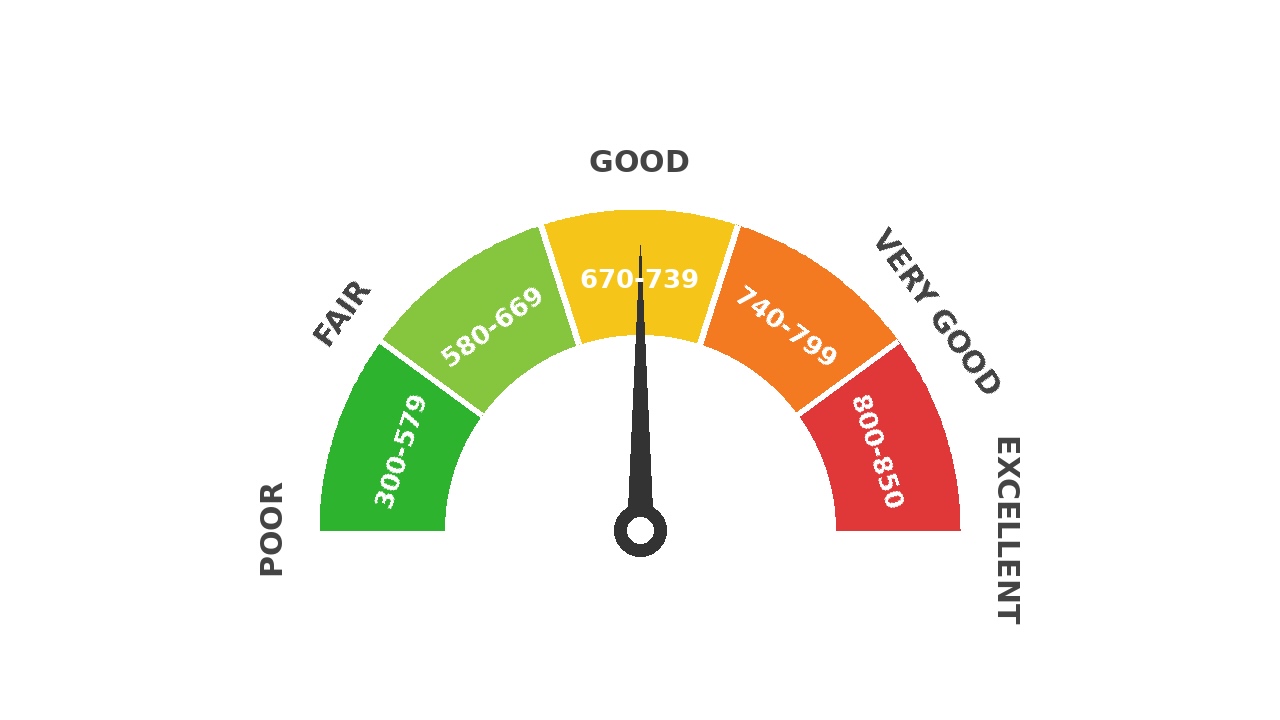
Introduction une variable continue pour quatre produits différents. Le pipeline d’apprentissage automatique a été construit dans Databricks et comporte deux composants principaux. Préparation des fonctionnalités en SQL avec calcul sans serveur. Inférence sur un ensemble de plusieurs centaines de modèles …