
Le « Calendrier de l’Avent » d’apprentissage automatique Jour 13 : LASSO et Ridge Regression dans Excel
Un jour, un data scientist a déclaré que Ridge Regression était un modèle compliqué. Parce qu’il a vu que la formule de formation est plus compliquée.
Et bien c’est exactement l’objectif de mon « Calendrier de l’Avent » de Machine Learning, clarifier ce genre de complexité.
Nous parlerons donc de versions pénalisées de la régression linéaire.
- Dans un premier temps, nous verrons pourquoi la régularisation ou la pénalisation est nécessaire, et nous verrons comment le modèle est modifié
- Nous explorerons ensuite différents types de régularisation et leurs effets.
- Nous entraînerons également le modèle avec régularisation et testerons différents hyperparamètres.
- Nous poserons également une autre question sur la manière de pondérer les poids dans le terme de pénalisation. (confus ? Vous verrez)
La régression linéaire et ses « conditions »
Lorsqu’on parle de régression linéaire, les gens mentionnent souvent que certaines conditions doivent être remplies.
Vous avez peut-être entendu des déclarations telles que :
- les résidus doivent être gaussiens (c’est parfois confondu avec la cible étant gaussienne, ce qui est faux)
- les variables explicatives ne doivent pas être colinéaires
Dans les statistiques classiques, ces conditions sont requises pour l’inférence. Dans l’apprentissage automatique, l’accent est mis sur la prédiction, ces hypothèses sont donc moins centrales, mais les problèmes sous-jacents demeurent.
Ici, nous verrons un exemple de deux entités colinéaires et rendons-les complètement égales.
Et nous avons la relation : y = x1 + x2, et x1 = x2
Je sais que s’ils sont complètement égaux, on peut simplement faire : y=2*x1. Mais l’idée est de dire qu’ils peuvent être très similaires, et que nous pouvons toujours construire un modèle en les utilisant, n’est-ce pas ?
Alors quel est le problème ?
Lorsque les entités sont parfaitement colinéaires, la solution n’est pas unique. Voici un exemple dans la capture d’écran ci-dessous.
y = 10 000*x1 – 9998*x2

Et on peut remarquer que la norme des coefficients est énorme.
L’idée est donc de limiter la norme des coefficients.
Et après application de la régularisation, le modèle conceptuel est le même !
C’est vrai. Les paramètres de la régression linéaire sont modifiés. Mais le modèle est le même.
Différentes versions de régularisation
L’idée est donc de combiner le MSE et la norme des coefficients.
Au lieu de simplement minimiser le MSE, nous essayons de minimiser la somme des deux termes.
Quelle norme ? On peut se contenter des normes L1, L2, voire les combiner.
Il existe trois manières classiques de procéder, ainsi que les noms de modèles correspondants.
Régression de crête (pénalité L2)
La régression Ridge ajoute une pénalité sur le valeurs au carré des coefficients.
Intuitivement :
- les gros coefficients sont fortement pénalisés (à cause du carré)
- les coefficients sont poussés vers zéro
- mais ils ne deviennent jamais exactement nuls
Effet:
- toutes les fonctionnalités restent dans le modèle
- les coefficients sont plus lisses et plus stables
- très efficace contre la colinéarité
Crête rétrécitmais ne sélectionne pas.

Régression au lasso (pénalité L1)
Lasso utilise une pénalité différente : le valeur absolue des coefficients.
Ce petit changement a une grande conséquence.
Avec le lasso :
- certains coefficients peuvent devenir exactement zéro
- le modèle ignore automatiquement certaines fonctionnalités
C’est pourquoi LASSO est appelé ainsi, car il signifie Opérateur de retrait le moins absolu et de sélection.
- Opérateur: il fait référence à l’opérateur de régularisation ajouté à la fonction de perte
- Moins: il est dérivé d’un cadre de régression des moindres carrés
- Absolu: il utilise la valeur absolue des coefficients (norme L1)
- Rétrécissement: il réduit les coefficients vers zéro
- Sélection: il peut définir certains coefficients exactement à zéro, en effectuant une sélection de fonctionnalités
Nuance importante :
- on peut dire que le modèle a toujours le même nombre de coefficients
- mais certains d’entre eux sont forcés à zéro pendant l’entraînement
La forme du modèle reste inchangée, mais Lasso supprime efficacement les fonctionnalités en ramenant les coefficients à zéro.

3. Filet élastique (L1 + L2)
Le filet élastique est un combinaison de Ridge et Lasso.
Il utilise :
- un malus de L1 (comme Lasso)
- et une pénalité L2 (comme Ridge)
Pourquoi les combiner ?
Parce que:
- Le lasso peut être instable lorsque les caractéristiques sont fortement corrélées
- Ridge gère bien la colinéarité mais ne sélectionne pas les fonctionnalités
Elastic Net offre un équilibre entre :
- stabilité
- rétrécissement
- rareté
Il s’agit souvent du choix le plus pratique dans les ensembles de données réels.
Ce qui change vraiment : modèle, formation, réglage
Regardons cela du point de vue du Machine Learning.
Le modèle ne change pas vraiment
Pour le modèlepour toutes les versions régularisées, on écrit toujours :
y = hache + b.
- Même nombre de coefficients
- Même formule de prédiction
- Mais les coefficients seront différents.
D’un certain point de vue, Ridge, Lasso et Elastic Net sont pas de modèles différents.
Le entraînement le principe est également le même
Nous continuons :
- définir une fonction de perte
- minimiser
- calculer les dégradés
- mettre à jour les coefficients
La seule différence est :
- la fonction de perte inclut désormais un terme de pénalité
C’est tout.
Les hyperparamètres sont ajoutés (c’est la vraie différence)
Pour la régression linéaire, nous n’avons pas le contrôle de la « complexité » du modèle.
- Régression linéaire standard : pas d’hyperparamètre
- Crête: un hyperparamètre (lambda)
- Lasso: un hyperparamètre (lambda)
- Filet élastique : deux hyperparamètres
- un pour la force globale de régularisation
- un pour équilibrer L1 vs L2
Donc:
- la régression linéaire standard n’a pas besoin d’être ajustée
- les régressions pénalisées le font
C’est pourquoi la régression linéaire standard est souvent considérée comme « pas vraiment du Machine Learning », alors que les versions régularisées le sont clairement.
Implémentation de gradients régularisés
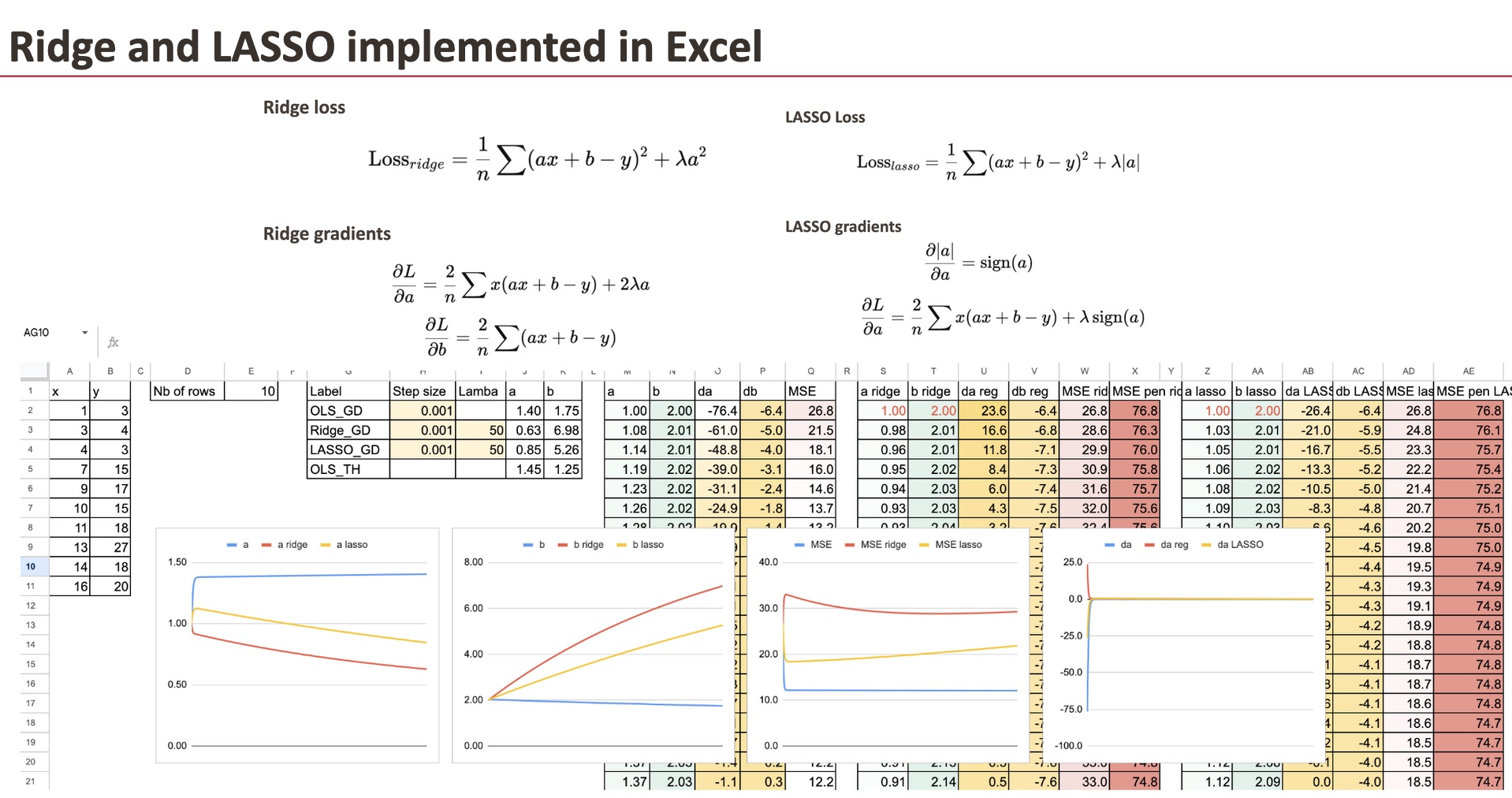
Nous gardons la descente de gradient de la régression OLS comme référence, et pour la régression Ridge, il suffit d’ajouter le terme de régularisation du coefficient.
Nous utiliserons un ensemble de données simple que j’ai généré (le même que celui que nous avons déjà utilisé pour la régression linéaire).
On voit que les 3 « modèles » diffèrent en termes de coefficients. Et le but de ce chapitre est d’implémenter le gradient pour tous les modèles et de les comparer.

Crête à pente pénalisée
Premièrement, nous pouvons le faire pour Ridge, et il suffit de changer le gradient de a.
Maintenant, cela ne signifie pas que la valeur b n’est pas modifiée, puisque le gradient de b à chaque étape dépend également de a.

LASSO avec dégradé pénalisé
Ensuite, nous pouvons faire la même chose pour LASSO.
Et la seule différence est aussi le gradient de a.
Pour chaque modèle, nous pouvons également calculer le MSE et le MSE régularisé. Il est assez satisfaisant de voir comment ils diminuent au fil des itérations.

Comparaison des coefficients
Nous pouvons maintenant visualiser le coefficient a pour les trois modèles. Afin de voir les différences, nous saisissons de très grands lambdas.

Impact de lambda
Pour une grande valeur de lambda, nous verrons que le coefficient a devient petit.
Et si lambda LASSO devient extrêmement grande, alors nous obtenons théoriquement la valeur 0 pour a. Numériquement, nous devons améliorer la descente de gradient.

Régression logistique régularisée ?
Nous avons vu la régression logistique hier, et une question que nous pouvons nous poser est de savoir si elle peut également être régularisée. Si oui, comment s’appellent-ils ?
La réponse est bien sûr oui, la régression logistique peut être régularisée
Exactement la même idée s’applique.
La régression logistique peut également être :
- L1 pénalisée
- L2 pénalisée
- Filet Élastique pénalisé
Il y a pas de noms spéciaux comme « Ridge Logistic Regression » dans l’usage courant.
Pourquoi?
Car le concept n’est plus nouveau.
En pratique, les bibliothèques comme scikit-learn vous permettent simplement de spécifier :
- la fonction de perte
- le type de pénalité
- la force de régularisation
Le nom importait lorsque l’idée était nouvelle.
Désormais, la régularisation n’est plus qu’une option standard.
Autres questions que nous pouvons poser :
- La régularisation est-elle toujours utile ?
- Quel est l’impact de la mise à l’échelle des caractéristiques sur les performances de la régression linéaire régularisée ?
Conclusion
Ridge et Lasso ne modifient pas le modèle linéaire lui-même, ils modifient la façon dont les coefficients sont appris. En ajoutant une pénalité, la régularisation favorise des solutions stables et significatives, notamment lorsque les fonctionnalités sont corrélées. Voir ce processus étape par étape dans Excel montre clairement que ces méthodes ne sont pas plus complexes, mais simplement plus contrôlées.


