

La règle que tout le monde manque : comment arrêter de confondre loc et iloc dans Pandas
avec les pandas, vous êtes probablement tombé sur cette confusion classique : faut-il utiliser loc ou iloc extraire des données ? À première vue, ils semblent presque identiques. Les deux sont utilisés pour découper, filtrer et récupérer des lignes ou des colonnes d’un DataFrame. Pourtant, une infime différence dans leur fonctionnement peut complètement modifier vos résultats (ou générer une erreur qui vous laisse perplexe).
Je me souviens de la première fois que j’ai essayé de sélectionner une ligne avec df.loc[0] et je me demandais pourquoi ça ne marchait pas. La raison ? Les pandas ne « pensent » pas toujours en termes de positions – ils utilisent parfois des étiquettes. C’est là que le loc contre iloc la distinction entre en jeu.
Dans cet article, je vais parcourir un mini-projet simple utilisant un petit ensemble de données sur les performances des élèves. À la fin, vous comprendrez non seulement la différence entre loc et ilocmais sachez également exactement quand les utiliser dans votre propre analyse de données.
Présentation de l’ensemble de données
L’ensemble de données provient de ChatGPT. Il contient quelques relevés de résultats aux examens de base des étudiants. Voici un instantané de notre ensemble de données
import pandas as pd
df = pd.read_csv(‘student_scores.csv’)
dfSortir:

Je vais essayer d’effectuer certaines tâches d’extraction de données en utilisant loc et iloc, comme
- Extraire une seule ligne du DataFrame
- Extraire une seule valeur
- Extraire plusieurs lignes
- Découper une plage de lignes
- Extraire des colonnes spécifiques et
Filtrage booléen
Tout d’abord, permettez-moi d’expliquer brièvement ce que sont loc et iloc dans Pandas.
Qu’est-ce que loc et iloc
Loc et iloc sont des techniques d’extraction de données dans Pandas. Ils sont très utiles pour sélectionner des données dans des enregistrements.
Loc utilise des étiquettes pour récupérer des enregistrements d’un DataFrame, je trouve donc cela plus facile à utiliser. Iloc, cependant, est utile pour une récupération plus précise des enregistrements, car iloc sélectionne les données en fonction des positions entières des lignes et des colonnes, de la même manière que vous indexiez une liste ou un tableau Python.
Mais si vous êtes comme moi, vous vous demandez peut-être. Si la localisation est clairement plus facile à cause des étiquettes de lignes, pourquoi s’embêter à utiliser iloc ? Pourquoi s’embêter à essayer de comprendre les index de lignes, surtout si vous avez affaire à de grands ensembles de données ? Voici quelques raisons.
- Bien souvent, les ensembles de données ne sont pas accompagnés d’index de lignes soignés (comme 101, 102,…). Au lieu de cela, vous avez un index simple (
0, 1, 2, …), ou vous risquez de mal orthographier l’étiquetage des lignes lors de la récupération des enregistrements. Dans ce cas, il vaut mieux utiliser iloc. Plus loin dans cet article, c’est un sujet que nous aborderons également. - Dans certains scénarios, comme le prétraitement du machine learning, les étiquettes n’ont pas vraiment d’importance. Vous ne vous souciez que d’un instantané des données. Par exemple, le premier ou les trois derniers enregistrements. iloc est vraiment utile dans ce scénario.
ilocrend le code plus court et moins fragile, surtout si les étiquettes changent, ce qui pourrait briser votre modèle d’apprentissage automatique - De nombreux ensembles de données comportent des étiquettes de ligne en double. Dans ce cas,
ilocfonctionne toujours puisque les postes sont uniques. - En fin de compte, utilisez loc lorsque votre ensemble de données comporte des étiquettes claires et significatives et que vous souhaitez que votre code soit lisible.
- Utilisez iloc lorsque vous avez besoin d’un contrôle basé sur la position ou lorsque les étiquettes sont manquantes/désordonnées.
Maintenant que j’ai mis les choses au clair, voici la syntaxe de base pour loc et iloc ci-dessous :
df.loc[rows, columns]
df.iloc[rows, columns]La syntaxe est à peu près la même. Avec cette syntaxe, essayons de récupérer quelques enregistrements en utilisant loc et iloc.
Extraire une seule ligne du DataFrame
Pour faire une démonstration appropriée, modifions d’abord l’index de la colonne et rendons-le student_id. Actuellement, les pandas s’indexent automatiquement :
# setting student_id as index
df.set_index('student_id', inplace=True)Voici le résultat :

Ça a l’air mieux. Essayons maintenant de récupérer tous les enregistrements de Bob. Voici comment aborder cela en utilisant loc :
df.loc[102]Tout ce que je fais ici, c’est spécifier l’étiquette de la ligne. Cela devrait récupérer tous les enregistrements de Bob.
Voici le résultat :
name Bob
math 58
english 64
science 70
Name: 102, dtype: objectCe qui est cool, c’est que je peux approfondir, un peu comme une hiérarchie. Par exemple, essayons de récupérer des informations spécifiques sur Bob, comme son score en mathématiques.
df.loc[102, ‘math’]La sortie serait 58.
Essayons maintenant ceci en utilisant iloc. Si vous êtes familier avec les listes et les tableaux, l’indexation commence toujours à 0. Donc, si je veux récupérer le premier enregistrement du DataFrame, je devrai spécifier l’index 0. Dans ce cas, j’essaie de récupérer Bob, qui est la deuxième ligne de notre DataFrame — donc, dans ce cas, l’index serait 1.
df.iloc[1]Nous obtiendrions le même résultat que ci-dessus :
name Bob
math 58
english 64
science 70
Name: 102, dtype: objectEt si j’essaie d’explorer et de récupérer le score mathématique de Bob. Notre indice serait également 1, étant donné que les mathématiques sont sur la deuxième ligne
df.iloc[1, 1]La sortie serait 58.
D’accord, je peux conclure cet article ici, mais loc et iloc offrent des fonctionnalités plus impressionnantes. Passons en revue quelques-uns d’entre eux.
Extraire plusieurs lignes (étudiants spécifiques)
Pandas vous permet de récupérer plusieurs lignes en utilisant loc et iloc. Je vais faire une démonstration en récupérant les dossiers de plusieurs étudiants. Dans ce cas, au lieu de stocker une seule valeur dans notre méthode loc/iloc, nous stockerions une liste. Voici comment procéder avec loc :
# Alice, Charlie and Edward's records
df.loc[[101, 103, 105]]Voici le résultat :

Et voici comment procéder avec iloc:
df.iloc[[0, 2, 4]]Nous obtiendrions le même résultat :

J’espère que vous comprenez.
Découper une plage de lignes
Une autre fonctionnalité utile offerte par Python Pandas est la possibilité de découper une plage de lignes. Ici, vous pouvez spécifier votre position de début et de fin. Voici la syntaxe du découpage loc/iloc :
df.loc[start_label:end_label]Dans loccependant, l’étiquette de fin serait incluse dans la sortie – ce qui est assez différent du découpage Python par défaut.
La syntaxe est la même pour ilocà l’exception du fait que l’étiquette de fin serait exclue de la sortie (tout comme le découpage Python par défaut).
Passons en revue un exemple :
J’essaie de récupérer une série de dossiers d’élèves. Essayons cela en utilisant loc:
df.loc[101:103]Sortir:

Comme vous pouvez le voir ci-dessus, l’étiquette de fin est incluse dans le résultat. Maintenant, essayons cela en utilisant iloc. Si vous vous en souvenez, l’indice de la première ligne serait 0, ce qui signifierait que la troisième ligne serait 2.
df.iloc[0:3]Sortir:

Ici, la troisième ligne est exclue. Mais si vous êtes comme moi (quelqu’un qui remet beaucoup les choses en question), vous vous demandez peut-être : pourquoi voudriez-vous que la dernière ligne soit exclue ? Dans quels scénarios cela serait-il utile ? Et si je vous disais que cela vous facilite la vie ? Mettons les choses au clair très rapidement.
En supposant que vous souhaitiez traiter votre DataFrame en morceaux de 100 lignes chacun.
Si le découpage était inclusif, vous devrez faire des calculs délicats pour éviter de répéter la dernière ligne.
Mais comme le découpage est exclusif à la fin, vous pouvez le faire assez facilement, comme ceci.
df.iloc[0:100] # first 100 rows
df.iloc[100:200] # next 100 rows
df.iloc[200:300] # next 100 rowsIci, il n’y aura pas de chevauchements et les tailles de morceaux seront cohérentes. Une autre raison est que cela ressemble au fonctionnement des plages dans Pandas. Habituellement, lorsque vous souhaitez récupérer une plage de lignes, cela commence également à 0 et n’inclut pas la dernière ligne. Avoir cette même logique dans le découpage iloc est vraiment utile, en particulier lorsque vous travaillez sur du web scraping ou que vous parcourez une série de lignes.
Extraire des colonnes spécifiques (sujets)
J’aimerais aussi vous présenter le côlon : signe. Cela vous permet de récupérer tous les enregistrements de votre DataFrame en utilisant loc. Semblable au * en SQL. Ce qui est intéressant, c’est que vous pouvez filtrer et extraire un sous-ensemble de colonnes.
C’est généralement par là que je commence. Je l’utilise pour avoir un aperçu d’un ensemble de données particulier. À partir de là, je peux commencer à filtrer et à approfondir. Laissez-moi vous montrer ce que je veux dire.
Récupérons tous les enregistrements :
df.loc[:]Sortir:

À partir de là, je peux extraire des colonnes spécifiques comme ceci. Avec localisation :
df.loc[:, [‘math’, ‘science’]]Sortir:

Avec iloc:
df.iloc[:, [2, 4]]Le résultat serait le même.
J’adore cette fonctionnalité car elle est très flexible. Disons que je souhaite récupérer les résultats en mathématiques et en sciences d’Alice et Bob. Ça ressemblera à quelque chose comme ça. Je peux simplement spécifier la plage d’enregistrements et de colonnes que je souhaite.
Avec loc:
df.loc[101:103, ['name', 'math', 'science']]Sortir:

Avec iloc :
df.iloc[0:3, [0, 1, 3]]Nous obtiendrions le même résultat.
Filtrage booléen (Qui a obtenu un score supérieur à 80 en mathématiques ?)
La dernière fonctionnalité que je souhaite partager avec vous est le filtrage booléen. Cela permet une extraction plus flexible. Disons que je souhaite récupérer les dossiers des élèves ayant obtenu un score supérieur à 80 en mathématiques. Habituellement, en SQL, vous devrez utiliser les clauses WHERE et HAVING. Python rend cela si simple.
# Students with Math > 80.
df.loc[df['math'] > 80]Sortir:

Vous pouvez également filtrer sur plusieurs conditions à l’aide des opérateurs AND(&), OR(|) et NOT(~). Par exemple:
# Math > 70 and Science > 80
df.loc[(df[‘math’] > 70) & (df[‘science’] > 80)]Sortir: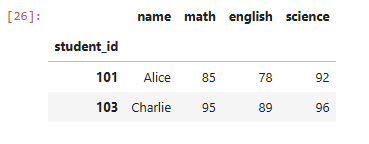 PS J’ai écrit un article sur le filtrage avec Pandas. Vous pouvez le lire ici
PS J’ai écrit un article sur le filtrage avec Pandas. Vous pouvez le lire ici
Habituellement, vous vous retrouverez à utiliser cette fonctionnalité avec loc. Cela peut devenir un peu compliqué avec iloccar il ne prend pas en charge les conditions booléennes. Pour faire cela avec iloc, vous devrez convertir le filtrage booléen en liste, comme ceci :
# Students with Math > 80.
df.iloc[list(df['math'] > 80)]Pour éviter les maux de tête, optez simplement pour loc.
Conclusion
Vous utiliserez probablement le loc et iloc méthodes beaucoup lorsque vous travaillez sur un ensemble de données. Il est donc crucial de savoir comment ils fonctionnent et de distinguer les deux. J’aime à quel point il est facile et flexible d’extraire des enregistrements avec ces méthodes. Chaque fois que vous êtes confus, rappelez-vous simplement que loc concerne les étiquettes tandis qu’iloc concerne les positions.
J’espère que vous avez trouvé cet article utile. Essayez d’exécuter ces exemples sur votre propre ensemble de données pour voir la différence en action.
J’écris ces articles pour tester et renforcer ma propre compréhension des concepts techniques et pour partager ce que j’apprends avec d’autres personnes susceptibles de suivre le même chemin. N’hésitez pas à partager avec les autres. Apprenons et grandissons ensemble. Acclamations!
N’hésitez pas à nous dire bonjour sur l’une de ces plateformes


