
Un outil flexible bat cent outils dédiés
Quand vous vouliez qu’un agent LLM communique avec un système début 2026, il fallait lui installer un serveur MCP.
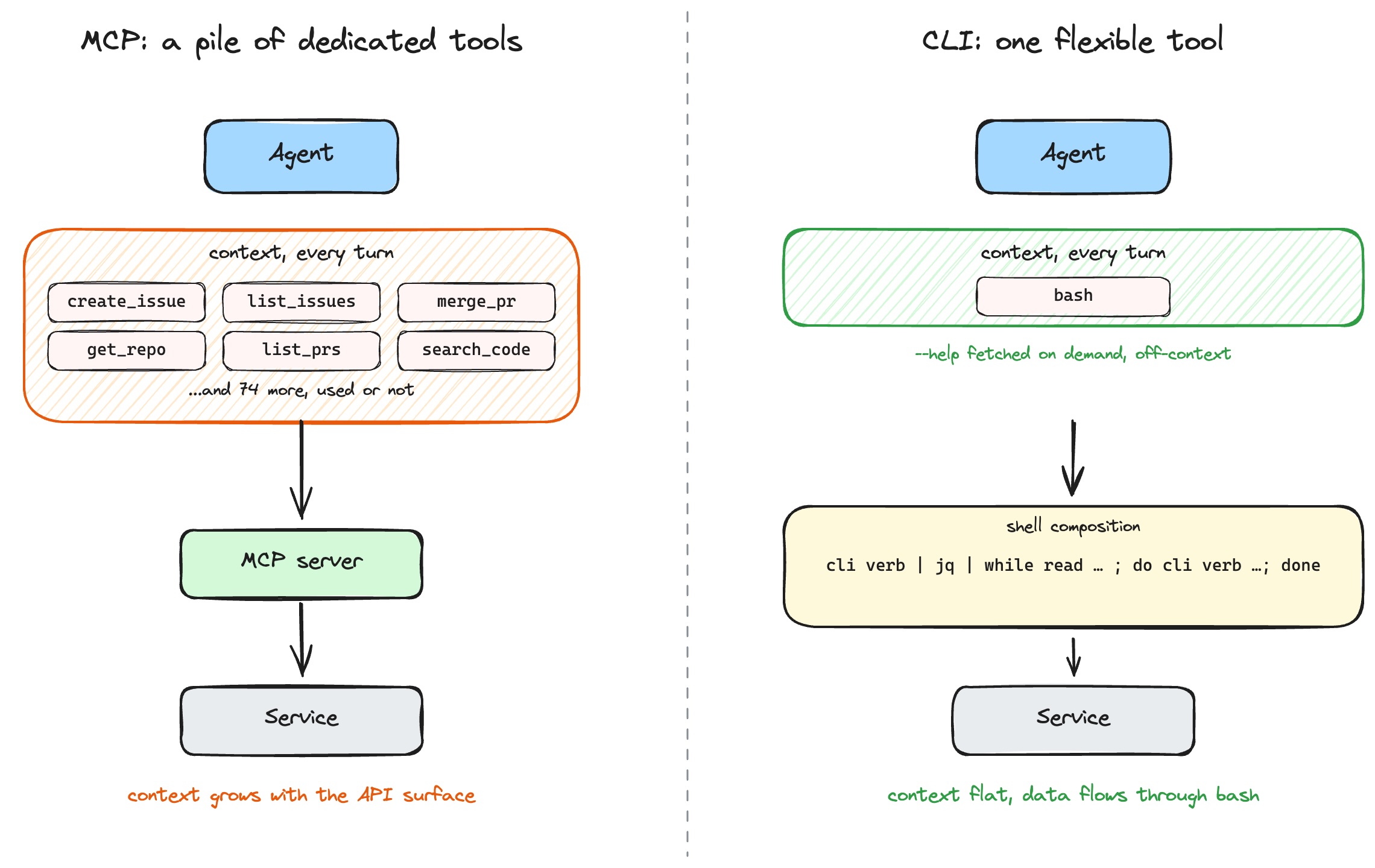
GitHub. Jira. Mou. Linéaire. Postgres. Néo4j. Chacun est livré avec un serveur qui expose un menu bien rangé d’outils, create_issue, list_pull_requests, merge_pull_request, get_repository, search_codeet ainsi de suite, et vous dirigez votre agent vers cela.
C’est une excellente expérience d’intégration. C’est aussi, pour un nombre surprenant de charges de travail réelles, une forme inappropriée.
La thèse est courte : La conception MCP regroupe généralement chaque service sous la forme d’une pile d’outils dédiés ; une CLI offre à l’agent un outil vraiment flexible. Avec les modèles d’aujourd’hui, l’outil flexible gagne.

Les deux formes demandent au modèle d’effectuer un travail différent. Avec une pile d’outils dédiés, l’agent n’a plus qu’à choisir le bon dans un menu. Avec un outil flexible, il faut comprendre comment assembler les pièces lui-même. Cette deuxième partie était la plus difficile. Les modèles hallucinaient les drapeaux, perdaient le fil sur les longs pipelines, lisaient mal le texte d’aide, donc envelopper chaque opération dans un outil prédéfini était donc une défense judicieuse. Ce n’est tout simplement plus vrai. Les modèles d’aujourd’hui lisent un --help page ou SKILL.md quand ils en ont besoin, connaissez les CLI canoniques grâce à la formation, enchaînez les bash sans supervision et réessayez lorsqu’ils se trompent d’indicateur. La partie difficile est devenue facile, la partie facile a toujours été facile, et tous ces outils soigneusement emballés ne font que gonfler le contexte du modèle pour rien maintenant.
Bien sûr, il n’y a pas que du soleil et des roses. Donner à l’agent un terminal lui confère également un rayon d’explosion beaucoup plus grand. La même flexibilité qui lui permet de composer gh | jq | xargs en quelque chose d’utile permet également à une injection rapide de le transformer en quelque chose de bien pire qu’une requête Cypher hostile. Alors oui, il y a un compromis, et vous devez réellement y penser (bac à sable, liste verte, utilisateur distinct du système d’exploitation, rôle en lecture seule dans la base de données, les éléments habituels).
Mais lorsque vous pouvez donner un terminal à l’agent de manière raisonnablement sûre, le côté flexible reste toujours gagnant.
Là où CLI brille
Le même modèle « envelopper un service sous la forme d’une pile d’outils dédiés » apparaît partout où MCP le fait. MCP Postgres vs. psql. Comparaison entre les MCP Kubernetes et kubectl. MCP du système de fichiers vs. cat, ls, mv, grep collé par des tuyaux. Même instinct à chaque fois, même homologue CLI à chaque fois. Et les trois mêmes modes de défaillance aussi, car ils ne concernent pas vraiment un seul produit.
Rien dans la spécification MCP n’exige réellement cette approche consistant à empiler des outils dédiés. Le protocole demande des outils typés, rien de plus ; cela ne dit rien sur l’étroitesse de chaque outil. Les implémentations gravitent autour de nombreux petits outils restreints pour des raisons historiques. Vous pouvez créer des outils flexibles qui prennent une seule entrée expressive que l’agent façonne comme il le souhaite, et la plupart du temps vous devriez probablement le faire.
Pour que ce soit concret, nous allons regarder un exemple de piquage Serveur Neo4j MCP contre CLI Neo4j.
Avis de non-responsabilité : je travaille chez Neo4j. Le choix n’est qu’une question de commodité, mais les enseignements s’appliquent à la plupart des autres CLI.
Le serveur Neo4j MCP est le serveur officiel qui expose Neo4j aux agents via MCP, en fournissant une poignée d’outils dédiés tels que des requêtes de lecture, des requêtes d’écriture et des schémas d’obtention. neo4j.sh est l’interface de ligne de commande officielle de Neo4j, un binaire unique que vous exécutez dans un terminal avec des profils d’identification pour chaque base de données à laquelle vous parlez. Pour que la comparaison reste honnête, nous examinerons uniquement la paire requête de lecture et schéma du côté MCP par rapport à l’équivalent query invocation dans neo4j.sh. Mêmes opérations, même base de données, même chiffre sur le réseau. La seule chose qui change est de savoir si l’agent les atteint via un schéma d’outil typé ou via une chaîne transmise à un shell.
Interrogation dans plusieurs environnements
Nous avons déjà vu comment une pile d’outils dédiés engloutit la fenêtre contextuelle avec des descriptions, et que certains serveurs fournissent désormais des outils différés pour réduire ce coût jusqu’à ce que l’agent les récupère réellement. Mais il existe un deuxième multiplicateur dont personne ne parle : que se passe-t-il lorsque vous souhaitez communiquer avec plusieurs instances du même service. Avec MCP, le nombre d’outils n’augmente pas seulement avec les fonctionnalités, mais avec les environnements.

L’agent souhaite connaître le nombre de nœuds provenant du développement, de la préparation et de la production. Grâce à MCP, vous défendez neo4j-mcp-server par environnement, chacun transportant ses quatre schémas d’outils dans le contexte de l’agent à chaque tour. Trois bases de données, cela représente douze schémas dans la fenêtre du modèle, les quatre mêmes schémas trois fois, avant que l’agent n’ait fait quoi que ce soit.
Grâce à la CLI, c’est un for boucle:
$ for c in dev staging prod-ro; do
neo4j-cli query -c $c --format toon \
"MATCH (n) RETURN count(n) AS nodes"
doneUn binaire, trois profils d’identification, aucun coût de contexte par tour. Ajouter un quatrième environnement en est un de plus credential dbms addpas un autre processus de serveur MCP. La même forme s’applique à tout flux de travail « atteindre N éléments similaires » que vous pourriez souhaiter : prendre un instantané de la production avant un déploiement risqué, différencier le schéma entre la préparation et la production, exécuter une vérification de l’état de chaque base de données connue de l’agent.
Requêtes de chaînage
Supposons que l’agent enquête sur un compte frauduleux connu : à partir d’une seule graine, trouvez tous les comptes avec lesquels il a effectué des transactions, puis trouvez lequel autre comptes avec lesquels les contreparties effectuent le plus souvent des transactions. Deux requêtes sur la même base de données, où les paramètres de la seconde sont la sortie de la première.

Grâce à MCP, le modèle doit être le tuyau. Il appelle read-cypherle résultat revient sous la forme d’une liste, disons, de 80 identifiants de contrepartie, ces 80 identifiants se trouvent désormais dans le contexte du modèle, le modèle les formate dans le paramètre du second read-cypher appel, et alors seulement peut interroger deux exécutions. La liste intermédiaire reprend la conversation textuellement, et chaque identifiant supplémentaire est une autre ligne de contexte pour laquelle l’agent paie, qu’il la relise ou non.
Grâce à la CLI, le tube est un littéral |:
$ neo4j-cli query -c prod-ro --format json \
--param "seed=acct_19f3" \
"MATCH (:Account {id: \$seed})-[:TRANSACTED]-(c:Account)
WHERE c.id <> \$seed
RETURN collect(DISTINCT c.id) AS counterparties" \
| neo4j-cli query -c prod-ro --params-from-stdin \
"MATCH (a:Account)-[:TRANSACTED]-(b:Account)
WHERE a.id IN \$counterparties
AND NOT b.id IN \$counterparties + ['acct_19f3']
RETURN b.id, count(DISTINCT a) AS edges_into_cluster
ORDER BY edges_into_cluster DESC LIMIT 20"--params-from-stdin lit le résultat JSON de la requête précédente et le lie en tant que paramètre pour la suivante. La liste des contreparties n’entre jamais dans le contexte du modèle, le coût en token de l’agent est le même que le cluster comporte 5 contreparties ou 500.
C’est là que le shell commence à ressembler à une catégorie d’outils complètement différente. L’agent ne choisit plus dans un menu d’opérations, il compose des pipelines et les données intermédiaires n’ont jamais besoin de faire surface. Une requête en deux étapes devient un |. Une diffusion devient un for boucle. Une jointure entre deux bases de données n’en fait plus qu’une query transmis à un autre avec --params-from-stdin. Chacun d’eux représenterait trois ou quatre allers-retours MCP avec chaque résultat intermédiaire défilé dans la fenêtre contextuelle, et à ce stade, l’agent a dépensé plus de jetons à mélanger les lignes qu’à y penser.
Canalisation à travers de nombreuses CLI
Même problème, à plus grande échelle. Supposons que l’agent souhaite matérialiser les problèmes GitHub récents d’un projet dans Neo4j : un :Issue nœud par ticket, un :User nœud par auteur, un :TAGGED relation par étiquette. Les données résident dans une CLI (gh), veut remodeler (jq fait ça) et atterrit dans une autre CLI (neo4j-cli). Trois outils différents sur une seule ligne. Grâce à MCP, vous accédez au serveur MCP de GitHub pour la liste des problèmes, chaque corps de problème atterrit dans le contexte du modèle, le modèle extrait les champs qu’il souhaite et write-cypher se déclenche une fois par numéro. Des centaines d’allers-retours à travers le modèle, chaque sujet étant présent dans la conversation tout au long du chemin.
Via la CLI, trois programmes dans un tube :
$ gh issue list --repo neo4j/neo4j --limit 100 \
--json number,title,author,labels \
| jq -c '.[]' \
| while read issue; do
neo4j-cli query --rw -c prod \
--param "data=$issue" \
"WITH apoc.convert.fromJsonMap(\$data) AS i
MERGE (n:Issue {number: i.number}) SET n.title = i.title
MERGE (u:User {login: i.author.login})
MERGE (u)-[:OPENED]->(n)
FOREACH (label IN i.labels |
MERGE (l:Label {name: label.name})
MERGE (n)-[:TAGGED]->(l))"
donegh tire les problèmes, jq remodèle chacun d’entre eux en une seule ligne JSON, le while la boucle remet chaque ligne à neo4j-cli comme paramètre Cypher. Le modèle écrit ce script une fois, puis s’en va ; les données circulent via bash, pas via l’agent. Cent numéros ou dix mille, le coût symbolique de l’agent est le même.
La forme se généralise bien au-delà de GitHub. Échanger gh pour toute autre CLI émettant du JSON (jira issue list, linear, curl contre un webhook, votre propre interne dump commande), échangez le modèle Cypher pour la base de données que vous créez, et le pipeline le transporte. Deux outils MCP ne peuvent pas communiquer entre eux ; deux CLI le peuvent, tout comme dix.
Le contrôle du terminal est puissant, et c’est le problème
Le terminal n’est pas une surface fixe, c’est l’outil le plus flexible qu’un agent puisse mettre à sa disposition car il compose avec tout le reste de la boîte.
Ce pouvoir est aussi le piège. Un outil flexible mal utilisé provoque des dégâts flexibles. Un bon accès au terminal s’accompagne d’une responsabilité évidente : mettre le shell en sandbox, mettre sur liste verte les verbes que vous souhaitez réellement, exécuter l’agent en tant qu’utilisateur du système d’exploitation distinct, lier les informations d’identification à des rôles qui ne peuvent physiquement pas faire la chose destructrice. Rien de tout cela n’est nouveau, c’est juste une hygiène d’administrateur système appliquée à un LLM qui tape rapidement. Et si vous ne pouvez rien faire de tout cela, un serveur MCP avec une petite surface fixe reste la bonne réponse ; la garantie au niveau du protocole que l’agent ne peut pas cat ~/.ssh/id_rsa est une chose réelle.
Le point plus large est valable même si vous restez entièrement à l’intérieur de MCP. La raison pour laquelle le terminal gagne n’est pas que bash est spécial, c’est que bash est un outil avec une saisie très flexible. Tuyaux, variables, substitution, bouclage. C’est la forme qui mérite d’être copiée. Considérez le terminal comme le cas limite de MCP et concevez-le : moins d’outils, chacun acceptant une entrée expressive, l’agent composant la composition au lieu d’anticiper chaque combinaison à l’avance. La plupart des serveurs MCP constituent une longue liste de points de terminaison étroits, car c’est ainsi que l’API sous-jacente a déjà été conçue, et non parce que l’agent fonctionne mieux de cette façon. Les serveurs qui vieilliront bien seront ceux qui auront volontairement choisi une surface plus petite et plus expressive.
Toutes les images de cet article de blog sont créées par l’auteur.
You may also like


