
Le « calendrier de l’Avent » d’apprentissage automatique Jour 21 : régresseur d’arbre de décision amélioré par gradient dans Excel
article précédent, nous avons présenté le mécanisme de base du Gradient Boosting via Régression linéaire renforcée par gradient.
Cet exemple était délibérément simple. Son objectif n’était pas la performance, mais la compréhension.
L’utilisation d’un modèle linéaire nous a permis de rendre explicite chaque étape : les résidus, les mises à jour et la nature additive du modèle. Il a également fait le lien avec Descente de dégradé très clair.
Dans cet article, nous passons au contexte où le Gradient Boosting devient vraiment utile dans la pratique : Régresseurs d’arbre de décision.
Nous réutiliserons le même cadre conceptuel que précédemment, mais le comportement de l’algorithme change de manière importante. Contrairement aux modèles linéaires, les arbres de décision sont non linéaires et constants par morceaux. Lorsqu’ils sont combinés via Gradient Boosting, ils ne s’effondrent plus en un seul modèle. Au lieu de cela, chaque nouvel arbre ajoute de la structure et affine les prédictions des précédents.
Pour cette raison, nous ne récapitulerons que brièvement le mécanisme général du Gradient Boosting et nous concentrerons plutôt sur ce qui est spécifique à Arbres de décision améliorés par gradient: comment les arbres sont entraînés sur les résidus, comment l’ensemble évolue, et pourquoi cette approche est si puissante.
1. Apprentissage automatique en trois étapes
Nous utiliserons à nouveau le même cadre en trois étapes pour garder l’explication cohérente et intuitive.

1. Modèle de base
nous utiliserons des régresseurs d’arbre de décision comme modèle de base.
Un arbre de décision est non linéaire par construction. Il divise l’espace des fonctionnalités en régions et attribue une prédiction constante à chaque région.
Un point important est que lorsque les arbres sont additionnés, ils ne s’effondrent pas en un seul arbre.
Chaque nouvel arbre présente structure supplémentaire au modèle.
C’est là que le Gradient Boosting devient particulièrement puissant.
1bis. Modèle d’ensemble
Le Gradient Boosting est le mécanisme utilisé pour agrégat ces modèles de base en un seul modèle prédictif.
2. Montage du modèle
Pour plus de clarté, nous utiliserons souches de décisionc’est-à-dire des arbres avec une profondeur d’une et une seule fente.
Chaque arbre est dressé pour prédire le résidus du modèle précédent.
2 bis. Apprentissage d’ensemble
L’ensemble lui-même est construit à l’aide descente de gradient dans l’espace fonctionnel.
Ici, les objets optimisés ne sont pas des paramètres mais fonctionset ces fonctions sont des arbres de décision.
3. Réglage du modèle
Les arbres de décision ont plusieurs hyperparamètres, tels que :
- profondeur maximale
- nombre minimum d’échantillons requis pour diviser
- nombre minimum d’échantillons par feuille
Dans cet article, nous fixons la profondeur de l’arbre à un.
Au niveau de l’ensemble, deux hyperparamètres supplémentaires sont essentiels :
- le taux d’apprentissage
- le nombre d’itérations de boosting
Ces paramètres contrôlent la rapidité avec laquelle le modèle apprend et sa complexité.
2. Algorithme d’augmentation du dégradé
L’algorithme Gradient Boosting suit une structure simple et répétitive.
2.1 Présentation de l’algorithme
Voici les principales étapes de l’algorithme Gradient Boosting
- Initialisation
Commencez avec un modèle constant. Pour la régression avec perte au carré, il s’agit de la valeur moyenne de la cible. - Calcul résiduel
Calculez les résidus entre les prédictions actuelles et les valeurs observées. - Adapter un apprenant faible
Entraînez un régresseur d’arbre de décision pour prédire ces résidus. - Mise à jour du modèle
Ajoutez le nouvel arbre au modèle existant, mis à l’échelle en fonction d’un taux d’apprentissage. - Répéter
Répétez jusqu’à ce que le nombre d’étapes de boost choisi soit atteint ou que l’erreur se stabilise.
2.2 Ensemble de données
Pour illustrer le comportement des arbres dégradés boostés, nous utiliserons plusieurs types d’ensembles de données que j’ai générés :
- Données linéaires par morceauxoù la relation change par segments
- Données non linéairestels que des motifs courbes
- Cibles binairespour les tâches de classification
Pour la classification, nous commencerons par le perte au carré pour plus de simplicité. Cela permet de réutiliser les mêmes mécaniques qu’en régression. La fonction de perte pourra ultérieurement être remplacée par des alternatives mieux adaptées à la classification, comme la perte logistique ou exponentielle.
Ces différents ensembles de données permettent de mettre en évidence comment le Gradient Boosting s’adapte à diverses structures de données et fonctions de perte tout en s’appuyant sur le même algorithme sous-jacent.

2.3 Initialisation
Le processus de Gradient Boosting commence avec un modèle constant.
Pour la régression avec perte au carré, cette prédiction initiale est simplement la valeur moyenne de la variable cible.
Cette valeur moyenne représente la meilleure prédiction initiale avant qu’une structure ne soit apprise à partir des fonctionnalités.
C’est aussi une bonne occasion de rappeler : presque tous les modèles de régression peuvent être considérés comme une amélioration par rapport à la moyenne mondiale.
- k-NN recherche des observations similaires et prédit avec la valeur moyenne de leurs voisins.
- Régresseurs d’arbre de décision divisez l’ensemble de données en régions et calculez la valeur moyenne dans chaque feuille pour prédire une nouvelle observation qui tombe dans cette feuille.
- Modèles basés sur le poids ajustez les pondérations des caractéristiques pour équilibrer ou mettre à jour la moyenne globale, pour une nouvelle observation donnée.
Ici, pour augmenter le dégradé, nous commençons également par la valeur moyenne. Et puis nous verrons comment cela sera progressivement corrigé.

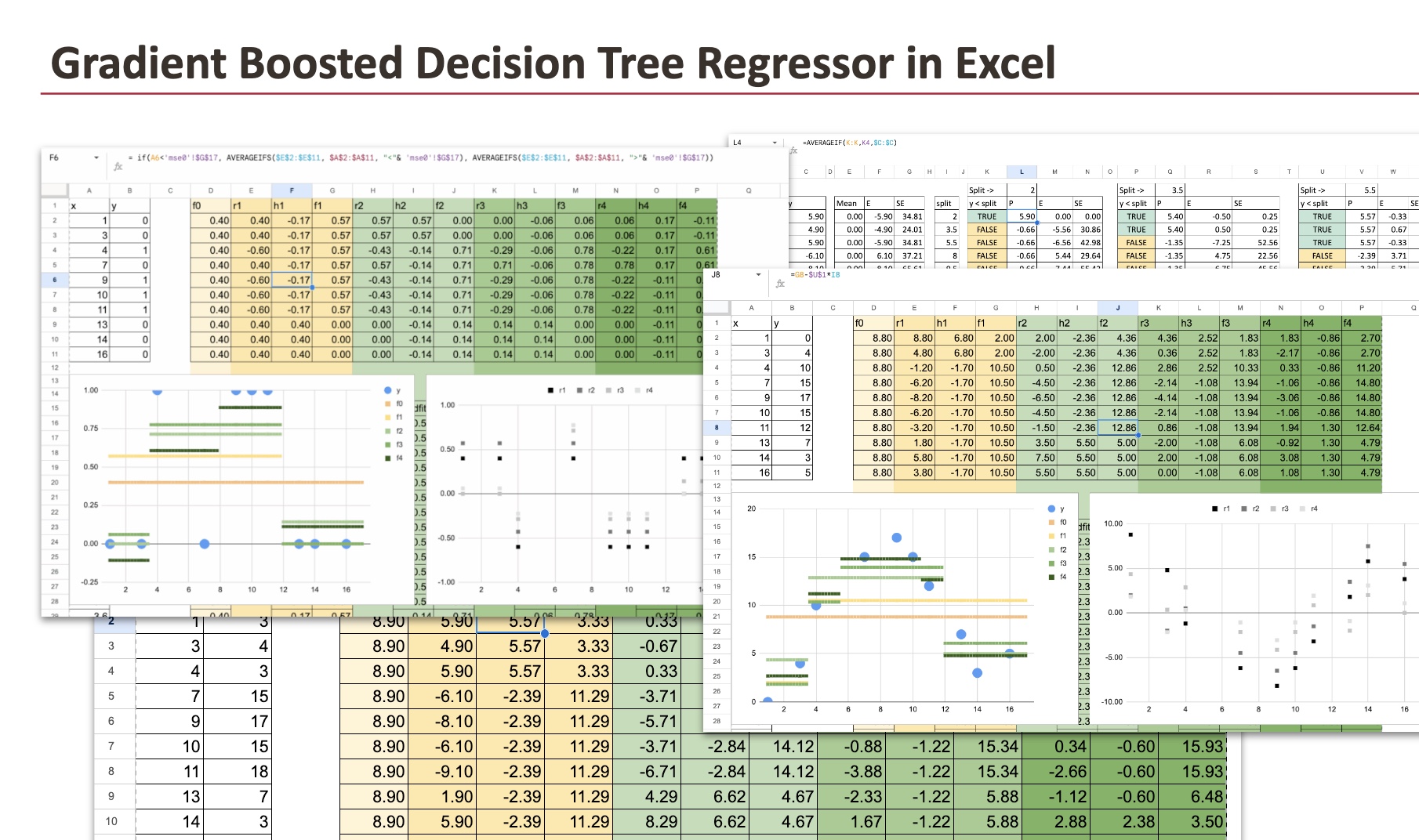
2.4 Premier arbre
Le premier arbre de décision est ensuite formé sur le résidus de ce modèle initial.
Après l’initialisation, les résidus ne sont que les différences entre les valeurs observées et la moyenne.

Pour construire ce premier arbre, nous utilisons exactement la même procédure que dans l’article sur Régresseurs d’arbre de décision.
La seule différence est la cible : au lieu de prédire les valeurs d’origine, l’arbre prédit les valeurs résiduelles.
Ce premier arbre fournit la correction initiale du modèle constant et définit la direction du processus de boosting.

2.5 Mise à jour du modèle
Une fois le premier arbre formé sur les résidus, nous pouvons calculer la première prédiction améliorée.
Le modèle mis à jour est obtenu en combinant la prédiction initiale et la correction du premier arbre :
f1(x) = f0 + taux_apprentissage * h1(x)
où:
- f0 est la prédiction initiale, égale à la valeur moyenne de la cible
- h1(x) est la prédiction du premier arbre entraîné sur les résidus
- learning_rate contrôle la quantité de cette correction appliquée
Cette étape de mise à jour est le mécanisme de base de Gradient Boosting.
Chaque arbre ajuste légèrement les prédictions actuelles au lieu de les remplacer, permettant au modèle de s’améliorer progressivement et de rester stable.
2.6 Répéter le processus
Une fois la première mise à jour appliquée, la même procédure est répétée.
À chaque itération, de nouveaux résidus sont calculés à l’aide des prédictions actuelles, et un nouvel arbre de décision est formé pour prédire ces résidus. Cet arbre est ensuite ajouté au modèle en utilisant le taux d’apprentissage.
Pour rendre ce processus plus facile à suivre dans Excel, les formules peuvent être écrites de manière entièrement automatisée. Une fois cela fait, les formules du deuxième arbre et de tous les arbres suivants peuvent simplement être copiées vers la droite.

Au fur et à mesure des itérations, toutes les prédictions des modèles résiduels sont regroupées. Cela rend la structure du modèle final très claire.
A la fin, la prédiction peut s’écrire sous une forme compacte :
f(x) = f0 + eta * (h1(x) + h2(x) + h3(x) + …)
Cette représentation met en évidence une idée importante : le modèle final est simplement la prédiction initiale plus une somme pondérée de prédictions résiduelles.
Cela ouvre également la porte à d’éventuelles extensions. Par exemple, le taux d’apprentissage ne doit pas nécessairement être constant. Il peut diminuer avec le temps, suite à une décroissance au cours du processus itératif.
C’est la même idée pour la décroissance en descente de gradient ou descente de gradient stochastique.

3. Comprendre le modèle final
3.1 Comment le modèle évolue au fil des itérations
Nous commençons par un ensemble de données par morceaux. Dans la visualisation ci-dessous, nous pouvons voir tous les modèles intermédiaires produits lors du processus de Gradient Boosting.
Premièrement, nous voyons le prédiction constante initialeégale à la valeur moyenne de la cible.
Puis vient f1obtenu après avoir ajouté le premier arbre avec une seule division.
Suivant, f2après avoir ajouté un deuxième arbre, et ainsi de suite.
Chaque nouvel arbre introduit une correction locale. Au fur et à mesure que d’autres arbres sont ajoutés, le modèle s’adapte progressivement à la structure des données.

Le même comportement apparaît avec un ensemble de données courbes. Même si chaque arbre individuel est constant par morceaux, leur combinaison additive donne lieu à une courbe lisse qui suit le modèle sous-jacent.

Lorsqu’il est appliqué à un cible binairel’algorithme fonctionne toujours, mais certaines prédictions peuvent devenir négatives ou supérieures à un. Ceci est attendu lors de l’utilisation de la perte d’erreur quadratique, qui traite le problème comme une régression et ne contraint pas la plage de sortie.
Si des résultats de type probabilité sont requis, une fonction de perte orientée classification, telle que la perte logistique, doit être utilisée à la place.

En conclusion, le Gradient Boosting peut être appliqué à différents types d’ensembles de donnéesy compris les cas par morceaux, non linéaires et binaires. Quel que soit l’ensemble de données, le modèle final reste constante par morceaux par constructionpuisqu’il est construit comme une somme d’arbres de décision.
Cependant, l’accumulation de nombreuses petites corrections permet à la prédiction globale de se rapprocher étroitement de modèles complexes.
3.2 Comparaison avec un seul arbre de décision
Lorsqu’on montre ces tracés, une question naturelle se pose souvent :
Le Gradient Boosting ne finit-il pas par créer un arbre, tout comme un régresseur d’arbre de décision ?
Cette impression est compréhensible, surtout lorsque l’on travaille avec un petit ensemble de données. Visuellement, la prédiction finale peut sembler similaire, ce qui rend les deux approches plus difficiles à distinguer au premier coup d’œil.
Cependant, la différence apparaît clairement quand on regarde comment les répartitions sont calculées.
Un régresseur d’arbre de décision unique est construit via un séquence de divisions. À chaque division, les données disponibles sont divisées en sous-ensembles plus petits. Au fur et à mesure que l’arbre grandit, chaque nouvelle décision repose sur de moins en moins d’observations, ce qui peut rendre le modèle sensible au bruit.
Une fois la division effectuée, les points de données appartenant à différentes régions ne sont plus liés. Chaque région est traitée indépendamment et les premières décisions ne peuvent être révisées.
Les arbres dégradés fonctionnent d’une manière complètement différente.
Chaque arbre dans le processus de boosting est formé à l’aide du ensemble de données complet. Aucune observation n’est jamais retirée du processus d’apprentissage. À chaque itération, tous les points de données contribuent via leurs résidus.
Cela change fondamentalement le comportement du modèle.
Un seul arbre fait des décisions difficiles et irréversibles. Le Gradient Boosting, en revanche, permet aux arbres ultérieurs de corriger les erreurs réalisés par les précédents.
Au lieu de s’engager sur une partition rigide de l’espace des fonctionnalités, le modèle affine progressivement ses prédictions grâce à une séquence de petits ajustements.
Cette capacité à réviser et à améliorer les décisions antérieures est l’une des principales raisons pour lesquelles Les arbres boostés par gradient sont à la fois robustes et puissants dans la pratique.
3.3 Comparaison générale avec d’autres modèles
Comparé à un arbre de décision uniqueLes arbres boostés par gradient produisent des prédictions plus fluides, réduisent le surapprentissage et améliorent la généralisation.
Comparé à modèles linéairesils capturent naturellement des modèles non linéaires, modélisent automatiquement les interactions des fonctionnalités et ne nécessitent aucune ingénierie manuelle des fonctionnalités.
Comparé à modèles non linéaires basés sur le poidscomme les méthodes de noyau ou les réseaux de neurones, les arbres gradient boostés offrent un ensemble différent de compromis. Ils s’appuient sur des éléments de base simples et interprétables, sont moins sensibles à la mise à l’échelle des fonctionnalités et nécessitent moins d’hypothèses sur la structure des données. Dans de nombreuses situations pratiques, ils s’entraînent également plus rapidement et nécessitent moins de réglages.
Ces propriétés combinées expliquent pourquoi Régresseurs d’arbre de décision améliorés par gradient fonctionnent si bien dans un large éventail d’applications du monde réel.
Conclusion
Dans cet article, nous avons montré comment Gradient Boosting crée des modèles puissants en combinant des arbres de décision simples formés sur les résidus. Partant d’une prédiction constante, le modèle est affiné étape par étape grâce à de petites corrections locales.
Nous avons vu que cette approche s’adapte naturellement à différents types de jeux de données et que le choix de la fonction de perte est essentiel, notamment pour les tâches de classification.
En combinant la flexibilité des arbres avec la stabilité du boosting, les arbres de décision gradient boostés atteignent de solides performances dans la pratique tout en restant conceptuellement simples et interprétables.


