

Mesurer ce qui compte avec NeMo Agent Toolkit
Après une décennie de travail dans l’analyse, je crois fermement que l’observabilité et l’évaluation sont essentielles pour toute application LLM exécutée en production. La surveillance et les mesures ne sont pas seulement utiles. Ils garantissent que votre produit fonctionne comme prévu et que chaque nouvelle mise à jour vous avance réellement dans la bonne direction.
Dans cet article, je souhaite partager mon expérience avec les fonctionnalités d’observabilité et d’évaluation de NeMo Agent Toolkit (NAT). Si vous n’avez pas lu mon article précédent sur NAT, voici un petit rappel : NAT est le framework de Nvidia pour créer des applications LLM prêtes pour la production. Considérez-le comme le ciment qui relie les LLM, les outils et les flux de travail, tout en offrant également des options de déploiement et d’observabilité.
Grâce à NAT, nous avons construit un Happiness Agent capable de répondre à des questions nuancées sur les données du rapport World Happiness et effectuer des calculs basés sur des mesures réelles. Notre objectif était de créer des flux agentiques, d’intégrer des agents d’autres frameworks en tant qu’outils (dans notre exemple, un agent de calcul basé sur LangGraph) et de déployer l’application à la fois en tant qu’API REST et en tant qu’interface conviviale.
Dans cet article, je vais plonger dans mes sujets préférés : l’observabilité et les évaluations. Après tout, comme le dit le proverbe, on ne peut pas améliorer ce qu’on ne mesure pas. Alors, sans plus tarder, allons-y.
Observabilité
Commençons par l’observabilité : la capacité de suivre ce qui se passe dans votre application, y compris toutes les étapes intermédiaires, les outils utilisés, les horaires et l’utilisation des jetons. Le NeMo Agent Toolkit s’intègre à une variété d’outils d’observabilité tels que Phoenix, W&B Weave et Catalyst. Vous pouvez toujours consulter la dernière liste des frameworks pris en charge dans le document.
Pour cet article, nous allons essayer Phoenix. Phénix est une plateforme open source pour tracer et évaluer les LLM. Avant de pouvoir commencer à l’utiliser, nous devons d’abord installer le plugin.
uv pip install arize-phoenix
uv pip install "nvidia-nat[phoenix]"Ensuite, nous pouvons lancer le serveur Phoenix.
phoenix serverUne fois opérationnel, le service de traçage sera disponible à http://localhost:6006/v1/traces. À ce stade, vous verrez un projet par défaut puisque nous n’avons encore envoyé aucune donnée.
Maintenant que le serveur Phoenix est opérationnel, voyons comment nous pouvons commencer à l’utiliser. Puisque NAT est basé sur la configuration YAML, tout ce que nous avons à faire est d’ajouter une section de télémétrie à notre configuration. Vous pouvez trouver la configuration et l’implémentation complète de l’agent sur GitHub. Si vous souhaitez en savoir plus sur le framework NAT, consultez mon article précédent.
general:
telemetry:
tracing:
phoenix:
_type: phoenix
endpoint: http://localhost:6006/v1/traces
project: happiness_reportAvec cela en place, nous pouvons exécuter notre agent.
export ANTHROPIC_API_KEY=<your_key>
source .venv_nat_uv/bin/activate
cd happiness_v3
uv pip install -e .
cd ..
nat run \
--config_file happiness_v3/src/happiness_v3/configs/config.yml \
--input "How much happier in percentages are people in Finland compared to the United Kingdom?"Lançons quelques requêtes supplémentaires pour voir quel type de données Phoenix peut suivre.
nat run \
--config_file happiness_v3/src/happiness_v3/configs/config.yml \
--input "Are people overall getting happier over time?"
nat run \
--config_file happiness_v3/src/happiness_v3/configs/config.yml \
--input "Is Switzerland on the first place?"
nat run \
--config_file happiness_v3/src/happiness_v3/configs/config.yml \
--input "What is the main contibutor to the happiness in the United Kingdom?"
nat run \
--config_file happiness_v3/src/happiness_v3/configs/config.yml \
--input "Are people in France happier than in Germany?"Après avoir exécuté ces requêtes, vous remarquerez un nouveau projet dans Phoenix (happiness_reportcomme nous l’avons défini dans la configuration) ainsi que tous les appels LLM que nous venons de faire. Cela vous donne une vision claire de ce qui se passe sous le capot.
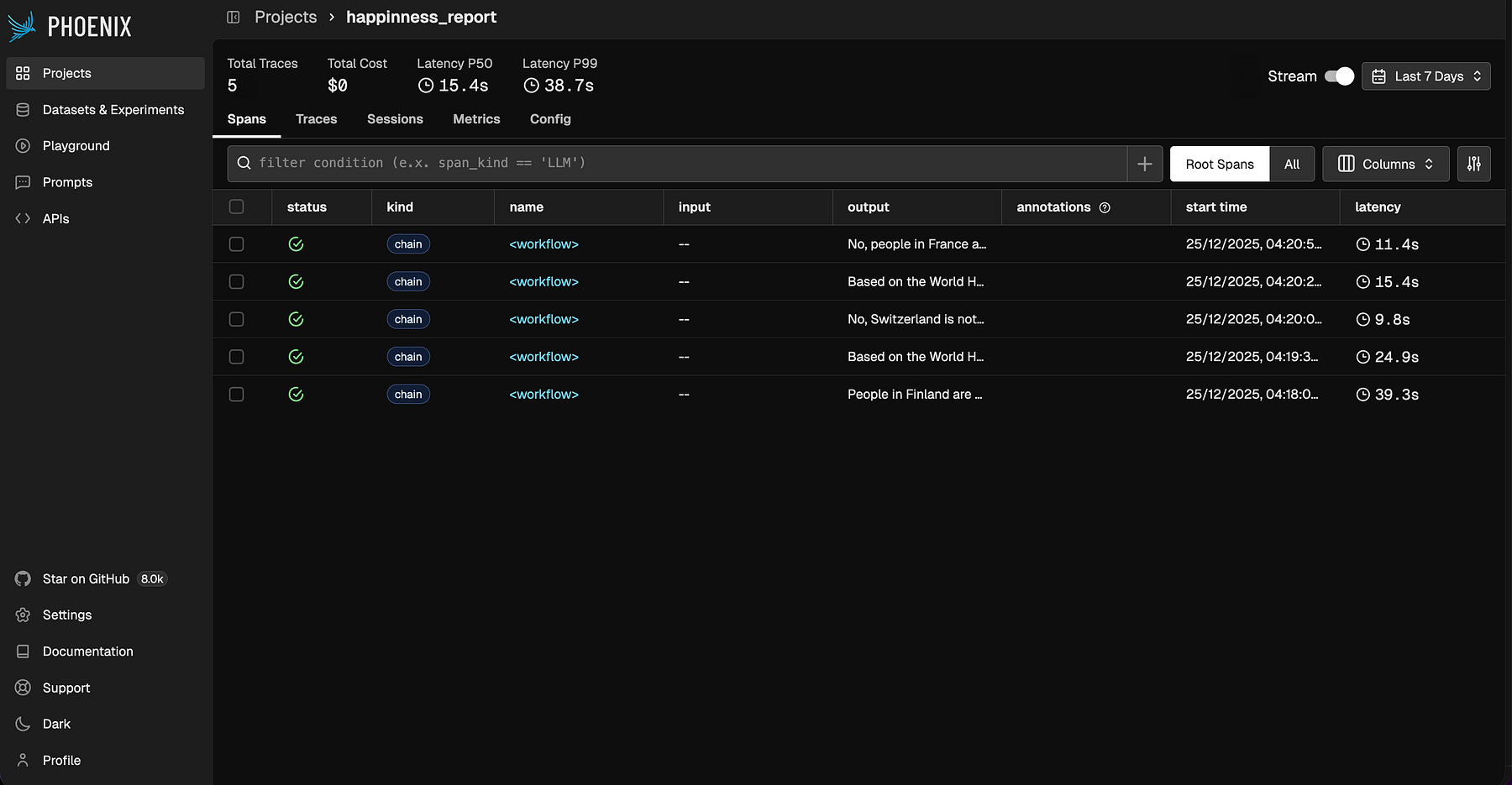
On peut zoomer sur l’une des requêtes, comme « Les gens deviennent-ils globalement plus heureux avec le temps ? »

Cette requête prend un certain temps (environ 25 secondes) car elle implique cinq appels d’outils par an. Si nous nous attendons à de nombreuses questions similaires sur les tendances globales, il peut être judicieux de doter notre agent d’un nouvel outil capable de calculer des statistiques récapitulatives en une seule fois.
C’est exactement là que l’observabilité brille : en révélant les goulots d’étranglement et les inefficacités, elle vous aide à réduire les coûts et à offrir une expérience plus fluide aux utilisateurs.
Évaluations
L’observabilité consiste à suivre le fonctionnement de votre application en production. Ces informations sont utiles, mais elles ne suffisent pas pour dire si la qualité des réponses est suffisamment bonne ou si une nouvelle version est plus performante. Pour répondre à ces questions, nous avons besoin d’évaluations. Heureusement, le NeMo Agent Toolkit peut aide nous avec des évaluations également.
Tout d’abord, rassemblons un petit ensemble d’évaluations. Nous devons spécifier seulement 3 champs : identifiant, question et réponse.
[
{
"id": "1",
"question": "In what country was the happiness score highest in 2021?",
"answer": "Finland"
},
{
"id": "2",
"question": "What contributed most to the happiness score in 2024?",
"answer": "Social Support"
},
{
"id": "3",
"question": "How UK's rank changed from 2019 to 2024?",
"answer": "The UK's rank dropped from 13th in 2019 to 23rd in 2024."
},
{
"id": "4",
"question": "Are people in France happier than in Germany based on the latest report?",
"answer": "No, Germany is at 22nd place in 2024 while France is at 33rd place."
},
{
"id": "5",
"question": "How much in percents are people in Poland happier in 2024 compared to 2019?",
"answer": "Happiness in Poland increased by 7.9% from 2019 to 2024. It was 6.1863 in 2019 and 6.6730 in 2024."
}
]Ensuite, nous devons mettre à jour notre configuration YAML pour définir où stocker les résultats de l’évaluation et où trouver l’ensemble de données d’évaluation. J’ai mis en place un site dédié eval_llm à des fins d’évaluation pour garder la solution modulaire, et j’utilise Sonnet 4.5 pour cela.
# Evaluation configuration
eval:
general:
output:
dir: ./tmp/nat/happiness_v3/eval/evals/
cleanup: false
dataset:
_type: json
file_path: src/happiness_v3/data/evals.json
evaluators:
answer_accuracy:
_type: ragas
metric: AnswerAccuracy
llm_name: eval_llm
groundedness:
_type: ragas
metric: ResponseGroundedness
llm_name: eval_llm
trajectory_accuracy:
_type: trajectory
llm_name: eval_llmJ’ai défini plusieurs évaluateurs ici. Nous nous concentrerons sur la précision des réponses et la solidité des réponses de Ragas (un framework open source pour évaluer les flux de travail LLM de bout en bout), ainsi que l’évaluation de trajectoire. Décomposons-les.
Précision des réponses mesure dans quelle mesure la réponse d’un modèle s’aligne sur une vérité terrain de référence. Il utilise deux invites « LLM-as-a-Judge », chacune renvoyant une note de 0, 2 ou 4. Ces notes sont ensuite converties en une note de 0, 2 ou 4. [0,1] échelle et moyenne. Des scores plus élevés indiquent que la réponse du modèle correspond étroitement à la référence.
- 0 → La réponse est inexacte ou hors sujet,
- 2 → La réponse s’aligne partiellement,
- 4 → La réponse s’aligne exactement.
Ancrage de la réponse évalue si une réponse est prise en charge par les contextes récupérés. Autrement dit, si chaque affirmation peut être trouvée (entièrement ou partiellement) dans les données fournies. Cela fonctionne de la même manière que l’exactitude des réponses, en utilisant deux invites distinctes « LLM-as-a-Judge » avec des notes de 0, 1 ou 2, qui sont ensuite normalisées à un [0,1] échelle.
- 0 → Pas du tout mis à la terre,
- 1 → Partiellement mis à la terre,
- 2 → Entièrement mis à la terre.
Évaluation de la trajectoire suit les étapes intermédiaires et les appels d’outils exécutés par le LLM, aidant ainsi à surveiller le processus de raisonnement. Un juge LLM évalue la trajectoire produite par le flux de travail, en tenant compte des outils utilisés lors de l’exécution. Il renvoie un score à virgule flottante compris entre 0 et 1, où 1 représente une trajectoire parfaite.
Lançons des évaluations pour voir comment cela fonctionne dans la pratique.
nat eval --config_file src/happiness_v3/configs/config.ymlÀ la suite de l’exécution des évaluations, nous obtenons plusieurs fichiers dans le répertoire de sortie que nous avons spécifié précédemment. L’un des plus utiles est workflow_output.json. Ce fichier contient les résultats d’exécution pour chaque échantillon de notre ensemble d’évaluation, y compris la question d’origine, la réponse générée par le LLM, la réponse attendue et une ventilation détaillée de toutes les étapes intermédiaires. Ce fichier peut vous aider à retracer le fonctionnement du système dans chaque cas.
Voici un exemple abrégé pour le premier échantillon.
{
"id": 1,
"question": "In what country was the happiness score highest in 2021?",
"answer": "Finland",
"generated_answer": "Finland had the highest happiness score in 2021 with a score of 7.821.",
"intermediate_steps": [...],
"expected_intermediate_steps": []
}Pour la précision des réponses et l’ancrage de la réponse, nous avons obtenu les scores les plus élevés possibles (1,0 sur 1,0 en moyenne), ce qui est toujours agréable à voir. Voici le fichier renvoyé.
{
"average_score": 1.0,
"eval_output_items": [
{
"id": 1,
"score": 1.0,
"reasoning": {
"user_input": "In what country was the happiness score highest in 2021?",
"reference": "Finland",
"response": "Finland had the highest happiness score in 2021 with a score of 7.821.",
"retrieved_contexts": [...]
}
},
{
"id": 2,
"score": 1.0,
"reasoning": {
"user_input": "What contributed most to the happiness score in 2024?",
"reference": "Social Support",
"response": "In 2024, **Social Support** contributed most to the happiness score, with an average impact of 1.333 points. This was followed very closely by **GDP per capita** with an impact of 1.319 points. These two factors were significantly more influential than other contributors like life expectancy (0.551), freedom (0.749), generosity (0.113), and perceptions of corruption (0.147). This suggests that having strong social connections and relationships, along with economic prosperity, were the primary drivers of happiness across countries in 2024.",
"retrieved_contexts": [...]
}
},
{
"id": 3,
"score": 1.0,
"reasoning": {
"user_input": "How UK's rank changed from 2019 to 2024?",
"reference": "The UK's rank dropped from 13th in 2019 to 23rd in 2024.",
"response": "The UK's rank in the World Happiness Report changed from 13th place in 2019 to 23rd place in 2024, representing a decline of 10 positions. The happiness score also decreased from 7.1645 in 2019 to 6.7280 in 2024.",
"retrieved_contexts": [...]
}
},
{
"id": 4,
"score": 1.0,
"reasoning": {
"user_input": "Are people in France happier than in Germany based on the latest report?",
"reference": "No, Germany is at 22nd place in 2024 while France is at 33rd place.",
"response": "Based on the latest 2024 World Happiness Report, people in Germany are happier than people in France. Germany has a happiness score of 6.753 (ranked 22nd globally), while France has a happiness score of 6.593 (ranked 33rd globally). The difference is 0.16 points in Germany's favor.",
"retrieved_contexts": [...]
}
},
{
"id": 5,
"score": 1.0,
"reasoning": {
"user_input": "How much in percents are people in Poland happier in 2024 compared to 2019?",
"reference": "Happiness in Poland increased by 7.9% from 2019 to 2024. It was 6.1863 in 2019 and 6.6730 in 2024.",
"response": "People in Poland are approximately 7.87% happier in 2024 compared to 2019. The happiness score increased from 6.1863 in 2019 to 6.6730 in 2024, representing an increase of 0.4867 points or about 7.87%.",
"retrieved_contexts": [...]
}
}
]
}Pour l’évaluation de la trajectoire, nous avons obtenu une note moyenne de 0,95. Pour comprendre où le modèle a échoué, regardons un exemple non idéal. Pour la cinquième question, le juge a correctement identifié que l’agent avait suivi un chemin sous-optimal : il a fallu 8 étapes pour arriver à la réponse finale, même si le même résultat aurait pu être obtenu en 4 à 5 étapes. En conséquence, cette trajectoire a reçu une note de 0,75 sur 1,0..
Let me evaluate this AI language model's performance step by step:
## Evaluation Criteria:
**i. Is the final answer helpful?**
Yes, the final answer is clear, accurate, and directly addresses the question.
It provides both the percentage increase (7.87%) and explains the underlying
data (happiness scores from 6.1863 to 6.6730). The answer is well-formatted
and easy to understand.
**ii. Does the AI language use a logical sequence of tools to answer the question?**
Yes, the sequence is logical:
1. Query country statistics for Poland
2. Retrieve the data showing happiness scores for multiple years including
2019 and 2024
3. Use a calculator to compute the percentage increase
4. Formulate the final answer
This is a sensible approach to the problem.
**iii. Does the AI language model use the tools in a helpful way?**
Yes, the tools are used appropriately:
- The `country_stats` tool successfully retrieved the relevant happiness data
- The `calculator_agent` correctly computed the percentage increase using
the proper formula
- The Python evaluation tool performed the actual calculation accurately
**iv. Does the AI language model use too many steps to answer the question?**
This is where there's some inefficiency. The model uses 8 steps total, which
includes some redundancy:
- Steps 4-7 appear to involve multiple calls to calculate the same percentage
(the calculator_agent is invoked, which then calls Claude Opus, which calls
evaluate_python, and returns through the chain)
- Step 7 seems to repeat what was already done in steps 4-6
While the answer is correct, there's unnecessary duplication. The calculation
could have been done more efficiently in 4-5 steps instead of 8.
**v. Are the appropriate tools used to answer the question?**
Yes, the tools chosen are appropriate:
- `country_stats` was the right tool to get happiness data for Poland
- `calculator_agent` was appropriate for computing the percentage change
- The underlying `evaluate_python` tool correctly performed the mathematical
calculation
## Summary:
The model successfully answered the question with accurate data and correct
calculations. The logical flow was sound, and appropriate tools were selected.
However, there was some inefficiency in the execution with redundant steps
in the calculation phase.Au vu du raisonnement, cela s’avère être une évaluation étonnamment complète de l’ensemble du flux de travail LLM. Ce qui est particulièrement intéressant, c’est qu’il fonctionne immédiatement et ne nécessite aucune donnée de vérité sur le terrain. Je conseillerais certainement d’utiliser cette évaluation pour vos candidatures.
Comparaison de différentes versions
Les évaluations deviennent particulièrement puissantes lorsque vous devez comparer différentes versions de votre application. Imaginez une équipe axée sur l’optimisation des coûts et envisageant de passer des solutions les plus coûteuses. sonnet modèle à haiku. Avec NAT, changer de modèle prend moins d’une minute, mais le faire sans valider la qualité serait risqué. C’est exactement là que les évaluations brillent.
Pour cette comparaison, nous présenterons également un autre outil d’observabilité : W&B Weave. Il fournit des visualisations particulièrement pratiques et des comparaisons côte à côte entre différentes versions de votre flux de travail.
Pour commencer, vous devrez vous inscrire sur le site W&B et obtenez une clé API. W&B est gratuit à utiliser pour des projets personnels.
export WANDB_API_KEY=<your key>Ensuite, installez les packages et plugins requis.
uv pip install wandb weave
uv pip install "nvidia-nat[weave]"Nous devons également mettre à jour notre configuration YAML. Cela inclut l’ajout de Weave à la section de télémétrie et l’introduction d’un alias de flux de travail afin que nous puissions clairement distinguer les différentes versions de l’application.
general:
telemetry:
tracing:
phoenix:
_type: phoenix
endpoint: http://localhost:6006/v1/traces
project: happiness_report
weave: # specified Weave
_type: weave
project: "nat-simple"
eval:
general:
workflow_alias: "nat-simple-sonnet-4-5" # added alias
output:
dir: ./.tmp/nat/happiness_v3/eval/evals/
cleanup: false
dataset:
_type: json
file_path: src/happiness_v3/data/evals.json
evaluators:
answer_accuracy:
_type: ragas
metric: AnswerAccuracy
llm_name: chat_llm
groundedness:
_type: ragas
metric: ResponseGroundedness
llm_name: chat_llm
trajectory_accuracy:
_type: trajectory
llm_name: chat_llmPour le haiku version, j’ai créé une configuration séparée où les deux chat_llm et calculator_llm utiliser haiku au lieu de sonnet.
Nous pouvons désormais exécuter des évaluations pour les deux versions.
nat eval --config_file src/happiness_v3/configs/config.yml
nat eval --config_file src/happiness_v3/configs/config_simple.ymlUne fois les évaluations terminées, nous pouvons nous diriger vers l’interface W&B et explorer un rapport de comparaison complet. J’aime beaucoup la visualisation du graphique radar, car elle rend les compromis immédiatement évidents.
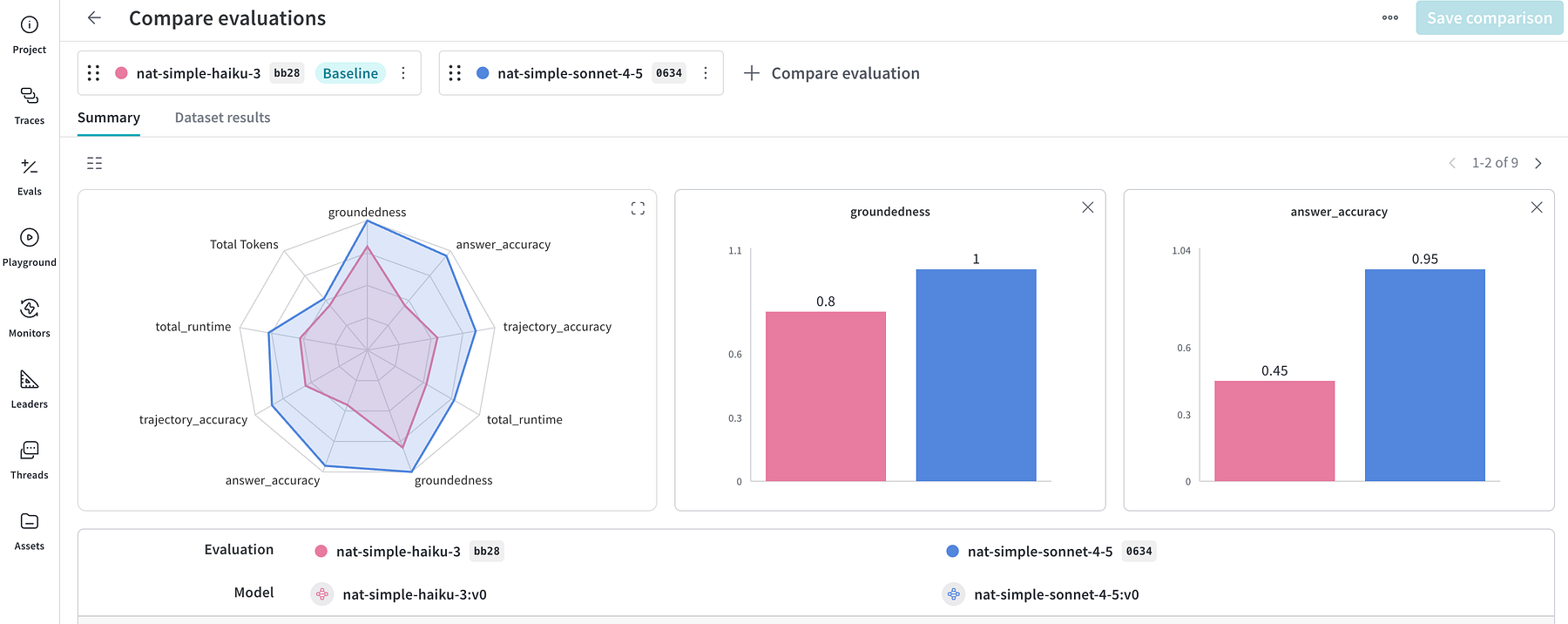

Avec sonnetnous observons une utilisation plus élevée des jetons (et un coût par jeton plus élevé) ainsi que des temps de réponse plus lents (24,8 secondes contre 16,9 secondes pour haiku). Cependant, malgré les gains évidents en termes de rapidité et de coût, je ne recommanderais pas de changer de modèle. La baisse de qualité est trop importante : la précision de la trajectoire passe de 0,85 à 0,55, et la précision des réponses passe de 0,95 à 0,45. Dans ce cas, les évaluations nous ont permis d’éviter de perturber l’expérience utilisateur dans un souci d’optimisation des coûts.
Vous pouvez trouver la mise en œuvre complète sur GitHub.
Résumé
Dans cet article, nous avons exploré les capacités d’observabilité et d’évaluation de NeMo Agent Toolkit.
- Nous avons travaillé avec deux outils d’observabilité (Phoenix et W&B Weave), qui s’intègrent tous deux parfaitement à NAT et nous permettent d’enregistrer ce qui se passe à l’intérieur de notre système en production, ainsi que de capturer les résultats d’évaluation.
- Nous avons également expliqué comment configurer les évaluations dans NAT et utilisé W&B Weave pour comparer les performances de deux versions différentes de la même application. Cela a permis de raisonner facilement sur les compromis entre le coût, la latence et la qualité des réponses.
Le NeMo Agent Toolkit fournit des solutions solides et prêtes pour la production pour l’observabilité et les évaluations – éléments fondamentaux de toute application LLM sérieuse. Cependant, ce qui m’a le plus marqué a été W&B Weave, dont les visualisations d’évaluation rendent la comparaison des modèles et des compromis remarquablement simple.
Merci d’avoir lu. J’espère que cet article a été instructif. Rappelez-vous le conseil d’Einstein : « L’important est de ne pas cesser de remettre en question. La curiosité a sa propre raison d’exister. » Puisse votre curiosité vous conduire à votre prochaine grande découverte.
Référence
Cet article s’inspire du « Boîte à outils NeMo Agent de Nvidia : Rendre les agents fiables » cours court de DeepLearning.AI.


