
Le problème de la boîte noire : pourquoi le code généré par l’IA cesse d’être maintenable
Un modèle dans les équipes
se formant au sein des équipes d’ingénierie qui ont adopté les outils de codage d’IA au cours de la dernière année. Le d’abord le mois est euphorique. La vitesse double, les fonctionnalités sont expédiées plus rapidement, les parties prenantes sont ravies. Au troisième moisune autre mesure commence à grimper : le temps qu’il faut pour changer en toute sécurité tout ce qui a été généré.
Le code lui-même ne cesse de s’améliorer. Modèles améliorés, plus corrects, plus complets, contexte plus large. Et pourtant, les équipes générant le plus de code sont de plus en plus celles qui demandent le plus de réécritures.
Cela n’a plus de sens tant que vous n’examinez pas la structure.
Un développeur ouvre un module généré au cours d’une seule session d’IA. Cela peut faire 200 lignes, peut-être 600, la longueur n’a pas d’importance. Ils se rendent compte que la seule chose qui comprenait les relations dans ce code était la fenêtre contextuelle qui l’a produit. Les signatures de fonctions ne documentent pas leurs hypothèses. Trois services s’appellent dans un ordre spécifique, mais la raison de cet ordre n’existe nulle part dans la base de code. Chaque changement nécessite une compréhension complète et un examen approfondi. C’est le problème de la boîte noire.
Qu’est-ce qui fait du code généré par l’IA une boîte noire
Le code généré par l’IA n’est pas un mauvais code. Mais il a des tendances qui deviennent rapidement des problèmes :
- Tout en un seul endroit. L’IA a un fort penchant pour les monolithes et le choix de la voie rapide. Demandez « une page de paiement » et vous obtiendrez le rendu du panier, le traitement des paiements, la validation du formulaire et les appels API dans un seul fichier. Cela fonctionne, mais c’est une unité. Vous ne pouvez pas réviser, tester ou modifier une partie sans la gérer dans son intégralité.
- Dépendances circulaires et implicites. L’IA connecte les éléments en fonction de ce qu’elle a vu dans la fenêtre contextuelle. Le service A appelle le service B car ils étaient dans la même session. Ce couplage n’est déclaré nulle part. Pire encore, l’IA crée souvent des dépendances circulaires, A dépend de B dépend de A, car elle ne suit pas le graphique des dépendances entre les fichiers. Quelques semaines plus tard, la suppression de B brise A, et personne ne sait pourquoi.
- Aucun contrat. Les systèmes bien conçus ont des interfaces typées, des schémas API et des limites explicites. L’IA ignore cela. Le « contrat » correspond à ce que fait la mise en œuvre actuelle. Tout fonctionne jusqu’à ce qu’il faille changer une pièce.
- Documentation qui explique la mise en œuvre, pas l’utilisation. L’IA génère des descriptions détaillées de ce que fait le code en interne. Ce qui manque, c’est l’autre côté : des exemples d’utilisation, comment le consommer, ce qui en dépend, comment il se connecte au reste du système. Un développeur lisant la documentation peut comprendre l’implémentation mais n’a toujours aucune idée de la manière d’utiliser réellement le composant ou de ce qui se casse s’il modifie son interface.
Un exemple concret
Considérez deux manières dont une IA pourrait générer un système de notification utilisateur :
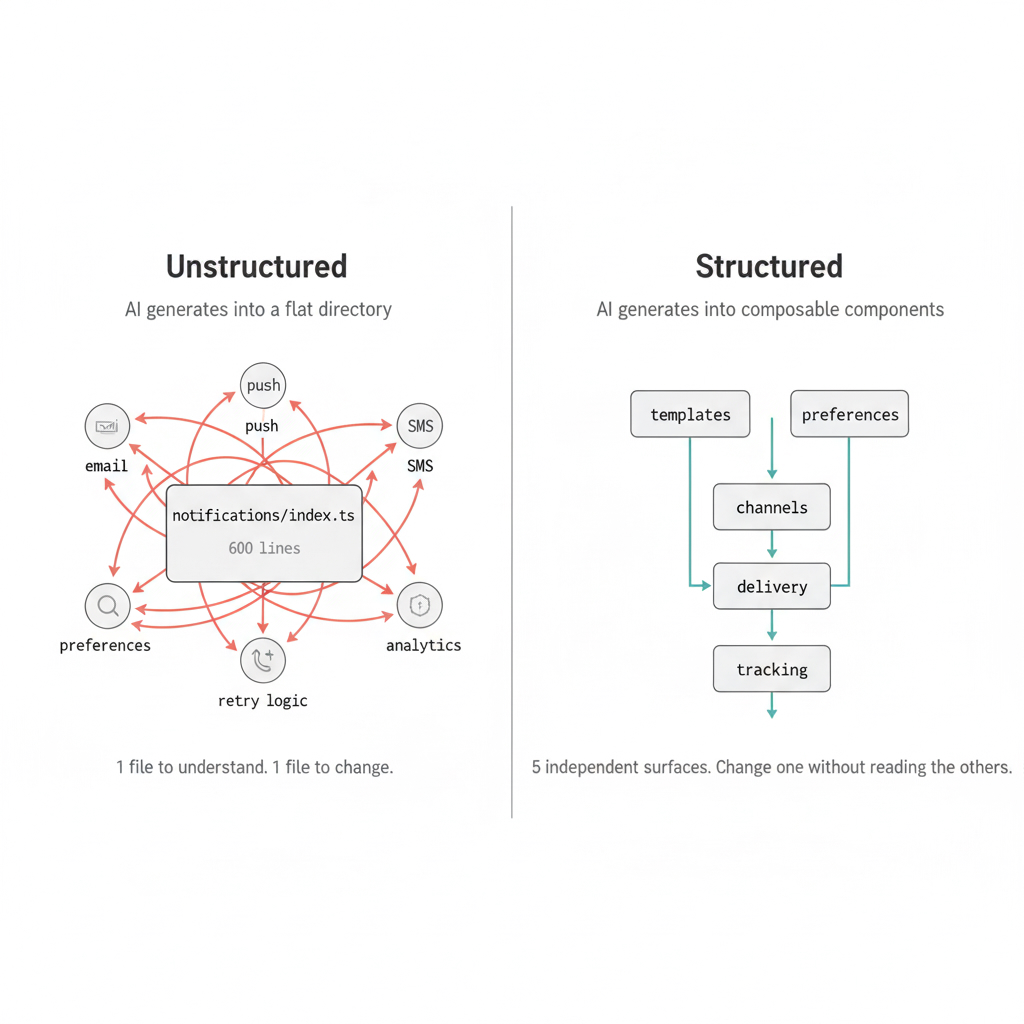
Génération non structurée produit un seul module :
notifications/
├── index.ts # 600 lines: templates, sending logic,
│ # user preferences, delivery tracking,
│ # retry logic, analytics events
├── helpers.ts # Shared utilities (used by... everything?)
└── types.ts # 40 interfaces, unclear which are publicRésultat: 1 dossier pour tout comprendre. 1 fichier pour changer quoi que ce soit.
Les dépendances sont importées directement. Changer de fournisseur de messagerie signifie modifier le même fichier qui gère les notifications push. Les tests nécessitent de se moquer de l’ensemble du système. Un nouveau développeur doit lire les 600 lignes pour comprendre un comportement unique.
Génération structurée décompose la même fonctionnalité :
notifications/
├── templates/ # Template rendering (pure functions, independently testable)
├── channels/ # Email, push, SMS, each with declared interface
├── preferences/ # User preference storage and resolution
├── delivery/ # Send logic with retry, depends on channels/
└── tracking/ # Delivery analytics, depends on delivery/Résultat: 5 surfaces indépendantes. Changez-en un sans lire les autres.
Chaque sous-domaine déclare explicitement ses dépendances. Les consommateurs importent des interfaces typées, pas des implémentations. Vous pouvez tester, remplacer ou modifier chaque pièce individuellement. Un nouveau développeur peut comprendre preferences/ sans jamais ouvrir delivery/. Le graphique de dépendances est inspectable, vous n’avez donc pas besoin de le reconstruire à partir d’instructions d’importation dispersées.
Les deux implémentations produisent un comportement d’exécution identique. La différence est entièrement structurelle. Et c’est cette différence structurelle qui détermine si le système est encore maintenable dans quelques mois.
Le principe de composabilité
Ce qui sépare ces deux résultats est composabilité: construire des systèmes à partir de composants avec des limites bien définies, des dépendances déclarées et une testabilité isolée.
Rien de tout cela n’est nouveau. Architecture basée sur des composants, microservices, microfrontends, systèmes de plugins, modèles de modules. Ils expriment tous une certaine version de composabilité. Ce qui est nouveau, c’est l’évolutivité : l’IA génère du code plus rapidement que quiconque ne peut le structurer manuellement.
Les systèmes composables ont des propriétés spécifiques et mesurables :
| ✨ Propriété | ✅ Composable (structuré) | 🛑 Boîte noire (non structurée) |
|---|---|---|
| Frontières | Explicite (déclaré par composant) | Implicite (convention, le cas échéant) |
| Dépendances | Déclaré et validé au moment de la construction | Caché dans les chaînes d’importation |
| Testabilité | Chaque composant testable isolément | Nécessite de se moquer du monde |
| Remplaçabilité | Sûr (contrat d’interface conservé) | Risqué (effets en aval inconnus) |
| Intégration | Auto-documentation via la structure | Nécessite de l’archéologie |
Voici ce qui compte : la composabilité n’est pas un attribut de qualité que vous ajoutez après génération. C’est un contrainte qui doit exister lors de la génération. Si l’IA génère dans un répertoire plat sans contraintes, la sortie ne sera pas structurée, quelle que soit la qualité du modèle.
La plupart des flux de travail de codage d’IA actuels ne sont pas à la hauteur ici. Le modèle est performant, mais l’environnement cible ne lui donne aucun retour structurel. Vous obtenez donc du code qui s’exécute mais n’a aucune intention architecturale.
À quoi ressemble la rétroaction structurelle
Alors, que faudrait-il pour que le code généré par l’IA soit composable par défaut ?
Cela se résume aux commentaires, en particulier retour structurel de l’environnement cible pendant la générationpas après.
Lorsqu’un développeur écrit du code, il reçoit des signaux : erreurs de type, échecs de tests, violations de peluchage, vérifications CI. Ces signaux contraignent la sortie à l’exactitude. Le code généré par l’IA n’obtient généralement rien de tout cela lors de la génération. Il est produit en un seul passage et évalué après coup, voire pas du tout.
Qu’est-ce qui change lorsque l’objectif de production fournit des signaux structurels en temps réel ?
- « Ce composant a une dépendance non déclarée »forçant des graphiques de dépendances explicites
- « Cette interface ne correspond pas aux attentes de ses consommateurs »faire respecter les contrats
- « Ce test échoue de manière isolée »attrapant le couplage caché
- « Ce module dépasse sa limite déclarée »empêchant la dérive de la portée ou les dépendances cycliques
Des outils comme Bit et Nx fournissent déjà ces signaux aux développeurs humains. Le changement leur fournit pendant génération, afin que l’IA puisse corriger sa trajectoire avant que les dommages structurels ne soient causés.
Dans mon travail chez Bit Cloud, nous avons intégré cette boucle de rétroaction dans le processus de génération lui-même. Lorsque notre IA génère des composants, chacun est validé en temps réel par rapport aux contraintes structurelles de la plateforme : frontières, dépendances, tests, interfaces typées. L’IA ne parvient pas à produire un module de 600 lignes avec couplage caché, car l’environnement le rejette avant qu’il ne soit validé. C’est l’application de l’architecture au moment de la génération.
La structure doit être une contrainte de premier ordre lors de la génération, et non quelque chose que vous révisez par la suite.
La vraie question : à quelle vitesse pouvez-vous passer à la production et garder le contrôle
Nous avons tendance à mesurer la productivité de l’IA en fonction de la vitesse de génération. Mais la question qui compte réellement est la suivante : à quelle vitesse pouvez-vous passer du code généré par l’IA à la production tout en étant capable de changer les choses la semaine prochaine ?
Cela se décline en quelques problèmes concrets. Pouvez-vous revoir ce que l’IA a généré ? Ne vous contentez pas de le lire, mais examinez-le, comme vous le feriez pour une pull request. Pouvez-vous comprendre les limites, les dépendances, l’intention ? Un coéquipier peut-il faire de même ?
Alors : pouvez-vous l’expédier ? Est-ce qu’il y a des tests ? Les contrats sont-ils suffisamment explicites pour que vous lui fassiez confiance en production ? Ou y a-t-il un écart entre « ça fonctionne localement » et « nous pouvons déployer cela » ?
Et après sa mise en ligne : pouvez-vous continuer à le modifier ? Pouvez-vous ajouter une fonctionnalité sans relire tout le module ? Un nouveau membre de l’équipe peut-il effectuer un changement en toute sécurité sans archéologie ?
Si l’IA vous fait gagner 10 heures en écrivant du code mais que vous en passez 40 à le mettre en qualité de production, ou si vous l’expédiez rapidement mais en perdez le contrôle un mois plus tard, vous n’avez rien gagné. La dette commence le deuxième jour et s’aggrave.
Les équipes qui évoluent réellement rapidement avec l’IA sont celles qui peuvent répondre oui aux trois : révisable, livrable, modifiable. Ce n’est pas une question de modèle. Il s’agit de savoir dans quoi le code atterrit.
Implications pratiques
Pour le code que vous générez maintenant
Traitez chaque génération d’IA comme une décision limite. Avant de demander, définissez : de quoi ce composant est-il responsable ? De quoi ça dépend ? Quelle est son interface publique ? Ces contraintes dans l’invite produisent un meilleur résultat que la génération ouverte. Vous donnez à l’IA une intention architecturale, pas seulement des exigences fonctionnelles.
Pour les systèmes que vous avez déjà générés
Audit de couplage implicite. Le code le plus risqué n’est pas un code qui ne fonctionne pas, c’est un code qui fonctionne mais qui ne peut pas être maintenu. Recherchez des modules avec des responsabilités mixtes, des dépendances circulaires, des composants qui ne peuvent pas être testés sans lancer l’application complète. Portez une attention particulière au code généré au cours d’une seule session d’IA. Vous pouvez également tirer parti de l’IA pour effectuer des examens approfondis sur des normes spécifiques qui vous intéressent.
Pour choisir les outils et les plateformes
Évaluez les outils de codage d’IA en fonction de ce qui se passe après la génération. Pouvez-vous revoir structurellement le résultat ? Les dépendances sont-elles déclarées ou déduites ? Pouvez-vous tester une seule unité générée de manière isolée ? Pouvez-vous inspecter le graphique de dépendance ? Les réponses déterminent si vous arriverez rapidement à la production et garderez le contrôle, ou si vous y arriverez rapidement et le perdrez.
Conclusion
Le code généré par l’IA n’est pas le problème. Non structuré Le code généré par l’IA l’est.
Le problème de la boîte noire peut être résolu, mais pas uniquement par de meilleures incitations. Cela nécessite des environnements de génération qui appliquent la structure : limites explicites des composants, graphiques de dépendances validés, tests par composant et contrats d’interface.
À quoi cela ressemble en pratique : une seule description de produit, des centaines de composants testés et régis. C’est le sujet d’un article de suivi.
La boîte noire est réelle. Mais c’est un problème d’environnement, pas un problème d’IA. Corrigez l’environnement et l’IA génère du code que vous pouvez réellement expédier et maintenir.
Yonatan Sason est co-fondateur de Nuage de bitsoù son équipe construit une infrastructure pour un développement structuré assisté par l’IA. Yonatan a passé la dernière décennie à travailler sur une architecture basée sur des composants et les deux dernières années à l’appliquer aux plates-formes générées par l’IA. Les modèles de cet article proviennent de ce travail.
Peu est open source. Pour en savoir plus sur l’architecture composable et la génération d’IA structurée, visitez bit.dev.
Le propriétaire de Towards Data Science, Insight Partners, investit également dans Bit Cloud. En conséquence, Bit Cloud est privilégié en tant que contributeur.
You may also like


