
Briser la barrière matérielle : logiciel FP8 pour les GPU plus anciens
À mesure que les modèles d’apprentissage profond s’agrandissent et que les ensembles de données s’étendent, les praticiens sont confrontés à un goulot d’étranglement de plus en plus courant : la bande passante mémoire du GPU. Alors que le matériel de pointe offre la précision FP8 pour accélérer la formation et l’inférence, la plupart des data scientists et des ingénieurs ML travaillent avec des GPU plus anciens qui ne disposent pas de cette capacité.
Cette lacune dans l’écosystème est ce qui m’a motivé à construire Plumeune bibliothèque open source qui utilise une approche logicielle pour offrir des améliorations de performances de type FP8 sur du matériel largement disponible. J’ai créé cet outil pour rendre l’apprentissage profond efficace plus accessible à la communauté ML au sens large, et j’apprécie les contributions.
Notation et abréviations
- FFX : Nombre à virgule flottante X bits
- UX : Entier non signé X bits
- GPU : Unité de traitement graphique
- SRAM : RAM statique (cache GPU sur puce)
- HBM : Mémoire à large bande passante (GPU VRAM)
- GEMV : Multiplication générale matrice-vecteur
Motivation
Le traitement FP8 s’est avéré efficace dans la communauté Deep Learning [1]; cependant, seules des architectures matérielles récentes spécifiques (Ada et Blackwell) le prennent en charge, ce qui limite ses avantages pour les praticiens et les chercheurs. J’ai moi-même un ‘GPU pour ordinateur portable Nvidia RTX 3050 6 Go`, qui ne prend malheureusement pas en charge les opérations FP8 au niveau matériel.
Inspiré par des solutions logicielles telles que le rendu accéléré par logiciel sur les ordinateurs qui ne prennent pas en charge l’accélération matérielle native pour les jeux, l’article propose une solution intéressante qui peut utiliser la puissance des types de données FP8.
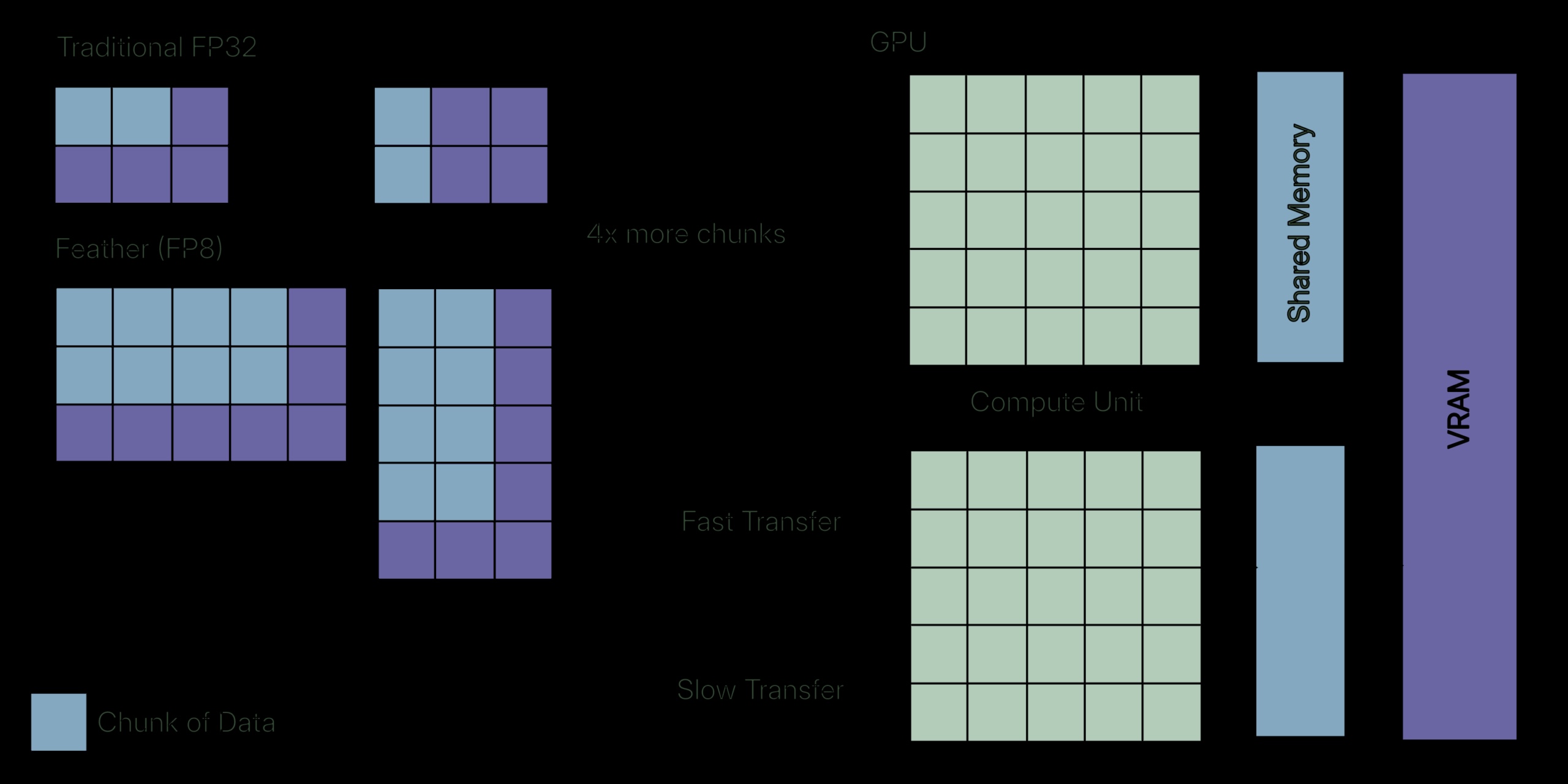
Conditionnement des FP8 et FP16 dans des conteneurs FP32
Inspiré des opérations au niveau du bit et des techniques de regroupement, l’article présente un algorithme qui regroupe deux FP16 ou quatre FP8 dans un seul FP32. Cela permet d’emballer deux ou quatre fois plus de mémoire, bénéficiant d’une empreinte mémoire inférieure, tout en sacrifiant seulement une petite quantité de précision.
On pourrait dire que nous effectuons des calculs redondants.Pack -> Charger -> Décompresser -> Calculer.» Cependant, considérons les opérations de Deep Learning ; La plupart du temps, ces opérations sont liées à la mémoire plutôt qu’au calcul. Il s’agit du même goulot d’étranglement que les algorithmes comme FlashAttention ; cependant, FlashAttention utilise la mosaïque pour conserver les données dans une SRAM rapide, tandis que Feather compresse les données pour réduire le trafic mémoire.
Hiérarchie de la mémoire GPU

Jetez un œil à ce schéma. La SRAM est la région de mémoire GPU accessible la plus rapidement et possède la bande passante la plus élevée (à l’exclusion du registre lui-même), mais elle est limitée à seulement 20 Mo. HBM peut être considéré comme la VRAM du GPU lui-même, qui a environ 1/7ème la bande passante de la SRAM.
Les cœurs du GPU sont suffisamment rapides pour effectuer le calcul instantanément, mais ils passent la plupart de leur temps inactifs, à attendre que les données aient fini de se charger et de les réécrire. C’est ce que j’entends par lié à la mémoire : le goulot d’étranglement ici n’est pas le calcul, mais le transfert de données entre la hiérarchie de la mémoire dans le GPU.
Types de précision et bande passante inférieurs
La plupart du temps, les valeurs lors du calcul sont limitées à des plages autour de zéro en raison de la normalisation. Les ingénieurs ont développé des types de précision inférieurs tels que FP8 et FP16, qui permettent une bande passante plus élevée. On pourrait se demander dans quelle mesure la diminution de la précision permet d’obtenir une bande passante plus élevée. Si nous y regardons de plus près, nous chargeons effectivement deux valeurs à la place d’une pour le type FP16 et quatre valeurs à la place d’une pour le type FP8. Nous échangeons la précision contre une bande passante plus élevée pour gérer les opérations liées à la mémoire.
Prise en charge du niveau matériel
Tout comme les instructions AVX-512, qui ne sont prises en charge que sur un nombre limité de plates-formes matérielles, les instructions et registres FP8 et FP16 sont également limités par le matériel et ne sont disponibles que sur les plus récentes. Si vous utilisez un GPU de la série RTX-30 ou RTX-20 de Nvidia, vous ne pourrez pas profiter de ce type FP8 de moindre précision. C’est exactement le problème que Plume tente de résoudre.
Méthode d’emballage
En utilisant des opérateurs au niveau du bit, on peut facilement intégrer le type FP16 dans un FP32. L’algorithme est décrit ci-dessous.
Emballage FP16
- Transformez l’entrée FP32 en un FP16 ; cette étape peut être effectuée facilement à l’aide de numpy commetype fonction.
- Lancez-les en U16 puis en U32 ; cela définit les 16 bits supérieurs sur 0 et les 16 bits inférieurs sur le FP16 réel.
- Décalez l’un d’eux de 16 en utilisant le bitwise LSHIFT opérateur, et combinez les deux à l’aide de l’opérateur bitwise OU opérateur.
Déballage du FP16
- Extrayez les 16 bits inférieurs en utilisant le bitwise ET opérateur et masque 0xFFFF.
- Extrayez les 16 bits supérieurs à l’aide du MAJ R opération par 16 puis effectuez une opération au niveau du bit ET opération avec le masque 0xFFFF.
- Reconvertissez les deux valeurs U16 en FP16 et en FP32 si nécessaire.
Emballage FP8
FP8 a deux formats largement utilisés – E5M2 et E4M3. On ne peut pas utiliser le même algorithme que celui utilisé pour regrouper deux FP16 dans FP32 car le CPU ne prend pas en charge les types FP8 de manière native, mais le fait pour FP16 (demi-précision) ; c’est la raison pour laquelle np.float8 n’existe pas.

La conversion d’un FP16 en FP8-E5M2 est simple, comme le montre la figure, car les deux ont le même nombre de bits d’exposant et ne diffèrent que par leur fraction.
Emballage FP8-E5M2
- Transformez l’entrée FP32 en un FP16 ; cette étape peut être effectuée facilement à l’aide de numpy commetype fonction, ou obtenez l’entrée elle-même en tant que FP16.
- Casté en U16, LSHIFT à 8 heures, alors MAJ R par 8 pour isoler les 8 bits supérieurs
- Faites cela pour les quatre FP32 ou FP16.
- Maintenant, en utilisant le LSHIFT opérateur, décalez-les de 0, 8, 16 et 24 unités et combinez-les à l’aide du bitwise OU opérateur.
Encore une fois, le déballage devrait être simple ; c’est exactement le contraire de l’emballage.
L’emballage d’un FP8-E4M3 n’est pas aussi simple et direct que l’emballage d’un FP16 ou d’un FP8-E5M2, en raison de la non-concordance des bits des exposants.

Au lieu de l’implémenter à partir de zéro, la bibliothèque utilise le ml_dtypes bibliothèque, qui fait déjà le calcul du casting.
Le ml_dtypes La bibliothèque prend en charge les normes FP8 couramment utilisées, telles que la diffusion E5M2 et E4M3, pour les tableaux NumPy. En utilisant la même fonction astype, nous pouvons effectuer un casting comme nous l’avons fait pour les types FP16. L’algorithme est exactement identique à la façon dont nous emballons le FP16, je le saute donc ici.
Noyaux GPU Triton
Après avoir compressé, nous avons besoin d’un algorithme (noyau) pour utiliser ce type de données compressé et effectuer le calcul. Passer le type de données compressé à un noyau implémenté pour FP32 ou FP64 entraînera un calcul non défini car nous avons déjà corrompu le FP32 ou le FP64 transmis. L’écriture d’un noyau qui prend le type de données compressé en entrée dans CUDA n’est pas une tâche simple et est sujette aux erreurs. C’est exactement là où Triton brille; il s’agit d’une bibliothèque de langage spécifique au domaine qui exploite une représentation intermédiaire personnalisée pour les noyaux GPU. En termes simples, cela permet d’écrire des noyaux GPU en Python lui-même sans avoir besoin d’écrire des noyaux CUDA en C.
Les noyaux Triton font exactement ce qui a été mentionné précédemment ; l’algorithme est le suivant :
- Charger le tableau compressé en mémoire
- Décompressez la mémoire et transférez-la vers FP32 pour les tâches d’accumulation
- Effectuer le calcul
Le lecteur doit noter que lors de l’exécution du calcul, la conversion ascendante est utilisée pour éviter les débordements. Par conséquent, d’un point de vue informatique, il n’y a aucun avantage. Cependant, du point de vue de la bande passante, nous chargeons la mémoire deux ou quatre fois sans compromettre la bande passante.
Implémentation du noyau Triton (pseudocode)
@triton.jit
def gemv_fp8_kernel(packed_matrix_ptr, packed_vector_ptr, out_ptr):
# Get current row to process
row_id = get_program_id()
# Initialize accumulator for dot product
accumulator = 0
# Iterate over row in blocks
for each block in row:
# Load packed FP32 values (each contains 4 FP8s)
packed_matrix = load(packed_matrix_ptr)
packed_vector = load(packed_vector_ptr)
# Unpack the FP32 into 4 FP8 values
m_a, m_b, m_c, m_d = unpack_fp8(packed_matrix)
v_a, v_b, v_c, v_d = unpack_fp8(packed_vector)
# Upcast to FP32 and compute partial dot products
accumulator += (m_a * v_a) + (m_b * v_b) + (m_c * v_c) + (m_d * v_d)
# Store final result
store(out_ptr, accumulator)Résultats
Matériel: NVIDIA GeForce RTX 3050 6 Go de mémoire vidéo
Version CUDA : 13,0
Version Python: 3.13.9
Référence GEMV (M = 16384, N = 16384) (matrice MxN)
| Mise en œuvre | Temps (microsecondes) | Accélération |
| Torche Pytorchique (FP32) | 5 635 | (Référence) |
| Plume (FP8-E4M3) | 2 703 | 2,13x |
| Plume (FP8-E5M2) | 1 679 | 3,3x |
L’augmentation théorique des performances pouvant être obtenue est de 4x ; 3,3x est très bon en comparaison, la surcharge restante provenant principalement des opérations de pack/déballage et des coûts de lancement du noyau.
Le E5M2 est plus rapide que le E4M3 en raison d’un déballage plus facile, mais le E4M3 offre une meilleure précision. Cependant, il est nettement plus complexe à décompresser (Feather utilise un noyau GPU distinct pour décompresser le format E4M3).
Référence d’attention flash (Longueur de la séquence = 8 192, dimension d’intégration = 512)
| Mise en œuvre | Temps (microsecondes) | Accélération |
| Torche Pytorchique (FP32) | 33 290 | (Référence) |
| Plume (FP8-E5M2) | 9 887 | ~3,3x |
Exactitude et précision
Tests avec des matrices aléatoires (distributions entières dans la plage [-3, 3] et distributions normales standard) montre que E4M3 et E5M2 maintiennent les résultats numériques dans les limites des tolérances pratiques pour les opérations d’apprentissage en profondeur. Les erreurs d’accumulation restent gérables pour des tailles de charge de travail typiques ; cependant, les utilisateurs exigeant une précision numérique stricte doivent valider leur cas d’utilisation spécifique.
Quand faut-il utiliser Feather ?
Les cas d’utilisation de Feather ne sont pas limités ; on peut utiliser Feather partout où l’emballage et le déballage du FP8 présentent un avantage, comme par exemple
- Produits à vecteur matriciel de grande taille, où le chargement et le déchargement constituent les goulots d’étranglement.
- Noyaux liés à la mémoire, de type attention.
- Inférence ou réglage fin sur les séries natives RTX 30 ou 20.
- Traitement par lots, où les frais généraux d’emballage sont amortis
Quand faut-il pas prendre Feather ?
- Vous disposez de GPU RTX série 40 ou H100 (le FP8 natif est plus rapide).
- Les charges de travail sont liées au calcul plutôt qu’à la bande passante ou à la mémoire.
- Vous avez besoin d’une précision garantie.
Limites de la plume
Feather en est actuellement aux premiers stades du prototypage avec plusieurs domaines à améliorer.
- Soutien limité aux opérations ; actuellement, Plume prend en charge uniquement le produit scalaire, le sous-programme GEMV et FlashAttention.
- Validation de la précision pour les charges de travail ML complètes ; actuellement, Plume la précision est validée uniquement pour les opérations, et non pour les charges de travail de ML de bout en bout.
- L’intégration est actuellement limitée ; Plume est une implémentation autonome. L’intégration avec PyTorch et la prise en charge d’Autograd le rendraient plus prêt pour la production.
Le projet est open source ; les contributions de la communauté sont les bienvenues ! Vous pouvez essayer le code en suivant simplement les instructions sur GitHub.
Licence d’image : Toutes les images sont réalisées par l’auteur. Les sources d’adaptation sont clairement mentionnées dans les légendes respectives.


