

Arrêtez d’écrire des masques booléens désordonnés : 10 façons élégantes de filtrer les dataFrames Pandas
j’ai expliqué comment créer votre premier DataFrame à l’aide de Pandas. J’ai mentionné que la première chose que vous devez maîtriser est les structures et les tableaux de données avant de passer à l’analyse des données avec Python.
Pandas est une excellente bibliothèque pour la manipulation et la récupération de données. Combinez-le avec Numpy et Seaborne et vous obtenez une centrale d’analyse de données.
Dans cet article, je vais vous expliquer des moyens pratiques de filtrer les données chez les pandasen commençant par des conditions simples et en passant à des méthodes puissantes comme .isin(), .str.startswith()et .query(). À la fin, vous disposerez d’une boîte à outils de techniques de filtrage que vous pourrez appliquer à n’importe quel ensemble de données.
Sans plus attendre, entrons dans le vif du sujet !
Importer nos données
Ok, pour commencer, je vais importer notre bibliothèque pandas
# importing the pandas library
import pandas as pdC’est la seule bibliothèque dont j’aurai besoin pour ce cas d’utilisation
Ensuite, j’importerai l’ensemble de données. L’ensemble de données provient de ChatGPT, d’ailleurs. Il se compose d’enregistrements de base des transactions de vente. Jetons un coup d’œil à notre ensemble de données.
# checking out our data
df_sales = pd.read_csv('sales_data.csv')
df_salesVoici un aperçu des données

Il se compose d’enregistrements de ventes de base avec les colonnes OrderId, Customer, Product, Category, Quantity, Price, OrderDate et Region.
Très bien, commençons notre filtrage !
Filtrage par une seule condition
Essayons de sélectionner tous les enregistrements d’une catégorie particulière. Par exemple, je souhaite savoir combien de commandes uniques ont été effectuées dans la catégorie Électronique. Pour ce faire, c’est assez simple
# Filter by a single condition
# Example: All orders from the “Electronics” category.
df_sales[‘Category’] == ‘Electronics’En Python, vous devez faire la distinction entre les = l’opérateur et le == opérateur.
= est utilisé pour attribuer une valeur à une variable.
Par exemple
x = 10 # Assigns the value 10 to the variable x== d’autre part, il est utilisé pour comparer deux valeurs ensemble. Par exemple
a = 3
b = 3
print(a == b) # Output: True
c = 5
d = 10
print(c == d) # Output: FalseCela dit, appliquons la même notion au filtrage que j’ai fait ci-dessus
# Filter by a single condition
# Example: All orders from the “Electronics” category.
df_sales[‘Category’] == ‘Electronics’Ici, je dis essentiellement à Python de parcourir l’ensemble de notre dossier pour trouver une catégorie nommée Electronique. Lorsqu’il trouve une correspondance, il affiche un résultat booléen, True ou False. Voici le résultat

Comme vous pouvez le voir. Nous obtenons une sortie booléenne. Vrai signifie que l’électronique existe, tandis que Faux signifie cette dernière. C’est correct et tout, mais cela peut devenir déroutant si vous avez affaire à un grand nombre d’enregistrements. Réparons ça.
# Filter by a single condition
# Example: All orders from the “Electronics” category.
df_sales[df_sales[‘Category’] == ‘Electronics’]Ici, je viens d’envelopper la condition dans le DataFrame. Et avec ça, nous obtenons ce résultat

Beaucoup mieux, non ? Passons à autre chose
Filtrer les lignes par condition numérique
Essayons de récupérer les enregistrements dont la quantité commandée est supérieure à 2. C’est assez simple.
# Filter rows by numeric condition
# Example: Orders where Quantity > 2
df_sales[‘Quantity’] > 2Ici, j’utilise l’opérateur supérieur à >. Semblable à notre résultat ci-dessus, nous allons obtenir un résultat booléen avec des valeurs Vrai et Faux. Réparons ça très vite.

Et voilà !
Filtrer par condition de date
Le filtrage par date est simple. Par exemple.
# Filter by date condition
# Example: Orders placed after “2023–01–08”
df_sales[df_sales[“OrderDate”] > “2023–01–08”]Cela vérifie les commandes passées après le 8 janvier 2023. Et voici le résultat.

L’avantage de Pandas est qu’il convertit automatiquement les types de données chaîne en dates. Dans les cas où vous rencontrez une erreur. Vous souhaiterez peut-être convertir en date avant de filtrer à l’aide de l’option to_datetime() fonction. Voici un exemple
df[“OrderDate”] = pd.to_datetime(df[“OrderDate”])Cela convertit notre colonne OrderDate en un type de données date. Passons à la vitesse supérieure.
Filtrage par plusieurs conditions (ET, OU, NON)
Pandas nous permet de filtrer sur plusieurs conditions à l’aide d’opérateurs logiques. Cependant, ces opérateurs sont différents des opérateurs intégrés de Python comme (and, or, not). Voici les opérateurs logiques avec lesquels vous travaillerez le plus
& (ET logique)
L’esperluette (&) le symbole représente ET dans les pandas. Nous l’utilisons lorsque nous essayons de remplir deux conditions. Dans ce cas, les deux conditions doivent être vraies. Par exemple, récupérons les commandes de la catégorie « Mobilier » où Prix > 500.
# Multiple conditions (AND)
# Example: Orders from “Furniture” where Price > 500
df_sales[(df_sales[“Category”] == “Furniture”) & (df_sales[“Price”] > 500)]Décomposons cela. Ici, nous avons deux conditions. Un qui récupère les commandes dans la catégorie Meubles et un autre qui filtre les prix > 500. Grâce au &, nous pouvons combiner les deux conditions.
Voici le résultat.

Un enregistrement a pu être récupéré. En le regardant, cela répond à notre condition. Faisons de même pour OR
| (OU logique)
Le |,Le symbole de la barre verticale est utilisé pour représenter OU dans les pandas. Dans ce cas, au moins un des éléments correspondants doit être True. Par exemple, récupérons les enregistrements avec les commandes de la région « Nord » OU de la région « Est ».
# Multiple conditions (OR)
# Example: Orders from “North” region OR “East” region.
df_sales[(df_sales[“Region”] == “North”) | (df_sales[“Region”] == “East”)]Voici le résultat

Filtrer avec isin()
Disons que je souhaite récupérer les commandes de plusieurs clients. Je pourrais toujours utiliser l’opérateur &. Par exemple
df_sales[(df_sales[‘Customer’] == ‘Alice’) | (df_sales[‘Customer’] == ‘Charlie’)]Sortir:

Il n’y a rien de mal à ça. Mais il existe un moyen meilleur et plus simple de procéder. C’est en utilisant le isin() fonction. Voici comment ça marche
# Orders from customers ["Alice", "Diana", "James"].
df_sales[df_sales[“Customer”].isin([“Alice”, “Diana”, “James”])]Sortir:

Le code est beaucoup plus simple et plus propre. En utilisant le isin() fonction, je peux ajouter autant de paramètres que je veux. Passons à d’autres choses filtrage avancé.
Filtrer en utilisant la correspondance de chaînes
L’une des fonctions puissantes mais sous-utilisées de Pandas est la correspondance de chaînes. Cela aide énormément dans les tâches de nettoyage des données lorsque vous essayez de rechercher des modèles dans les enregistrements de votre DataFrame. Semblable à l’opérateur LIKE dans SQL. Par exemple, récupérons les clients dont le nom commence par « A ».
# Customers whose name starts with "A".
df_sales[df_sales[“Customer”].str.startswith(“A”)]Sortir:

Pandas vous donne le .str accesseur pour utiliser les fonctions de chaîne. Voici un autre exemple
# Products ending with “top” (e.g., Laptop).
df_sales[df_sales[“Product”].str.endswith(“top”)]Sortir:

Filtrer à l’aide de la méthode query()
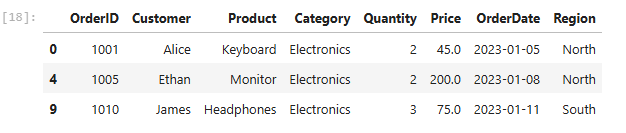
Si vous venez d’un contexte SQL, cette méthode vous serait très utile. Essayons de récupérer les commandes de la catégorie électronique où la quantité > 2. Cela peut toujours se passer comme ça.
df_sales[(df_sales[“Category”] == “Electronics”) & (df_sales[“Quantity”] >= 2)]Sortir:
Mais si vous êtes quelqu’un qui essaie d’apporter votre sauce SQL. Cela fonctionnera pour vous à la place
df.query(“Category == ‘Electronics’ and Quantity >= 2”)Vous obtiendrez le même résultat ci-dessus. Assez similaire à SQL si vous me le demandez, et vous pourrez abandonner le & symbole. Je vais utiliser cette méthode assez souvent.
Filtrer par valeurs de colonne dans une plage
Pandas vous permet de récupérer une plage de valeurs. Par exemple, les commandes dont le prix est compris entre 50 et 500 se dérouleraient comme ceci
# Orders where the Price is between 50 and 500
df_sales[df_sales[“Price”].between(50, 500)]Sortir:

Assez simple.
Filtrer les valeurs manquantes (NaN)
C’est probablement la fonction la plus utile car, en tant qu’analyste de données, l’une des tâches de nettoyage des données sur laquelle vous travaillerez le plus consiste à filtrer les valeurs manquantes. Faire cela dans Pandas est simple. C’est en utilisant le notna() fonction. Filtrons les lignes où Price n’est pas nul.
# filter rows where Price is not null.
df_sales[df_sales[“Price”].notna()]Sortir:

Et voilà. Cependant, je ne remarque pas vraiment la différence, mais je vais croire que c’est fait.
Conclusion
La prochaine fois que vous ouvrirez un CSV en désordre et que vous vous demanderez « Par où dois-je commencer? »essayez d’abord de filtrer. C’est le moyen le plus rapide d’éliminer le bruit et de découvrir l’histoire cachée dans vos données.
La transition vers Python pour l’analyse des données semblait autrefois être une étape énorme, venant d’un contexte SQL. Mais pour une raison quelconque, Pandas me semble beaucoup plus facile et prend moins de temps pour filtrer les données.
Ce qui est intéressant, c’est que ces mêmes techniques fonctionnent quel que soit l’ensemble de données : chiffres de ventes, réponses à des enquêtes, analyses Web, etc.
J’espère que vous avez trouvé cet article utile.
J’écris ces articles pour tester et renforcer ma propre compréhension des concepts techniques et pour partager ce que j’apprends avec d’autres personnes susceptibles de suivre le même chemin. N’hésitez pas à partager avec les autres. Apprenons et grandissons ensemble. Acclamations!
N’hésitez pas à nous dire bonjour sur l’une de ces plateformes


