
Mémoire agent unifiée sur les harnais à l’aide de crochets
que le débat principal ne porte pas sur la date de sortie du prochain meilleur modèle, mais sur qui construira le bon harnais autour de lui. Un harnais est l’échafaudage autour du modèle : la boucle d’agent, les définitions d’outils, la gestion du contexte, la mémoire, les invites et les flux de travail qui transforment un LLM brut en un produit utile. Le modèle est le moteur, le harnais est tout ce qui le fait réellement rouler. Des exemples de harnais sont Cursor, Claude Desktop et autres.
Il y a un lancer un débat dans l’espace des outils de codage de l’IA : s’engager sur un harnais spécifique signifie-t-il un verrouillage du fournisseur ? La mémoire en est l’aspect le plus pointu. Si la mémoire de votre agent réside dans un harnais fermé ou derrière une API propriétaire, vous n’en êtes pas vraiment propriétaire et les coûts de changement s’accumulent rapidement. Mais il n’est pas nécessaire qu’il en soit ainsi.
L’idée de cet article de blog est simple : gardez la couche de mémoire à l’extérieur du harnais et laissez n’importe quel harnais s’y brancher.

Dans cet article, je vais montrer comment vous pouvez créer un couche de mémoire unique et partagée qui fonctionne avec trois agents de codage différents : Claude Code, le Codex d’OpenAI et Cursor – en utilisant crochets comme mécanisme d’intégration et Néo4j comme magasin persistant.
Le code pour l’intégration du hook est disponible sur GitHub.
Les outils MCP ne peuvent vous mener que jusqu’à présent avec de la mémoire
Les serveurs MCP (Model Context Protocol) sont la solution idéale pour permettre aux agents d’accéder aux systèmes externes. Et ils fonctionnent. Vous pouvez exposer une base de données Neo4j en tant qu’outil MCP et laisser l’agent l’interroger lorsqu’il le décide.
Mais les outils MCP sont initié par l’agent. Le modèle doit décider d’appeler l’outil, et il doit savoir quand et pourquoi le faire. Cela signifie :
- L’agent doit « se souvenir de se souvenir », il doit décider de manière proactive de stocker quelque chose qui mérite d’être rappelé plus tard.
- Il n’y a aucune garantie de cohérence, une session peut tout enregistrer, la suivante peut ne rien enregistrer.
- Vous vous fiez au jugement du modèle sur ce qui est important pour la mémoire, en temps réel, pendant qu’il est occupé à faire autre chose.
Ce que tu veux vraiment, c’est journalisation passive et déterministequi capture chaque événement de session, indépendamment de ce que fait le modèle, sans consommer aucun de son contexte ni de son attention.
C’est exactement ce que les crochets vous offrent.

Entrez les crochets
Les hooks sont des commandes shell qui se déclenchent automatiquement lors des événements du cycle de vie : lorsqu’une session démarre, lorsque l’utilisateur soumet une invite, avant et après chaque utilisation d’un outil et à la fin de la session. L’agent ne décide pas de les appeler, ils s’exécutent par programme.
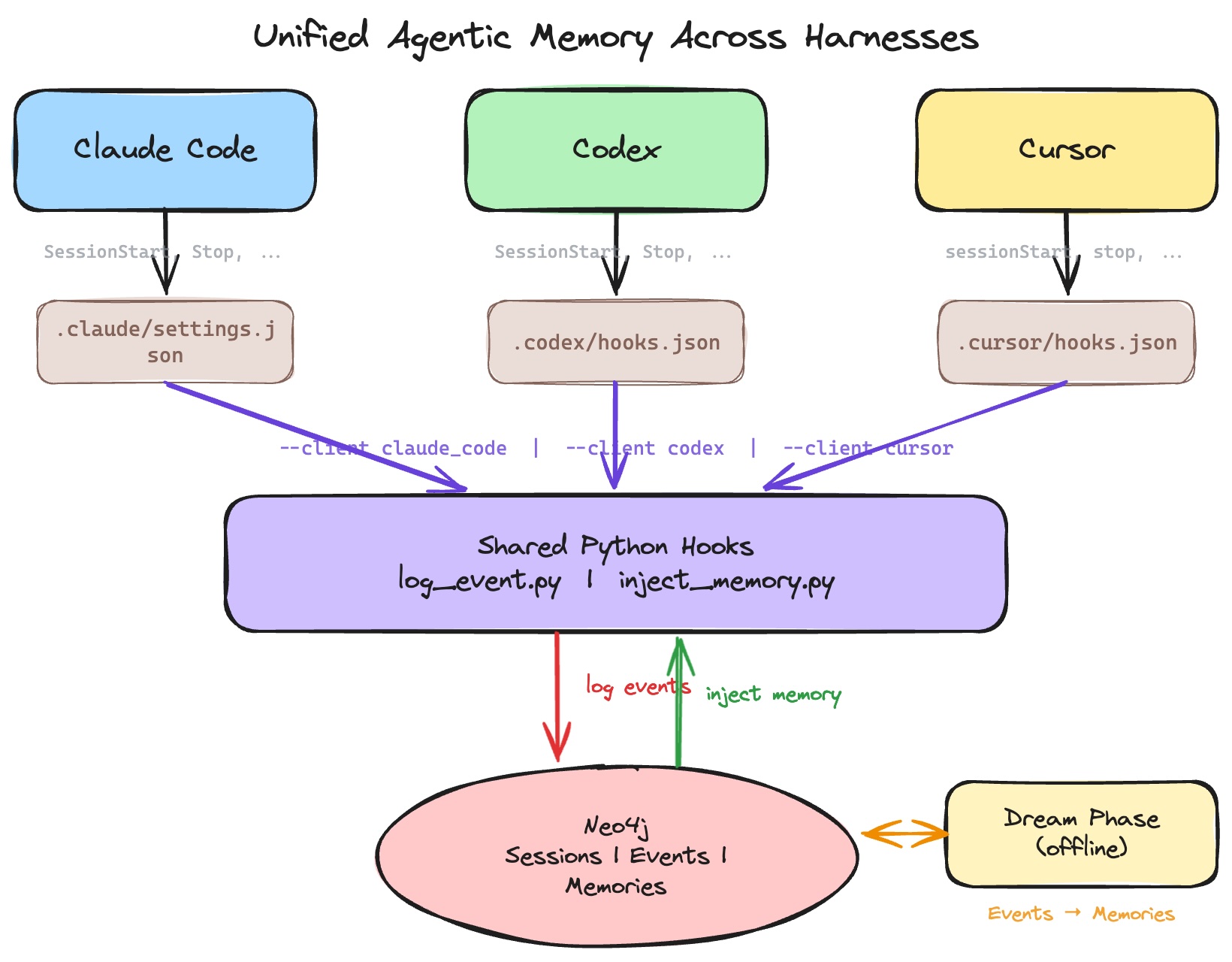
L’idée clé est que les hooks sont remarquablement standardisés entre les fournisseurs. Claude Code, Codex, Cursor et d’autres prennent tous en charge essentiellement les mêmes événements de cycle de vie :
- Début de session pour le début de la session de l’agent
- UserPromptSoumettre (ou
beforeSubmitPromptdans le curseur) lorsque l’utilisateur envoie un message - Utilisation du pré-outil / Utilisation de l’outil de publication pour avant et après chaque appel d’outil
- Arrêt pour la fin de la session
Le hook reçoit une charge utile JSON sur stdin avec l’ID de session, le nom de l’événement, les détails de l’outil et l’invite utilisateur. Et le hook peut émettre du JSON sur la sortie standard pour réinjecter un contexte supplémentaire dans la conversation. Même contrat, trois harnais/clients.
Il existe également d’autres hooks, comme les événements de notification, l’arrêt du sous-agent ou les hooks pré-compacts, mais nous ne les utiliserons pas ici.
Couche de mémoire partagée
Nous avons maintenant besoin d’un endroit où conserver la mémoire. Avertissement rapide : je travaille chez Neo4j, nous l’utiliserons donc dans cet exemple.

Le modèle est simple. Chaque session d’agent est un nœud, connecté à une liste chaînée de nœuds d’événement, un par appel de hook. Les événements sont typés par l’événement de cycle de vie qui les a déclenchés : SessionStart, UserPromptSubmit, PreToolUse, PostToolUse, Stop. Une session se termine par une chronologie ordonnée de tout ce qui s’est passé au cours de cette exécution.
Les cinq types d’événements sont écrits dans le magasin, ce qui vous donne une piste d’audit complète de chaque session sur chaque harnais. Deux d’entre eux sont également des points d’injection. SessionStart se déclenche avant que l’agent ne lise son invite système, donc tout ce que le hook y émet est ajouté au début de l’invite système. C’est ainsi que la mémoire persistante au niveau de l’agent s’intègre dans le contexte. UserPromptSubmit se déclenche juste avant l’envoi du message utilisateur, et tout ce qui y est émis est ajouté à l’invite utilisateur. C’est le crochet pour le contexte au niveau du tour, comme extraire des souvenirs pertinents par rapport à ce que l’utilisateur vient de taper.
Alors, que se passe-t-il si nous commençons une nouvelle session dans l’un de ces harnais avec des crochets actifs, par exemple Cursor ?

Si nous inspectons les résultats dans le navigateur Neo4j.

Une contrainte importante : les crochets passent en dehors de la session modèle du harnais. Vous ne pouvez pas réutiliser le LLM avec lequel l’agent parle. Si vous souhaitez travailler avec LLM dans un hook, vous devez effectuer votre propre appel de modèle, ce qui ajoute de la latence à chaque événement déclenché par l’agent. C’est pourquoi les hooks ici ne font que deux choses : enregistrer les événements et injecter des mémoires pré-calculées. Ils restent rapides et déterministes.
Phase de rêve
Le travail de mémoire proprement dit se déroule dans une phase de rêve distincte : extraire des faits des séances, résumer ce qui s’est passé, mettre à jour le graphique. Il s’agit simplement d’un travail par lots qui s’exécute toutes les quelques heures, lit les événements accumulés depuis la dernière exécution et les réécrit dans la mémoire. Vous pouvez en principe lancer une mise à jour de la mémoire de manière asynchrone à chaque fois qu’une session s’arrête, mais cela semble un peu trop ; un lot périodique est plus simple et fonctionne bien pour cette démonstration.
Le travail de rêve extrait tous les événements depuis le dernier filigrane de la session, les remet à Claude avec la mémoire actuelle et lui demande de réécrire un petit ensemble de notes durables. Les notes elles-mêmes imitent un wiki markdown, la même forme vers laquelle Karpathy et d’autres se sont tournés pour leur mémoire personnelle LLM et la même forme que les compétences d’Anthropic utilisent déjà : chaque mémoire est un fichier sur un chemin sémantique comme profile/role.md, tools/bash/common-flags.mdou project/neo4j-skills.mdavec la couverture YAML en haut et la prose en dessous. On dit à Claude de fusionner plutôt que d’ajouter, donc un chemin est un document évolutif, pas un journal ; si de nouveaux événements contredisent une ancienne note, l’ancienne note est réécrite. Le résultat est un arbre de petits fichiers de démarques autonomes qu’une future session peut lire à froid, dont la forme ne se distingue pas d’une compétence, simplement créés par la phase de rêve plutôt qu’à la main.
Si nous l’exécutons sur notre exemple, nous obtenons les mémoires suivantes créées.

Et maintenant, si j’ouvrais un harnais différent, cette fois Claude Code Desktop avec des hooks activés, j’obtiendrais la réponse suivante.

Accéder à la mémoire
La dernière pièce du puzzle permet à l’agent d’accéder à la couche mémoire. Comme mentionné, il existe deux manières d’injecter des informations dans l’agent : les hooks et les outils MCP.

Les hooks sont déterministes et exécutés au début de chaque session pour remplir l’invite système. C’est ici que doivent se trouver les informations de profil et les instructions sur la façon d’utiliser efficacement la mémoire. Vous pouvez également ajouter un contexte supplémentaire lorsqu’un événement de soumission d’invite utilisateur se déclenche, mais il s’agit uniquement d’un ajout ; vous ne pouvez pas manipuler d’autres parties de l’invite.
Les outils MCP, quant à eux, donnent au LLM un accès direct à la couche mémoire à la demande. Au lieu de recevoir passivement du contexte au démarrage, l’agent peut rechercher des mémoires pertinentes, stocker de nouvelles informations et mettre à jour ou supprimer des entrées existantes. Essentiellement, il s’agit d’un CRUD de base sur les fichiers de démarques abstraits stockés dans Neo4j.
En fin de compte, je pense que vous aurez presque toujours besoin des deux. Dans ce projet, nous n’avons que des hooks, pas d’outils MCP, mais vous pouvez toujours simplement brancher le MCP officiel Neo4j pour permettre à l’agent d’explorer le graphique.
Le faire fonctionner
Assez intéressant, la façon dont j’ai configuré les crochets consistait à pointer l’agent dans l’un des harnais et à lui demander d’installer des crochets, mais je suis sûr qu’il existe également de meilleures approches.

Résumé
Si vous ne possédez pas votre mémoire, vous ne possédez pas votre agent. Aujourd’hui, chaque harnais construit son propre jardin clos de contexte, de préférences et d’historique de session. Changez-les et vous repartez de zéro. Cela ne doit pas nécessairement être le cas.
Les crochets brisent ce modèle. Ils vous permettent d’écrire des intégrations qui se connectent à n’importe quel harnais de l’extérieur et l’interface est remarquablement cohérente. Claude Code, Codex et Cursor déclenchent tous les mêmes événements de cycle de vie : démarrage de session, soumission rapide, utilisation de l’outil, fin de session. Le hook reçoit JSON sur stdin, émet éventuellement JSON sur stdout pour injecter du contexte, et c’est l’intégralité du contrat. Étant donné que les hooks s’exécutent de manière déterministe sur chaque événement, ils ne consomment pas l’attention du modèle et ne comptent pas sur l’agent pour décider de ce qui mérite d’être sauvegardé. Les deux mêmes scripts Python gèrent les trois clients ; enveloppes à coque mince qui passent un --client Le drapeau est la seule colle par harnais.
L’architecture comporte trois couches :
- Crochets (en ligne) — enregistrez passivement chaque événement dans Neo4j sous forme de liste chaînée par session. Aucun appel de modèle, aucun coût de latence, il suffit d’ajouter.
- Phase de rêve (hors ligne) — un travail par lots lit les événements accumulés, demande à Claude de les distiller dans des mémoires de démarques durables et les réécrit. Les souvenirs sont organisés par sujet et fusionnés plutôt qu’ajoutés, de sorte qu’ils restent à jour au lieu de croître éternellement.
- Injection (en ligne) — à la prochaine session commençant dans n’importe lequel harnais, les mémoires de profil sont chargées dans leur contexte. À chaque invite de l’utilisateur, les mémoires pertinentes sont recherchées et ajoutées automatiquement.
Le résultat est une couche de mémoire située sous les trois harnais, qui fonctionne sans qu’aucun d’eux ne connaisse les autres et qui vous appartient entièrement. Vous pouvez passer du curseur au code Claude au codex en cours de projet et reprendre exactement là où vous vous êtes arrêté. La compréhension qu’a votre agent de qui vous êtes, de ce sur quoi vous travaillez et de la manière dont vous préférez travailler vous suit, pas l’outil.
Le code est disponible ici.
Ps : Toutes les images sont créées par l’auteur.
You may also like


