
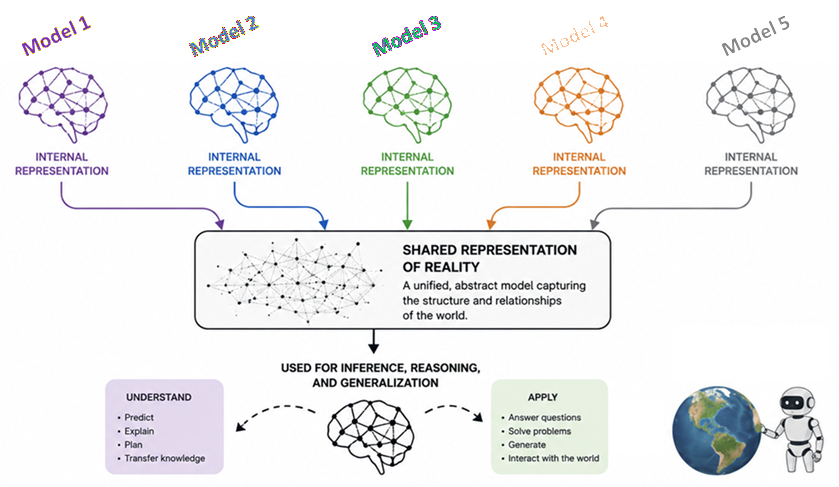
Comment les principaux modèles de raisonnement convergent vers le même « cerveau » à mesure qu’ils modélisent de mieux en mieux la réalité
Je suis l’une des découvertes (et des sujets) les plus intéressants en matière d’intelligence artificielle, laissant de côté le débat sur la question de savoir s’il s’agit ou non d’intelligence.
Nous (du moins moi !) supposons que si vous entraîniez un modèle d’IA uniquement sur, disons, des images et un autre uniquement sur du texte, ils développeraient des façons de « penser » complètement différentes – sans entrer dans la discussion sur ce que cela signifie exactement. Notre idée serait qu’ils utilisent des architectures complètement différentes et traitent des données complètement différentes, ils devraient donc, selon toute logique, avoir des « cerveaux » complètement différents, même s’ils sont tous deux bons dans leurs tâches avec les images et le texte.
Mais selon des recherches passionnantes menées par divers groupes, ce n’est pas du tout le cas !
Déjà en 2024, Le MIT a présenté des preuves solides que tous les principaux modèles d’IA convergent secrètement vers le même « noyau de réflexion » (ou cerveau, ou peu importe comment vous voulez l’appeler). À mesure que ces modèles deviennent plus grands et plus puissants, ils arrivent tous exactement à la même conclusion sur la façon dont le monde est structuré. Peut-être que ce n’était pas évident avec les premiers modèles, parce qu’ils étaient mauvais en raisonnement ; mais cela devient de plus en plus évident à mesure qu’ils s’améliorent. Et je dirais que la raison en est que s’ils sont tous corrects, ils DOIVENT créer une représentation très similaire de la réalité.
L’allégorie de la grotte (IA)
Pour comprendre pourquoi cela se produit, certains chercheurs se sont penchés sur « l’allégorie de la grotte » de Platon il y a 2 400 ans, ce qui a donné lieu à des prépublications intéressantes contenant des idées telles que « l’hypothèse de la représentation platonicienne ». Essentiellement, Platon croyait que nous, les humains, sommes comme des prisonniers dans une grotte, regardant les ombres vaciller sur un mur. Nous pensons que les ombres (nos perceptions) sont la « réalité », mais elles ne sont en réalité que des projections d’une réalité plus profonde, cachée et plus complexe existant à l’extérieur de la grotte.
L’un des nombreux articles que j’ai lus pour préparer ceci (liens à la fin) soutient que les modèles d’IA font exactement la même chose et que, ce faisant, ils convergent vers le même modèle de fonctionnement du monde afin de comprendre les ombres d’entrée.
Les milliards de lignes de texte, les milliards de pixels dans les images, les fichiers audio sans fin utilisés pour l’entraînement de nos modèles d’IA modernes ne sont que leur perception (« ombres ») de notre monde. Ces modèles puissants examinent ces différentes ombres de données humaines et, de manière totalement indépendante, découvrir exactement la même structure sous-jacente de l’univers pour lui donner un sens.
Des yeux différents, une même vision
Voici la partie époustouflante, du moins pour moi : Un modèle qui « voit » uniquement des images et un modèle qui « lit » uniquement du texte mesurent la distance entre les concepts exactement de la même manière. (s’ils sont tous les deux assez bons).
Si vous demandez à un modèle de vision de cartographier la « distance » entre une image d’un « chien » et d’un « loup », puis demandez à un modèle de langage de cartographier la distance entre le mot « chien » et le mot « loup », les structures mathématiques qu’ils construisent deviennent de plus en plus similaires à mesure qu’ils peuvent mieux distinguer les deux animaux.
En d’autres termes, il semble qu’à mesure que ces modèles évoluent et s’améliorent, ils cessent d’être un fouillis de connexions aléatoires. Les recherches montrent qu’ils ont tendance à s’aligner, et en particulier qu’à mesure que les modèles de vision et les modèles de langage s’élargissent, la manière dont ils représentent les données se ressemble de plus en plus. Tellement incroyable, vous ne trouvez pas !
Pourquoi l’échelle change tout
Selon les recherches disponibles, tout cela semble être assez universel et se produire avec des modèles modernes de toutes les entreprises et formés auprès de différentes sources, à condition que le modèle lui-même soit suffisamment performant. En fait, à mesure qu’un modèle s’agrandit, quel qu’il soit, il subit un « changement de phase » dans sa pensée interne. Les recherches semblent indiquer que ces modèles cessent de simplement mémoriser leurs tâches spécifiques et commencent plutôt à construire un modèle statistique de la réalité elle-même.
Et apparemment, cela se produit à cause d’une certaine « pression sélective » agissant sur les modèles :
- Généralité de la tâche : Si vous voulez qu’une IA soit bonne dans tout, il n’y a qu’une seule « meilleure » façon de représenter le monde de telle sorte qu’il ne puisse pas encore être prédit. Puisqu’il n’y a qu’UNE seule meilleure solution, ils doivent tous s’y mettre !
- Capacité: Les grands modèles ont la « marge » pour trouver la solution la plus élégante et la plus simple. Mais disposer d’une grande marge de manœuvre en termes d’architecture du nombre de paramètres doit être équilibré en évitant le surajustement.
- Biais de simplicité : Les réseaux profonds préfèrent en fait les solutions simples aux solutions complexes, encore une fois surtout si le surajustement est évité.
Une chose importante est que les différents modèles d’IA pourraient s’adapter à ces éléments de pression sélective à différentes vitesses (ou avec différents niveaux d’efficacité) ; mais ils se dirigent certainement tous vers le même état final de compréhension maximale atteint grâce à la même représentation interne du fonctionnement du monde.
Les recherches les plus modernes sur les « mécanismes de la connaissance »
Si j’avais 25 ans de moins et que je devais choisir une carrière maintenant, je choisirais probablement quelque chose comme l’informatique mélangée à la psychologie. Parce que pour moi, c’est là que se trouve la partie la plus excitante du monde de l’IA. Lisez pourquoi !
Une enquête récente sur les « mécanismes de connaissance » dans les LLM ajoute une autre couche à tout cela décrit ci-dessus. Cela suggère que les connaissances contenues dans ces modèles ne sont pas seulement dispersées au hasard ; il évolue plutôt d’une simple mémorisation à une « compréhension et application » complexe. Il y aurait alors une sorte d’« intelligence dynamique » en jeu. La tendance selon laquelle les connaissances et les capacités ont tendance à converger vers les mêmes espaces de représentation semble se produire dans l’ensemble du groupe de modèles neuronaux artificiels, quels que soient les données, les modalités ou les objectifs. Même les connaissances que nous, les humains, n’avons pas encore tout à fait saisies (ou que seuls les experts dans un domaine spécifique comprennent, par exemple, comment créer de la musique pour un compositeur ou pourquoi et comment les photons peuvent s’emmêler pour un physicien) sont cartographiées par ces modèles à mesure qu’ils trouvent des modèles (en suivant l’exemple, par exemple en musique ou en physique quantique) que notre cerveau biologique ne peut pas traiter aussi rapidement.
Pourquoi c’est si cool et une analogie avec la façon dont nous, les humains, apprenons
C’est l’un de ces rares moments où les mathématiques, l’informatique et la philosophie se heurtent. Il me semble que les modèles construisent un perception unifiée de la réalité de la seule manière dont ils peuvent l’ingérer : sous forme de mots, d’images et de sons. Pas vraiment différent de la façon dont les bébés apprennent, peut-être bien que dans un ordre différent et en ajoutant plus d’intrants, notamment physiques (dur, bosses, etc.), et bien sûr couplés à des extrants physiques (pleurs, rires, mouvements des membres, marche, …)
Après tout, dans notre cerveau, la multimodalité est également intégrée et fonctionne selon la même compréhension globale (qui, oui, peut être trompée par des illusions, mais ce sera pour un autre jour !). En d’autres termes, notre cerveau mappe également tout sur une seule réalité, qui est notre interprétation personnelle du fonctionnement du monde.. Si je prends une photo d’une pomme, si j’écris le mot « pomme », si j’enregistre le son de quelqu’un qui mord une pomme, ce sont trois « ombres » différentes mais elles sont toutes projetées à partir de la même réalité physique réelle de la pomme. Même si la pomme est d’une couleur différente, même peinte artificiellement, ou si j’écris le mot dans d’autres langues, « manzana » ou « pomme », si je parle respectivement espagnol et français, refléteront un peu la même ombre.
Représentation globale de la réalité + entrées physiques + sorties physiques –> robots
Tout ce qui précède, y compris l’analogie avec les bébés et les humains, peut alors être de plus en plus extrapolé. Ou du moins, j’aime penser cela.
Ajoutez des capacités d’entrées et de sorties physiques à un modèle de réalité d’IA global et fonctionnel, et nous obtenons un robot capable d’apprendre à interpréter et à interagir avec le monde. Insérez-y un « instinct » de survie, et bien… qui sait où cela peut mener. Mais nous ne sommes pas très différents de cette construction, n’est-ce pas ?
Je vais laisser cela ici, pour ne pas entrer dans ce débat, mais s’il vous plaît, échangez avec moi à ce sujet !
Laissons tomber ici avec la preuve claire et basée sur la recherche que nous ne construisons plus seulement des outils pour nous aider à rédiger des e-mails, à résumer quelque chose, à écrire du code ou à éditer ou générer des photos. Nous construisons des miroirs numériques de l’univers. Et nous observons, en temps réel, le silicium et le code découvrir indépendamment le fonctionnement interne du monde dans lequel nous vivons.
Références
Pour rédiger cet article, j’ai parcouru en détail ces deux ouvrages super intéressants : une étude présentée en prépublication en 2024, et une revue plus récente sur les mécanismes de connaissance dans les LLM :
L’hypothèse de la représentation platonicienne : https://arxiv.org/html/2405.07987v5
Mécanismes de connaissances dans les grands modèles de langage : une enquête et une perspective : https://aclanthology.org/2024.findings-emnlp.416/
You may also like


