
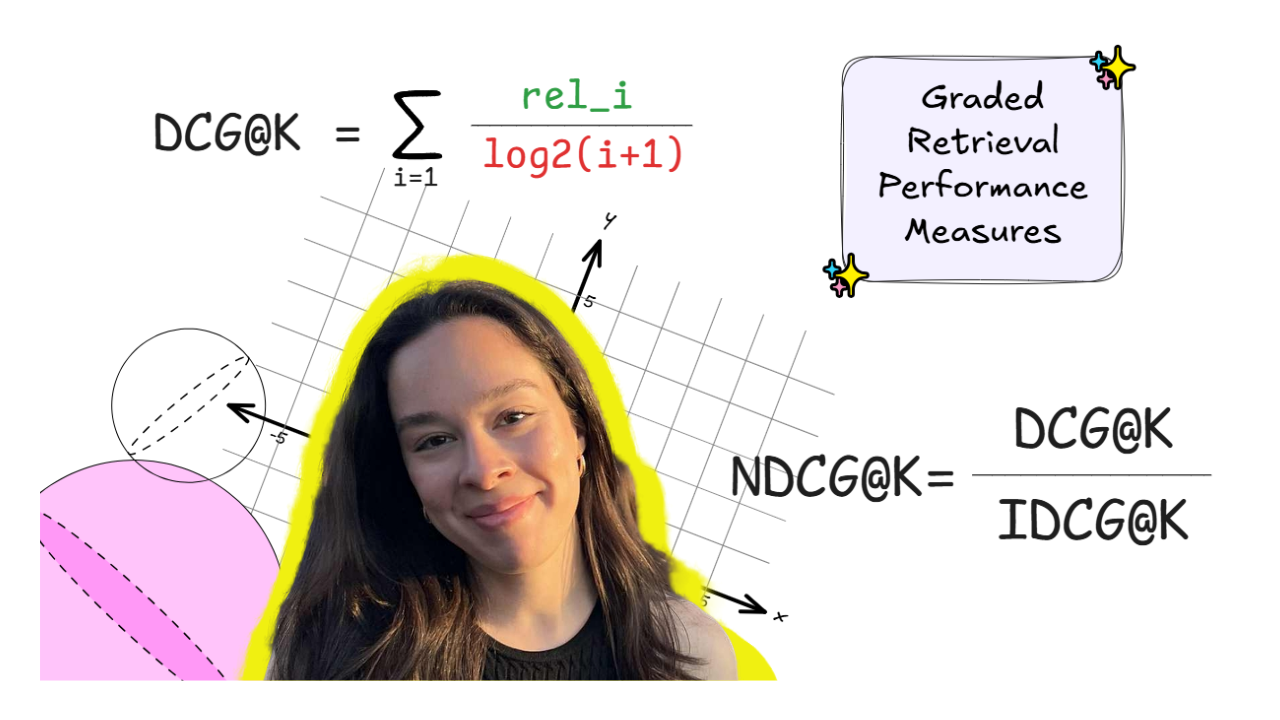
Comment évaluer la qualité de la récupération dans les pipelines RAG (partie 3) : DCG@k et NDCG@k
Assurez-vous également de consulter les parties précédentes:
👉Partie 1 : Precision@k, Recall@k et F1@k
👉Partie 2 : Rang réciproque moyen (MRR) et précision moyenne (AP)
Dans ma série d’articles sur les mesures d’évaluation de récupération pour les pipelines RAG, nous avons examiné en détail les métriques d’évaluation de récupération binaire. Plus précisément, dans la première partie, nous avons passé en revue les métriques d’évaluation de récupération binaires, ignorant les commandes, telles que HitRate@K, Recall@K, Precision@K et F1@K. Les métriques d’évaluation de récupération binaires, ignorant les ordres, sont essentiellement le type de mesures le plus élémentaire que nous pouvons utiliser pour évaluer les performances de notre mécanisme de récupération ; ils classent simplement un résultat comme pertinent ou non, et évaluent si les résultats pertinents parviennent à l’ensemble récupéré.
Ensuite, dans la deuxième partie, nous avons examiné des mesures d’évaluation binaires tenant compte des ordres, telles que le rang réciproque moyen (MRR) et la précision moyenne (AP). Les mesures binaires sensibles à l’ordre classent les résultats comme pertinents ou non et vérifient s’ils apparaissent dans l’ensemble de récupération, mais en plus de cela, elles quantifient également dans quelle mesure les résultats sont classés. En d’autres termes, ils prennent également en compte le classement avec lequel chaque résultat est récupéré, indépendamment du fait qu’il soit récupéré ou non en premier lieu.
Dans cette dernière partie de la série d’articles sur les métriques d’évaluation de récupération, je vais approfondir davantage l’autre grande catégorie de métriques, au-delà des métriques binaires. C’est, mesures notées. Contrairement aux métriques binaires, où les résultats sont pertinents ou non, pour les métriques notées, la pertinence est plutôt un spectre. De cette façon, le morceau récupéré peut être plus ou moins pertinent à la requête de l’utilisateur.
Deux mesures de pertinence graduées couramment utilisées que nous allons examiner dans l’article d’aujourd’hui sont le gain cumulatif actualisé (DCG@K) et le gain cumulatif actualisé normalisé (NDCG@k).
J’écris 🍨Crème de donnéesoù j’apprends et expérimente l’IA et les données. Abonnez-vous ici pour apprendre et explorer avec moi.
Quelques mesures graduées
Pour les mesures de récupération graduées, il est tout d’abord important de comprendre le concept de pertinence graduée. Autrement dit, pour les mesures graduées, un élément récupéré peut être plus ou moins pertinent, tel que quantifié par rel_i.

🎯 Gain cumulatif réduit (DCG@k)
Le gain cumulatif actualisé (DCG@k) est une métrique d’évaluation de récupération graduelle et sensible à l’ordre, nous permettant de quantifier l’utilité d’un résultat récupéré, en tenant compte du rang avec lequel il est récupéré. Nous pouvons le calculer comme suit :

Ici, le numérateur rel_i est la pertinence graduée du résultat récupéré i, essentiellement, est une quantification de la pertinence du morceau de texte récupéré. De plus, le dénominateur de cette formule est le log du classement du résultat i. Essentiellement, cela nous permet de pénaliser les éléments qui apparaissent dans l’ensemble récupéré avec des rangs inférieurs, en soulignant l’idée que les résultats apparaissant en haut sont plus importants. Ainsi, plus un résultat est pertinent, plus le score est élevé, mais plus le classement auquel il apparaît est bas, plus le score est bas.
Explorons cela plus en détail avec un exemple simple :

Quoi qu’il en soit, l’un des problèmes majeurs de DCG@k est que, comme vous pouvez le constater, il s’agit essentiellement d’une fonction somme de tous les éléments pertinents. Ainsi, un ensemble récupéré avec plus d’éléments (un k plus grand) et/ou des éléments plus pertinents entraînera inévitablement un DCG@k plus grand. Par exemple, si par exemple, considérons simplement k = 4, nous nous retrouverions avec un DCG@4 = 28,19. De même, DCG@6 serait plus élevé et ainsi de suite. À mesure que k augmente, DCG@k augmente généralement, puisque nous incluons plus de résultats, à moins que des éléments supplémentaires n’aient aucune pertinence. Néanmoins, cela ne signifie pas nécessairement que ses performances de récupération sont supérieures. Au contraire, cela pose plutôt problème car cela ne nous permet pas de comparer des ensembles récupérés avec différentes valeurs k basées sur DCG@k.
Ce problème est efficacement résolu par la prochaine mesure graduée dont nous discuterons plus tard dans la journée – NDCG@k. Mais avant cela, nous devons introduire IDCG@K, nécessaire au calcul de NDCG@K.
🎯 Gain cumulatif actualisé idéal (IDCG@k)
Le gain cumulatif actualisé idéal (IDCG@k), comme son nom l’indique, est le DCG que nous obtiendrions dans la situation idéale où notre ensemble récupéré est parfaitement classé en fonction de la pertinence des résultats récupérés. Voyons quel serait l’IDCG pour notre exemple :

Apparemment, pour un k fixe, IDCG@k sera toujours égal ou supérieur à n’importe quel DCG@k, puisqu’il représente le score pour une récupération et un classement parfaits des résultats pour un certain k.
Enfin, nous pouvons désormais calculer le gain cumulatif actualisé normalisé (NDCG@k), en utilisant DCG@k et IDCG@k.
🎯 Gain cumulatif actualisé normalisé (NDCG@k)
Le gain cumulatif actualisé normalisé (NDCG@k) est essentiellement une expression normalisée de DCG@k, résolvant notre problème initial et le rendant comparable pour différentes tailles d’ensemble récupérées k. Nous pouvons calculer NDCG@k avec cette formule simple :

Fondamentalement, NDCG@k nous permet de quantifier à quel point notre récupération et notre classement actuels sont proches de l’idéal, pour un k donné. Cela nous fournit commodément un numéro qui est comparable pour différentes valeurs de k. Dans notre exemple, NDCG@k=5 serait :

En général, NDCG@k peut aller de 0 à 1, 1 représentant une récupération et un classement parfaits du résultat, et 0 indiquant un désordre complet.
Alors, comment calculons-nous réellement DCG et NDCG en Python ?
Si vous avez lu mes autres tutoriels RAG, vous savez que c’est ici que se trouve le Guerre et Paix Un exemple entrerait généralement. Néanmoins, cet exemple de code devient trop volumineux pour être inclus dans chaque article, donc je vais plutôt vous montrer comment calculer DCG et NDCG en Python, en faisant de mon mieux pour garder cet article à une longueur raisonnable.
Pour calculer ces métriques de récupération, nous devons d’abord définir un ensemble de vérités terrain, exactement comme nous l’avons fait dans la partie 1 lors du calcul de Precision@K et Recall@K. La différence ici est qu’au lieu de caractériser chaque morceau récupéré comme pertinent ou non, en utilisant des pertinences binaires (0 ou 1), nous lui attribuons désormais un score de pertinence gradué ; par exemple, de complètement hors de propos (0) à super pertinent (5). Ainsi, notre ensemble de vérités terrain inclurait les morceaux de texte qui ont les scores de pertinence les plus élevés pour chaque requête.
Par exemple, pour une requête comme « Qui est Anna Pavlovna ?un morceau récupéré qui correspond parfaitement à la réponse pourrait recevoir un score de 3, celui qui mentionne partiellement les informations nécessaires pourrait obtenir un 2, et un morceau totalement sans rapport obtiendrait un score de pertinence égal à 0.
En utilisant ces listes de pertinence graduées pour un ensemble de résultats récupérés, nous pouvons ensuite calculer DCG@k, IDCG@k et NDCG@k. Nous utiliserons Python math bibliothèque pour gérer les termes logarithmiques :
import mathTout d’abord, nous pouvons définir une fonction pour calculer DCG@k comme suit:
# DCG@k
def dcg_at_k(relevance, k):
k = min(k, len(relevance))
return sum(rel / math.log2(i + 1) for i, rel in enumerate(relevance[:k], start=1))On peut aussi calculer IDCG@k appliquer une logique similaire. Essentiellement, IDCG@k est DCG@k pour une récupération et un classement parfaits ; ainsi, nous pouvons facilement le calculer en calculant DCG@k après avoir trié les résultats par pertinence décroissante.
# IDCG@k
def idcg_at_k(relevance, k):
ideal_relevance = sorted(relevance, reverse=True)
return dcg_at_k(ideal_relevance, k)
Enfin, après avoir calculé DCG@k et IDCG@kon peut aussi facilement calculer NDCG@k comme leur fonction. Plus précisément :
# NDCG@k
def ndcg_at_k(relevance, k):
dcg = dcg_at_k(relevance, k)
idcg = idcg_at_k(relevance, k)
return dcg / idcg if idcg > 0 else 0.0Comme expliqué, chacune de ces fonctions prend en entrée une liste de scores de pertinence classés pour les morceaux récupérés. Par exemple, supposons que pour une requête spécifique, un ensemble de vérités terrain et un test de résultats récupérés, nous obtenions la liste suivante :
relevance = [3, 2, 3, 0, 1]Ensuite, nous pouvons calculer les métriques de récupération graduées à l’aide de nos fonctions :
print(f"DCG@5: {dcg_at_k(relevance, 5):.4f}")
print(f"IDCG@5: {idcg_at_k(relevance, 5):.4f}")
print(f"NDCG@5: {ndcg_at_k(relevance, 5):.4f}")Et c’était tout ! C’est ainsi que nous obtenons nos mesures de performances de récupération graduées pour notre pipeline RAG en Python.
Enfin, comme pour toutes les autres mesures de performances de récupération, nous pouvons également faire la moyenne des scores d’une mesure sur différentes requêtes pour obtenir un score global plus représentatif.
Dans mon esprit
L’article d’aujourd’hui sur les mesures de pertinence graduées conclut ma série d’articles sur les métriques les plus couramment utilisées pour évaluer les performances de récupération des pipelines RAG. En particulier, tout au long de cette série d’articles, nous avons exploré les mesures binaires, ignorant l’ordre et conscientes de l’ordre, ainsi que les mesures graduées, obtenant ainsi une vision holistique de la façon dont nous abordons cela. Apparemment, il y a beaucoup d’autres choses que nous pouvons examiner afin d’évaluer un mécanisme de récupération d’un pipeline RAG, comme par exemple la latence par requête ou les jetons de contexte envoyés. Néanmoins, les mesures que j’ai abordées dans ces articles couvrent les principes fondamentaux de l’évaluation des performances de récupération.
Cela nous permet de quantifier, d’évaluer et, à terme, d’améliorer les performances du mécanisme de récupération, ouvrant ainsi la voie à la création d’un pipeline RAG efficace qui produit des réponses significatives, fondées sur les documents de notre choix.
Vous avez adoré cet article ? Soyons amis ! Rejoignez-moi sur :
📰Sous-pile 💌 Moyen 💼LinkedIn ☕Achetez-moi un café!
Qu’en est-il des pialgorithmes ?
Vous cherchez à apporter la puissance de RAG dans votre organisation ?
pialgorithmes je peux le faire pour toi 👉 réserver une démo aujourd’hui
You may also like


