que vous puissiez atteindre. C’est celui qui équilibre le coût, la latence et le flux de travail en aval qui dépend de votre sortie.
Du script au système
Le livrable initial était un outil en ligne de commande : alimentez-le en un dossier de PDF et obtenez un CSV de résultats. Il s’est exécuté dans notre environnement Microsoft Azure, en utilisant les points de terminaison Azure OpenAI pour les appels GPT-4 Vision.
Une fois la migration initiale réussie, les parties prenantes ont demandé si d’autres équipes pouvaient l’utiliser. Nous avons enveloppé le pipeline dans une application Web interne légère avec une interface de téléchargement de fichiers, afin que les utilisateurs non techniques puissent exécuter des extractions à la demande sans toucher à un terminal. Le système a depuis été adopté par des équipes d’ingénierie sur plusieurs sites de l’organisation, chacune exploitant ses propres archives de dessins pour les tâches de migration et d’audit. Je ne peux pas partager de captures d’écran pour des raisons de confidentialité, mais la logique d’extraction principale est identique à celle que j’ai décrite ici.
Leçons pour les praticiens
Commencez par la méthode viable la moins chère. L’instinct lorsque l’on travaille avec les LLM est de les utiliser pour tout. Résistez-y. L’extraction déterministe a traité 70 à 80 % de notre corpus à un coût nul. Le LLM n’a ajouté de la valeur que parce que nous l’avons concentré sur les cas où les règles n’étaient pas à la hauteur.
Validez à grande échelle, et non sur des échantillons triés sur le volet. L’ambiguïté de rotation, la confusion dans la table d’historique des révisions, les faux positifs de référence dans la grille. Aucun de ces éléments n’est apparu dans notre ensemble de tests initial de 20 fichiers. Votre ensemble de validation doit représenter la distribution réelle des cas extrêmes que vous verrez en production.
L’ingénierie rapide est l’ingénierie logicielle. L’invite du système a subi plusieurs itérations avec des exemples structurés, des cas négatifs explicites et une liste de contrôle d’auto-vérification. Le traiter comme un texte jetable au lieu d’un composant soigneusement versionné est la façon dont vous vous retrouvez avec des sorties imprévisibles.
Mesurez ce qui compte pour la partie prenante. Les ingénieurs ne se souciaient pas de savoir si le pipeline utilisait PyMuPDF, GPT-4 ou des pigeons voyageurs. Ils souhaitaient que 4 700 dessins soient traités en 45 minutes au lieu de quatre semaines, pour un coût de 50 à 70 $ en appels API au lieu de plus de 8 000 £ en temps d’ingénierie, et que les résultats soient suffisamment précis pour pouvoir procéder en toute confiance.
Le pipeline complet comprend environ 600 lignes de Python. Il a permis d’économiser quatre semaines de temps d’ingénierie, a coûté moins qu’un déjeuner d’équipe en frais d’API et a depuis été déployé comme outil de production sur plusieurs sites. Nous avons testé les derniers modèles. Ils n’étaient pas meilleurs pour ce travail. Parfois, le travail d’IA ayant le plus grand impact ne consiste pas à utiliser le modèle le plus puissant disponible. Il s’agit de savoir où se situe un modèle dans le système et de l’y conserver.
Obinna est un ingénieur senior en IA/données basé à Leeds, au Royaume-Uni, spécialisé dans les systèmes d’intelligence documentaire et d’IA de production. Il crée du contenu autour de l’ingénierie pratique de l’IA chez @DataSenseiObi sur X et Wisabi Analytics sur YouTube.
You may also like


