Le bonus 2 du « Calendrier de l’Avent » d’apprentissage automatique : variantes de descente de dégradé dans Excel
utiliser descente de pente pour trouver les valeurs optimales de leurs poids. La régression linéaire, la régression logistique, les réseaux de neurones et les grands modèles de langage reposent tous sur ce principe. Dans les articles précédents, nous avons utilisé une simple descente de gradient car elle est plus facile à montrer et à comprendre.
Le même principe apparaît également à grande échelle dans les grands modèles de langage modernes, où la formation nécessite d’ajuster des millions ou des milliards de paramètres.
Cependant, les véritables formations utilisent rarement la version de base. Il est souvent trop lent ou trop instable. Les systèmes modernes utilisent des variantes de descente de gradient qui améliorent la vitesse, la stabilité ou la convergence.
Dans cet article bonus, nous nous concentrons sur ces variantes. Nous examinons pourquoi ils existent, quel problème ils résolvent et comment ils modifient la règle de mise à jour. Nous n’utilisons pas d’ensemble de données ici. Nous utilisons une variable et une fonction, uniquement pour rendre le comportement visible. Le but est de montrer le mouvement, pas de former un modèle.
1. Descente de gradient et mécanisme de mise à jour
1.1 Configuration du problème
Pour rendre ces idées visibles, nous n’utiliserons pas d’ensemble de données ici, car les ensembles de données introduisent du bruit et rendent plus difficile l’observation directe du comportement. Au lieu de cela, nous utiliserons une seule fonction :
f(x) = (x – 2)²
On commence à x = 4, et le gradient est :
dégradé = 2*(x – 2)
Cette configuration simple supprime les distractions. L’objectif n’est pas d’entraîner un modèle, mais de comprendre comment les différentes règles d’optimisation modifient le mouvement vers le minimum.
1.2 La structure derrière chaque mise à jour
Chaque méthode d’optimisation qui suit dans cet article est construite sur la même boucle, même lorsque la logique interne devient plus sophistiquée.
- Tout d’abord, nous lisons la valeur actuelle de x.
- Ensuite, nous calculons le gradient avec l’expression 2*(x – 2).
- Enfin, nous mettons à jour x selon la règle spécifique définie par la variante choisie.
La destination reste la même et le dégradé pointe toujours dans la bonne direction, mais la façon dont nous nous déplaçons dans cette direction change d’une méthode à l’autre. Ce changement de mouvement est l’essence de chaque variante.
1.3 Descente de pente de base comme ligne de base
La descente de gradient de base applique une mise à jour directe basée sur le gradient actuel et un taux d’apprentissage fixe :
x = x – lr * 2*(x – 2)
Il s’agit de la forme d’apprentissage la plus intuitive car la règle de mise à jour est facile à comprendre et à mettre en œuvre. La méthode évolue régulièrement vers le minimum, mais elle le fait souvent lentement, et elle peut avoir des difficultés lorsque le rythme d’apprentissage n’est pas choisi avec soin. Il représente la base sur laquelle reposent toutes les autres variantes.

2. Décroissance du taux d’apprentissage
Learning Rate Decay ne modifie pas la règle de mise à jour elle-même. Il modifie la taille du taux d’apprentissage au fil des itérations afin que l’optimisation devienne plus stable près du minimum. Les grands pas sont utiles lorsque x est loin de la cible, mais les pas plus petits sont plus sûrs lorsque x se rapproche du minimum. La décroissance réduit le risque de dépassement et produit un atterrissage plus en douceur.
Il n’existe pas une seule formule de désintégration. Plusieurs horaires existent en pratique :
- décroissance exponentielle
- désintégration inverse (celle indiquée dans la feuille de calcul)
- décroissance par étapes
- décroissance linéaire
- cosinus ou horaires cycliques
Tous suivent la même idée : le taux d’apprentissage diminue avec le temps, mais le schéma dépend du calendrier choisi.
Dans l’exemple de la feuille de calcul, la formule de désintégration est la forme inverse :
lr_t = lr / (1 + décroissance * itération)
Avec la règle de mise à jour :
x = x – lr_t * 2*(x – 2)
Ce programme commence avec le taux d’apprentissage complet à la première itération, puis le réduit progressivement. Au début de l’optimisation, la taille du pas est suffisamment grande pour avancer rapidement. À mesure que x s’approche du minimum, le taux d’apprentissage diminue, stabilisant la mise à jour et évitant les oscillations.
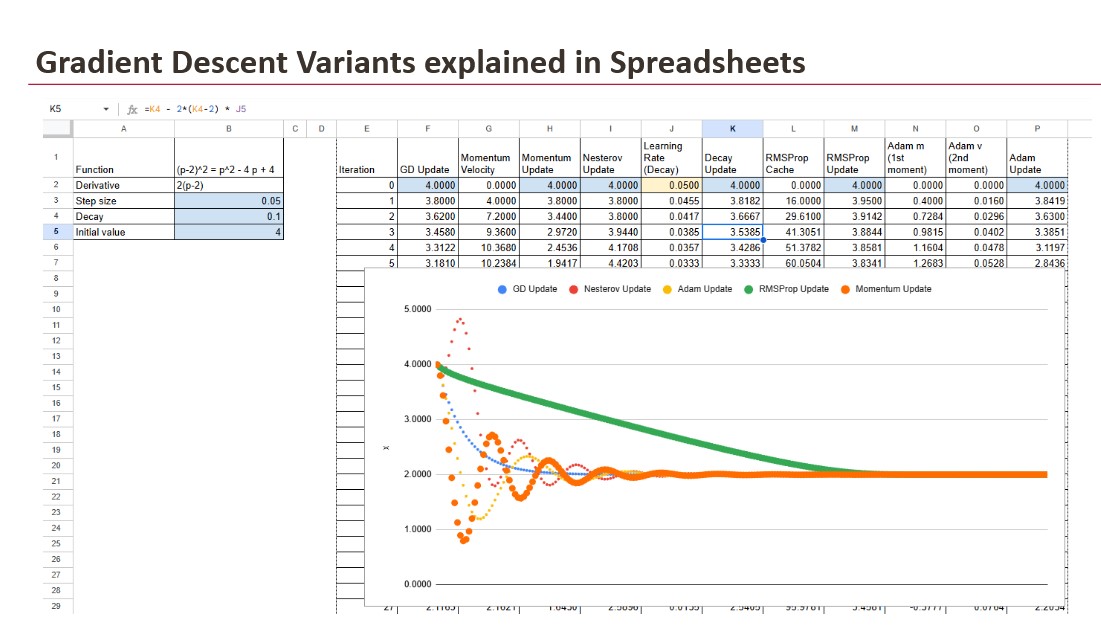
Sur le graphique, les deux courbes commencent à x = 4. La version à taux d’apprentissage fixe se déplace plus rapidement au début mais s’approche du minimum avec moins de stabilité. La version de désintégration se déplace plus lentement mais reste contrôlée. Cela confirme que la dégradation ne change pas la direction de la mise à jour. Cela modifie uniquement la taille du pas, et ce changement affecte le comportement.

3. Méthodes dynamiques
La descente de gradient se déplace dans la bonne direction mais peut être lente sur les régions plates. Les méthodes Momentum résolvent ce problème en ajoutant de l’inertie à la mise à jour.
Ils accumulent une direction au fil du temps, ce qui crée des progrès plus rapides lorsque la pente reste constante. Cette famille comprend le Momentum standard, qui augmente la vitesse, et le Nesterov Momentum, qui anticipe la prochaine position pour réduire les dépassements.
3.1 Moment standard
L’élan standard introduit l’idée d’inertie dans le processus d’apprentissage. Au lieu de réagir uniquement au gradient actuel, la mise à jour garde une mémoire des gradients précédents sous la forme d’une variable de vitesse :
vitesse = 0,9vitesse + 2(x-2)
x = x – lr * vitesse
Cette approche accélère l’apprentissage lorsque le gradient reste cohérent pendant plusieurs itérations, ce qui est particulièrement utile dans les régions plates ou peu profondes.
Cependant, la même inertie qui génère la vitesse peut également conduire à un dépassement du minimum, ce qui crée des oscillations autour de la cible.

3.2 La dynamique de Nesterov
Nesterov Momentum est un raffinement de la méthode précédente. Au lieu de mettre à jour la vitesse à la position actuelle uniquement, la méthode estime d’abord où se trouvera la position suivante, puis évalue le gradient à cet emplacement anticipé :
vitesse = 0,9vitesse + 2((x – 0,9*vitesse) – 2)
x = x – lr * vitesse
Ce comportement d’anticipation réduit l’effet de dépassement qui peut apparaître dans Momentum normal, ce qui conduit à une approche plus douce du minimum et à moins d’oscillations. Il conserve le bénéfice de la vitesse tout en introduisant un sens de l’orientation plus prudent.

4. Méthodes de gradient adaptatif
Les méthodes de gradient adaptatif ajustent la mise à jour en fonction des informations recueillies pendant l’entraînement. Au lieu d’utiliser un taux d’apprentissage fixe ou de s’appuyer uniquement sur le gradient actuel, ces méthodes s’adaptent à l’échelle et au comportement des gradients récents.
L’objectif est de réduire la taille des pas lorsque les pentes deviennent instables et de permettre une progression normale lorsque la surface est plus prévisible. Cette approche est utile dans les réseaux profonds ou les surfaces de perte irrégulières, où le gradient peut changer d’ampleur d’une étape à l’autre.
4.1 RMSProp (propagation quadratique moyenne)
RMSProp signifie Root Mean Square Propagation. Il conserve une moyenne mobile des dégradés carrés dans un cache, et cette valeur influence l’agressivité avec laquelle la mise à jour est appliquée :
cache = 0,9cache + (2(x – 2))²
x = x – lr / sqrt(cache) * 2*(x – 2)
Le cache devient plus grand lorsque les dégradés sont instables, ce qui réduit la taille de la mise à jour. Lorsque les dégradés sont faibles, le cache croît plus lentement et la mise à jour reste proche de l’étape normale. Cela rend RMSProp efficace dans les situations où l’échelle de gradient n’est pas cohérente, ce qui est courant dans les modèles d’apprentissage profond.

4.2 Adam (estimation du moment adaptatif)
Adam signifie Adaptive Moment Estimation. Il combine l’idée de Momentum avec le comportement adaptatif de RMSProp. Il conserve une moyenne mobile des dégradés pour capturer la direction, et une moyenne mobile des dégradés au carré pour capturer l’échelle :
m = 0,9m + 0,1(2(x – 2)) v = 0,999v + 0,001(2(x – 2))²
x = x – lr * m / carré(v)
La variable m se comporte comme la vitesse en élan, et la variable v se comporte comme le cache dans RMSProp. Adam met à jour les deux valeurs à chaque itération, ce qui lui permet d’accélérer lorsque la progression est claire et de réduire le pas lorsque le dégradé devient instable. Cet équilibre entre vitesse et contrôle est ce qui fait d’Adam un choix standard dans la formation aux réseaux neuronaux.

4.3 Autres méthodes adaptatives
Adam et RMSProp sont les méthodes adaptatives les plus courantes, mais elles ne sont pas les seules. Plusieurs méthodes apparentées existent, chacune avec un objectif précis :
- AdaGrad ajuste le taux d’apprentissage en fonction de l’historique complet des gradients carrés, mais le taux peut diminuer trop rapidement.
- AdaDelta modifie AdaGrad en limitant l’impact du dégradé historique sur la mise à jour.
- Adamax utilise la norme infinie et peut être plus stable pour de très grands gradients.
- Nadam ajoute à Adam un comportement d’anticipation de style Nesterov.
- RAdam tente de stabiliser Adam au début de la formation.
- AdamW sépare la perte de poids de la mise à jour du gradient et est recommandé dans de nombreux frameworks modernes.
Ces méthodes suivent la même idée que RMSProp et Adam : adapter la mise à jour au comportement des dégradés. Ils représentent des améliorations ou des extensions des concepts introduits ci-dessus et font partie de la même famille plus large d’algorithmes d’optimisation adaptative.
Conclusion
Toutes les méthodes de cet article visent le même objectif : déplacer x vers le minimum. La différence est le chemin. Gradient Descent fournit la règle de base. L’élan ajoute de la vitesse et Nesterov améliore le contrôle. RMSProp adapte le pas à l’échelle de gradient. Adam combine ces idées et Learning Rate Decay ajuste la taille du pas au fil du temps.

Chaque méthode résout une limitation spécifique de la précédente. Aucun d’eux ne remplace la ligne de base. Ils le prolongent. En pratique, l’optimisation n’est pas une règle unique, mais un ensemble de mécanismes qui fonctionnent ensemble.
L’objectif reste le même. Le mouvement devient plus efficace.